萬相 2.1 (Wan 2.1) 為阿里巴巴研發的開源影片生成模型,2025年2月釋出,提供文字生成影片、圖片生成影片、在影片中生成文字的功能。
圖片生成影片,就是讓一張靜態圖片動起來。
聽說Wan 2.1的品質比騰訊的混元(HunYuan)模型要來得好呢。Reddit r/stablediffusion有人說這是另一個Stable Diffusion 1.5時代的開始,雖然常常會有詭異結果可是已經充分展示潛力。
提供以下版本:
- Wan2.1-T2V-14B:文字生成影片,支援480p與720P
- Wan2.1-I2V-14B-720P:從圖片生成影片,支援720P
- Wan2.1-I2V-14B-480P:從圖片生成影片,支援480P
- Wan2.1-T2V-1.3B:文字生成影片,最快速的模型。訓練資料量較少,品質可能不好。
不論是Github還是Civitai上面發表的,主流的Wan 2.1 ComfyUI工作流普遍需要8GB VRAM才能跑。用RTX 3060或者更高等級的GPU跑Wan2.1-I2V-14B-720P模型,搭配TeaCache,一小時內就能生成5秒影片。
有作者將其修改為4GB VRAM就能跑,他是做給RTX 3050 (4GB)使用的,策略是載入GGUF格式的Wan 2.1模型降低VRAM佔用,再搭配Tiled KSampler與Tiled VAE節點,用空間換取時間。雖然生成速度比較慢,但是起碼能跑,而不會直接OOM。720P模型建議不要用,得用480P模型。生成低畫質影片之後再用其他技術將影片放大+補幀,也能得到不錯效果的影片。
1. 安裝Wan 2.1 Low VRAM工作流#
註解:這個工作流稍做修改後,也能載入Wan 2.2的模型。
安裝ComfyUI
到Simple Wan 2.1 Low vram Comfy UI Workflow (GGUF) 4gb Vram + 16gb ram,登入Civitai帳號,點選Download下載工作流,解壓縮將.png圖片拖到ComfyUI視窗,匯入工作流。這個工作流支援文字生成影片和圖片生成影片的模型。
匯入後,使用ComfyUI Manager安裝自訂節點。
到HuggingFace儲存庫下載
wan2.1-i2v-14b-480p-q5_k_m.gguf與wan2.1-t2v-14b-q5_k_m.gguf與wan2.1_t2v_1.3b-q5_0.gguf模型,放到/models/diffusion_models/目錄。然後到另外一個HuggingFace儲存庫下載。將
clip_vision_h.safetensors放到/models/clip_vision/目錄。將umt5_xxl_fp8_e4m3fn_scaled.safetensors放到/models/text_encoders/目錄。最後將wan_2.1_vae.safetensors放到/models/vae/目錄如果需要使用LoRA,到Civitai尋找支援"Wan Video"的版本,並確認是給T2V還是I2V用的,然後下載到
/models/loras/。
2. 生成影片的參數#
先拆解一下工作流內容,由左至右。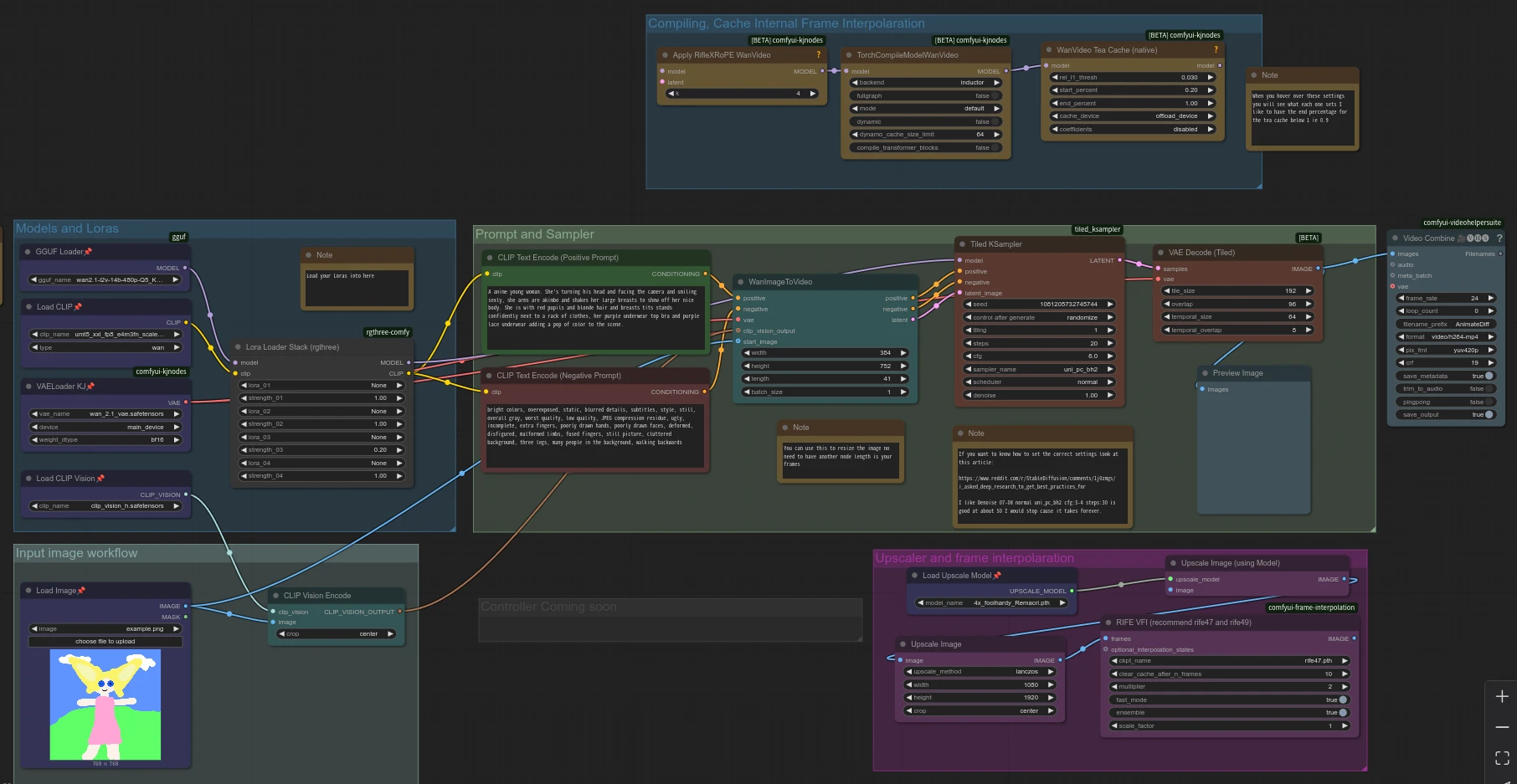
Models & Lora這一塊是載入模型的,圖片生成影片的GGUF模型應該選取wan2.1-i2v-14b-480p-q5_k_m.gguf,反之文字生成影片的GGUF模型就是wan2.1-t2v-14b-q5_k_m.gguf了。
LoRA是專用小模型,不一定要使用。比起提示詞,能讓生成的影片更接近想要的內容。但是這個工作流在4GB VRAM就很吃緊了,加入LoRA會更容易OOM?
Input image workflow要上傳的是參考圖片,適用圖片生成影片模式,最好跟WanImageToVideo節點的寬高一樣。如果要使用文字生成影片的模型,則把WanImageToVideo節點的clip_vision_output和start_image截斷。
看一下Prompt and Sampler這一塊:
CLIP Text Encode就是提示詞,儘量描述想要的影片內容,包括人物還有背景樣貌。
CLIP Text Encode (Negative)負向提示詞,不要生成什麼。負向提示詞用英文或中文寫都可以,不過「圖畫」的提示詞好像會一併阻止生成動漫圖像,把它去掉。
Tiled KSampler取樣器維持預設,步數至少20才有好品質。圖片生成影片的denoise數值維持1.0才能忠實的依照原圖生成影片。若是文字生成影片,降低能增加影片隨機度。
WanImageToVideo決定生成影片寬高。length即影片長度,應該是影片幀數的數量。用Wan 2.1 14B的模型,數字設定41幀以上(約2秒)才不會有VAE的殘影。可是一旦超過41,就會佔用超過4GB VRAM導致OOM。用Wan 1.3B模型的影片可以再長一些,但最多也就53幀。
要生成更長影片,直接調整影片長度會爆VRAM,需要用接力的,也就是生成影片後,依照最後一幀繼續生成。種子碼固定的情況下,應該能延續影片內容。這個工作流的作者沒有製作接力節點。另外一種方法是用kijai/ComfyUI-WanVideoWrapper自訂節點來延長影片,裡面有一個Context Window的功能,可以提升一次生成的影片長度,就不需要用接力的了。
最後是我認為不那麼重要的部份:
Comling, Cache Internal Frame Interpolation,內含KJNodes這一塊,是計算快取之用的,透過TeaCache,能夠提昇生成影片的速度達五倍以上。
Turing架構以前的舊Nvidia顯示卡沒辦法使用Triton GPU Compiler,會出現RuntimeError: Found NVIDIA ...... which is too old to be supported by the triton GPU compiler, which is used as the backend. Triton only supports devices of CUDA Capability >= 7.0, but your device is of CUDA capability 6.1錯誤。
得手動在ComfyUI目錄的execution.py裡面加入程式碼import torch._dynamo torch._dynamo.config.suppress_errors = True無視錯誤訊息硬跑,但就沒有加速效果了。
若是不需要,像我一樣把圖中的節點截斷了。
Upscaler and Frame Interpolation即影片放大與補幀這一塊,是在生成影片之後處理的,因為這個工作流只能生成480P影片,生成影片後再放大,並用RIFE補幀會比較好看。但我認為要快速看到影片效果,這一塊可以先去掉,節省時間。所以圖中的節點被我截斷了。
3. 生成結果#
我實際操作下來,在Nvidia GTX 1050Ti (4GB VRAM) + 16GB RAM,不使用TeaCache,使用Wan2.1-I2V-14B-480P模型最多可以生成2秒的影片,耗時6小時。
即使是最快的Wan2.1-T2V-1.3B,2秒的影片也要生成1小時。
之所以會這麼久是因為我的顯示卡太舊,不支援TeaCache。
Wan2.1-T2V-14B-480P文字生成影片範例,2秒。
Wan2.1-I2V-14B-480P圖片生成影片範例,分別生成三部影片然後拼起來,約6秒。為方便觀察,速度有放慢。到後面畫風整個崩掉。

