Karakeep(舊稱Hoarder),一款收集你的想法的好所在。
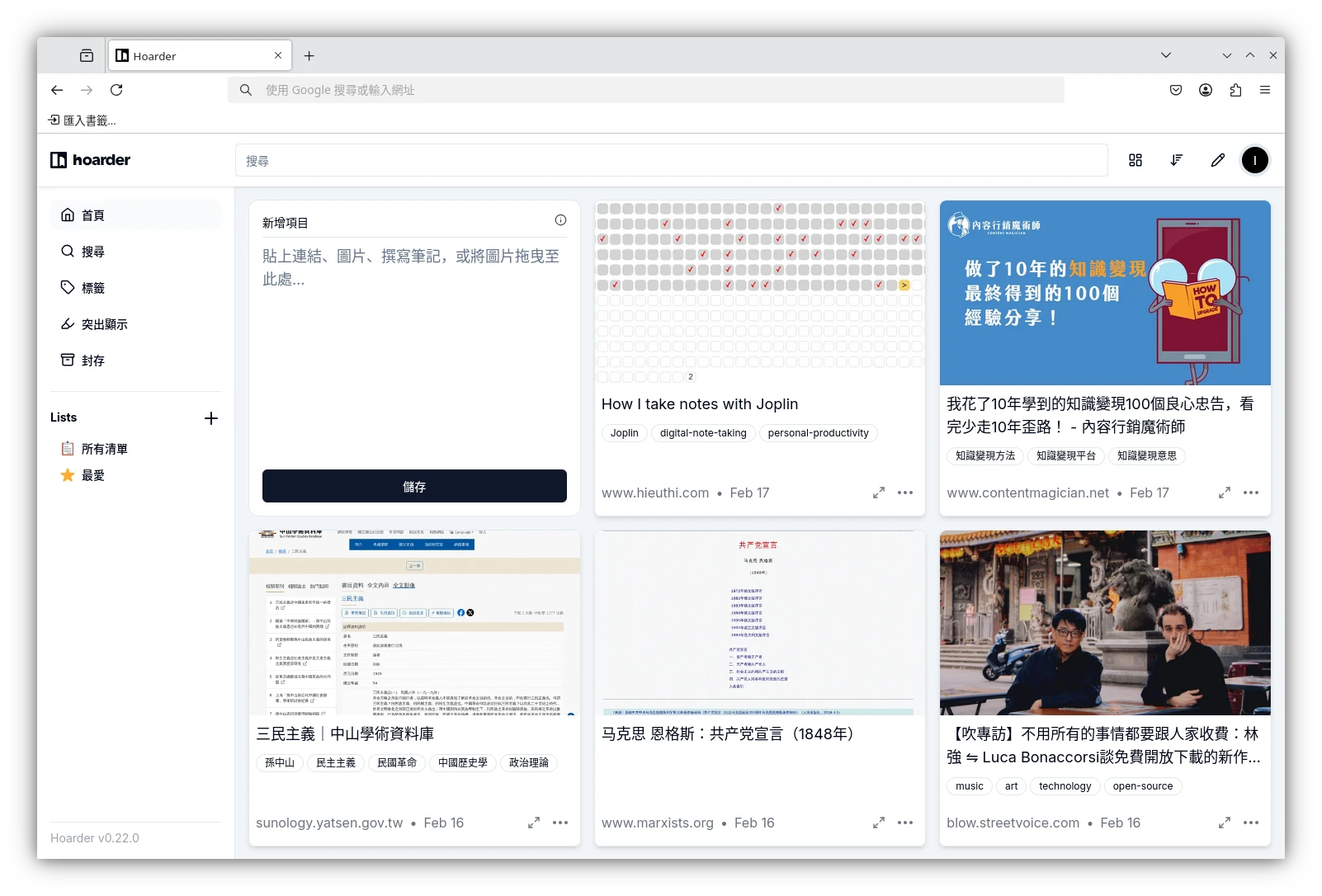
Karakeep是由Mohamed Bassem開發的自由軟體服務,專門用於蒐集書籤之用。
瀏覽器多半有提供書籤功能,人們會將之後要看的網頁放到書籤裡面蒐集起來。不過時間久了,書籤就會瘋狂膨脹,之後就會累積了一堆不知道哪來的東西。到頭來那些蒐集的書籤,也不過是在收藏夾裡面吃灰而已!
使用Karakeep書籤管理軟體,至少它能夠幫我們用AI分類一下,自動打標籤,並允許我們在上面劃記,寫下臨時想到的靈光隨想。日後也能夠透過完善的全文搜尋功能找到某某日子存下來的書籤。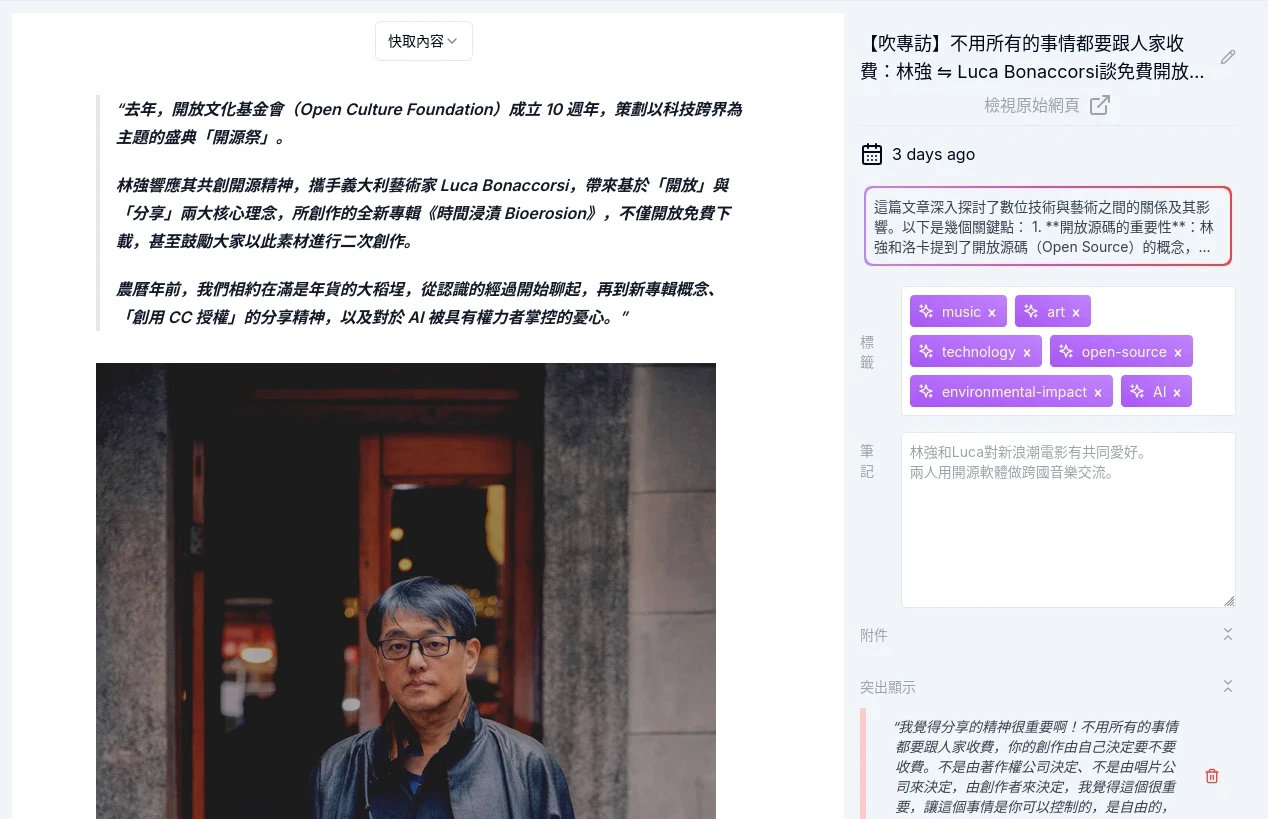
Karakeep自稱是"A self-hostable bookmark-everything app",不單單只是一個書籤管理器,還有以下功能:
- 將臨時看到的網頁或者有趣圖片丟上去自動整理
- 給書籤網頁劃上底線,紀錄頁面重點
- 透過AI自動給書籤上標籤,總結文章內容,後端可以是ChatGPT或Ollama
- 提供類似Internet Archive的功能,將網頁快照拍下來,防止網站消失
- OCR,將上傳的圖片文字抽取出來,以便日後搜尋。
- 可以訂閱RSS,將文章自動匯入並上標籤
- 支援匯入其他瀏覽器的HTML書籤
- 提供瀏覽器擴充套件,還有Android與iOS的APP
1. Karakeep與類似服務比較#
Karakeep需要部署到自己的伺服器,得全程自架。伺服端和客戶端都是完全開源的專案。
有一款類似的書籤管理軟體叫做Raindrop.io,他們只有APP開源,服務本身是沒辦法自架的。
Karakeep很類似Firefox的Pocket服務,不過功能更多。
RSS用戶可能會問為什麼還要書籤管理軟體?Well…這個界面比較漂亮。Karakeep除了抓取精簡過的文字版網頁之外,還可以把網頁拍一份快照,完整保存下來。
作者比較側重的功能是封存方面的用途,像是蒐藏「稍後閱讀」和「臨時想法」的地方。這就是Karakeep舊版名稱Hoarder這個字的本意,意為「囤積」,或者可以理解為倉鼠症。
Karakeep不適合放常常開啟來用的工具類網站,而是適合封存網路文章。
因為Karakeep沒有資料夾,只有清單列表,如果要系統性的整理蒐集到的資訊,建議還是用知識管理系統軟體來整理。
2. 架設Karakeep服務#
我們使用docker-compose來部署。
在Linux安裝Docker
取得Karakeep官方的docker-compose。這裡會跑三個服務:Karakeep本體、爬蟲用的Chrome瀏覽器、MeiliSearch全文搜尋引擎。
mkdir karakeep-app
cd karakeep-app
wget https://raw.githubusercontent.com/karakeep-app/karakeep/main/docker/docker-compose.yml
- 編輯
.env檔案,設定環境變數
vim .env
- 首先是祕密金鑰,可以用
openssl rand -base64 36指令產生。
KARAKEEP_VERSION=release
NEXTAUTH_SECRET=隨機產生
MEILI_MASTER_KEY=隨機產生
NEXTAUTH_URL=http://localhost:300 # 對外公開網址
- 接著是爬取網頁的設定,這裡我設定Karakeep的瀏覽器在爬取的時候需要捲動頁面,抓取完整網頁,而不是只有第一頁。
CRAWLER_STORE_SCREENSHOT=true
CRAWLER_FULL_PAGE_SCREENSHOT=true
CRAWLER_FULL_PAGE_ARCHIVE=true
- (選擇性)啟用語言模型服務,讓AI能夠從書籤收藏的文章自動上標籤。我使用Ollama的本機語言服務,模型請一律用Ollama的界面下載。要總結文章內容並生成中文標籤,使用資料量3B的模型應該就夠了。
OLLAMA_BASE_URL=http://localhost:11434 # Ollama服務IP位址
INFERENCE_TEXT_MODEL=qwen2.5:3b # 要使用的模型
INFERENCE_IMAGE_MODEL=llava-phi3:latest # 要使用的圖像辨識模型
EMBEDDING_TEXT_MODEL=mxbai-embed-large:latest # 嵌入文字模型
INFERENCE_CONTEXT_LENGTH=2048 # 上下文長度
INFERENCE_LANG=Traditional Chinese # 輸出的語言
- 最後,啟用OCR服務,設定Tesseract語言為中文和英文。
OCR_LANGS=chi_tra,chi_sim,eng
- 啟動Karakeep容器服務
docker compose up -d
開啟瀏覽器網頁
http://Linux電腦IP:3000,註冊一個帳號,登入Karakeep。設定外網連線到內網的方案。
3. Karakeep網頁版的操作#
首頁可以放入網址或者圖片。大約等個幾秒後,語言模型就會自動上好標籤。
點縮圖會進入原本網址,按旁邊的放大鍵展開閱讀界面。
這個界面可以編輯標籤,並且下自己的註解
Karakeep預設是快取的文字,方便閱讀但不保留原始排版。圈選文字並按右鍵,就可以劃上記號。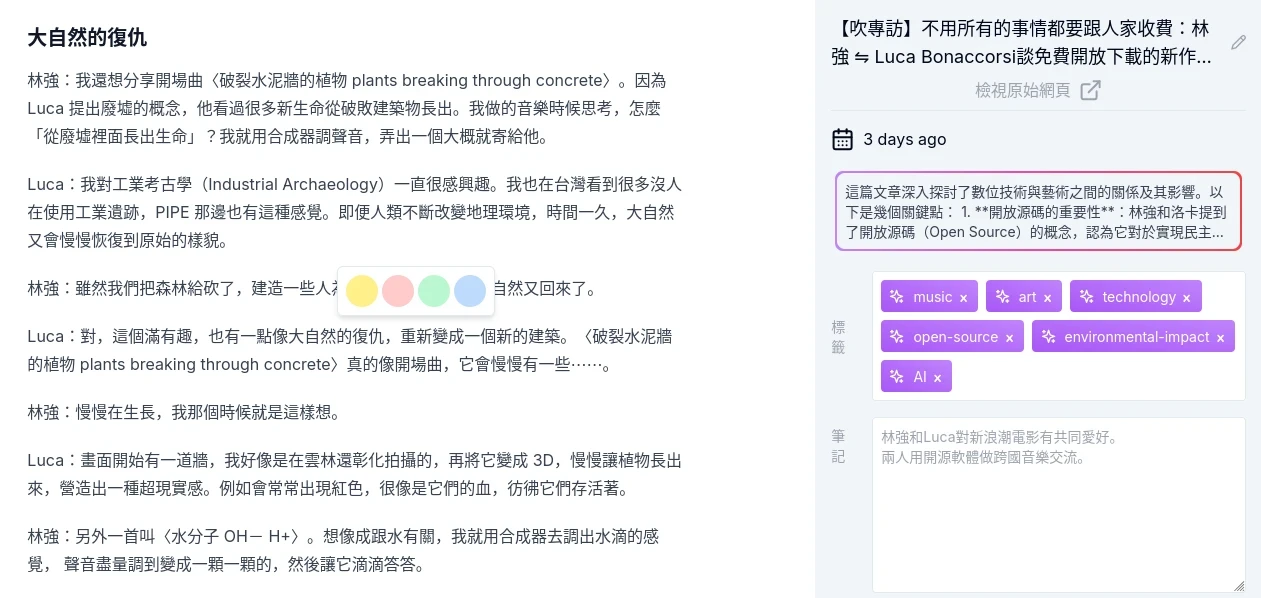
切換到截圖頁面就會看到Karakeep瀏覽器所拍下的畫面,有助於保留網頁當下的狀態。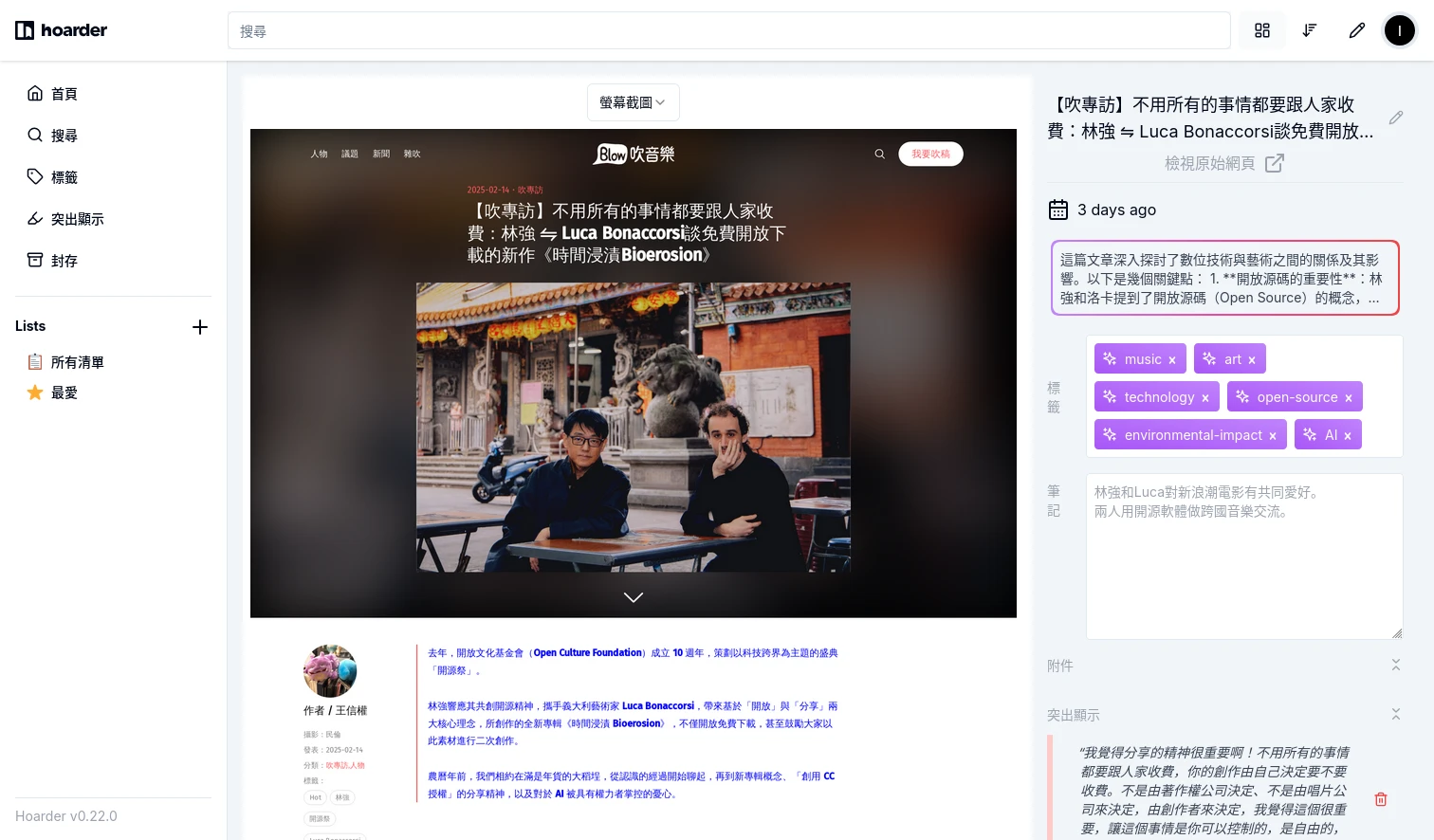
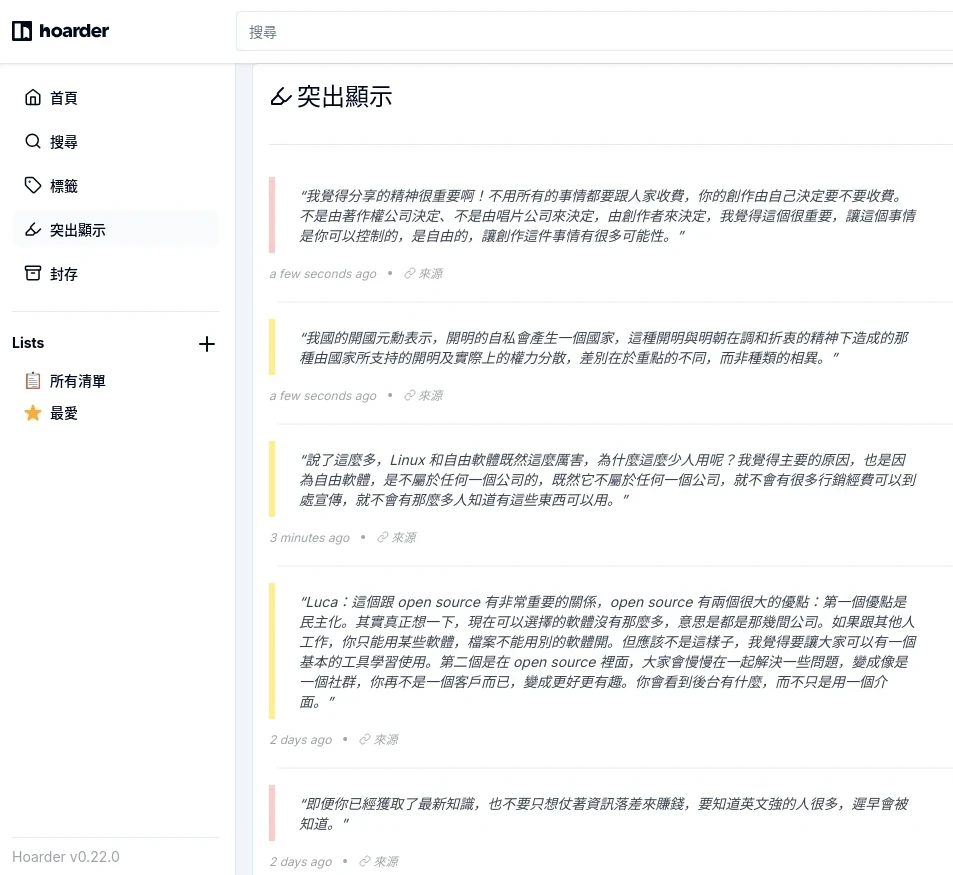
關於Karakeep的搜尋頁面,搜尋範圍應該是包含快取的文章內容,還有OCR辨識的圖片。不過我實測中文搜尋似乎不如英文要精準。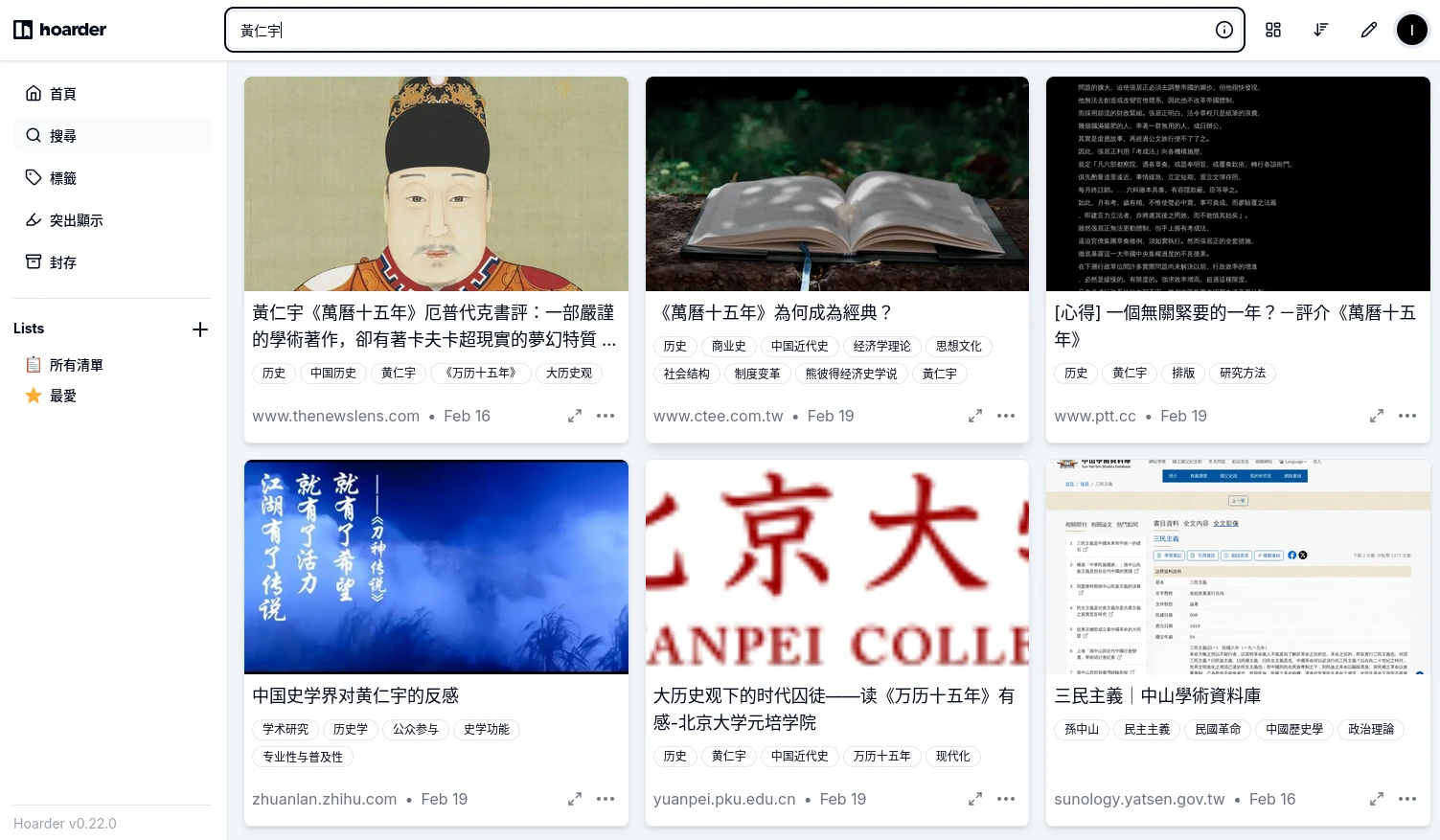
4. Karakeep輔助APP#
Karakeep有瀏覽器擴充功能
設定好帳號密碼登入之後,點開Karakeep的瀏覽器擴充套件,它就會自動將目前頁面加入書籤,並用AI打上標籤。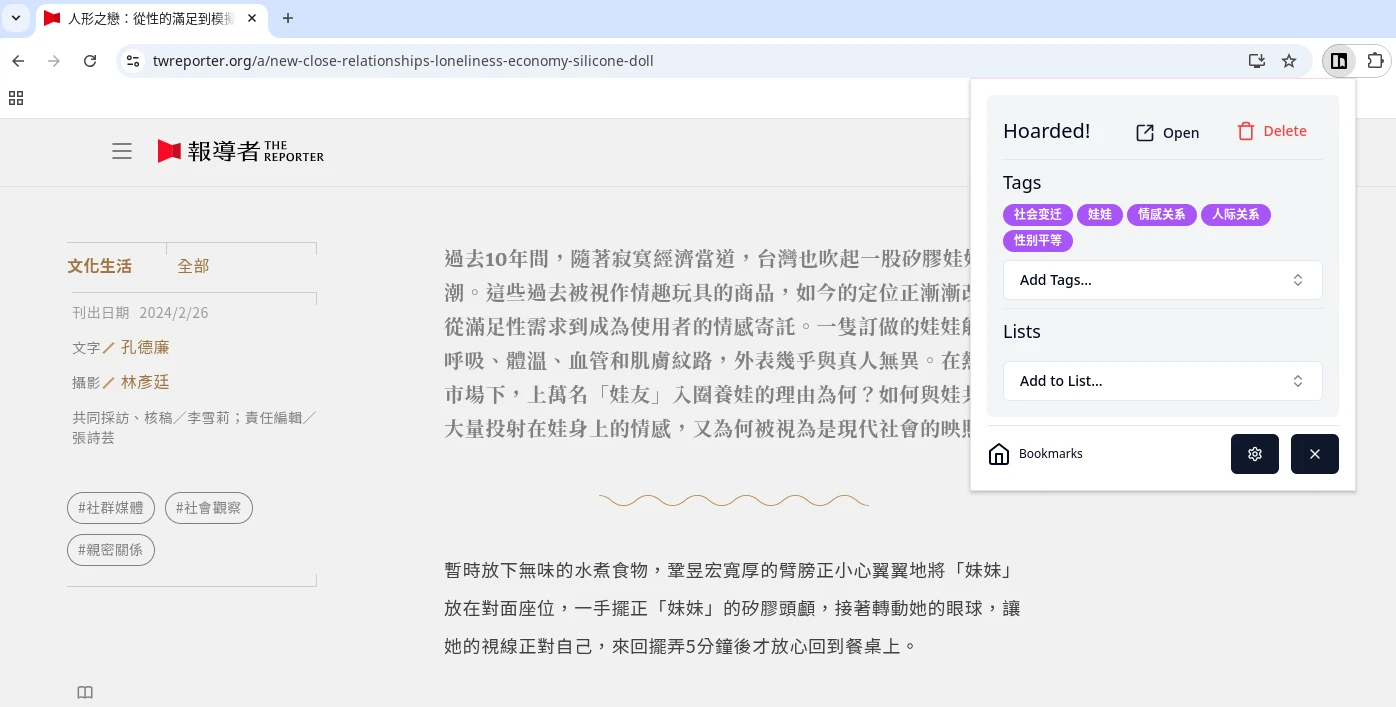
Karakeep也有提供手機版APP:Android|iOS
操作方法類似網頁版,但沒有劃線功能。