本文討論如何安裝Ollama主程式。Ollama支援Linux、macOS、Windows系統。
1. Ollama系統需求#
作業系統:Windows 10以上、Ubuntu 24.04以上、macOS Sonoma以上
硬體部份,視你要跑的模型大小,會有不同的需求。若以7B左右資料量的模型來看,建議電腦至少CPU Intel i5 4核心,且RAM 8GB以上再使用Ollama。因為Ollama基於llama.cpp開發,跑的是經過量化縮減的GGUF格式語言模型,所以不需要獨立顯卡也能跑。
不過有獨立顯卡更好,可以將一些模型層丟給GPU加速運算,提昇5倍以上的推理速度。若要使用GPU加速的話,推薦使用Nvidia顯卡,且GPU的VRAM至少要有4GB以上。Ollama會自動根據你的VRAM分配任務。
2. 安裝Ollama主程式#
Windows#
Windows版本的Ollama提供一個簡單的圖形界面,讓使用者與模型對話。另外也可以在終端機裡面執行ollama指令對話。
Ollama的模型預設是用CPU算的。如果要使用Nvidia GPU加速,請記得安裝最新版Nvidia驅動,並安裝CUDA Toolkit。Ollama啟動後會自動偵測並切換到GPU。
到Ollama官網下載.msi安裝檔,安裝Ollama
開啟Ollama程式,選取一個模型,下載後即可聊天。Windows下載的模型檔案會儲存到
C:\Users\使用者名稱\AppData\Local\Programs\Ollama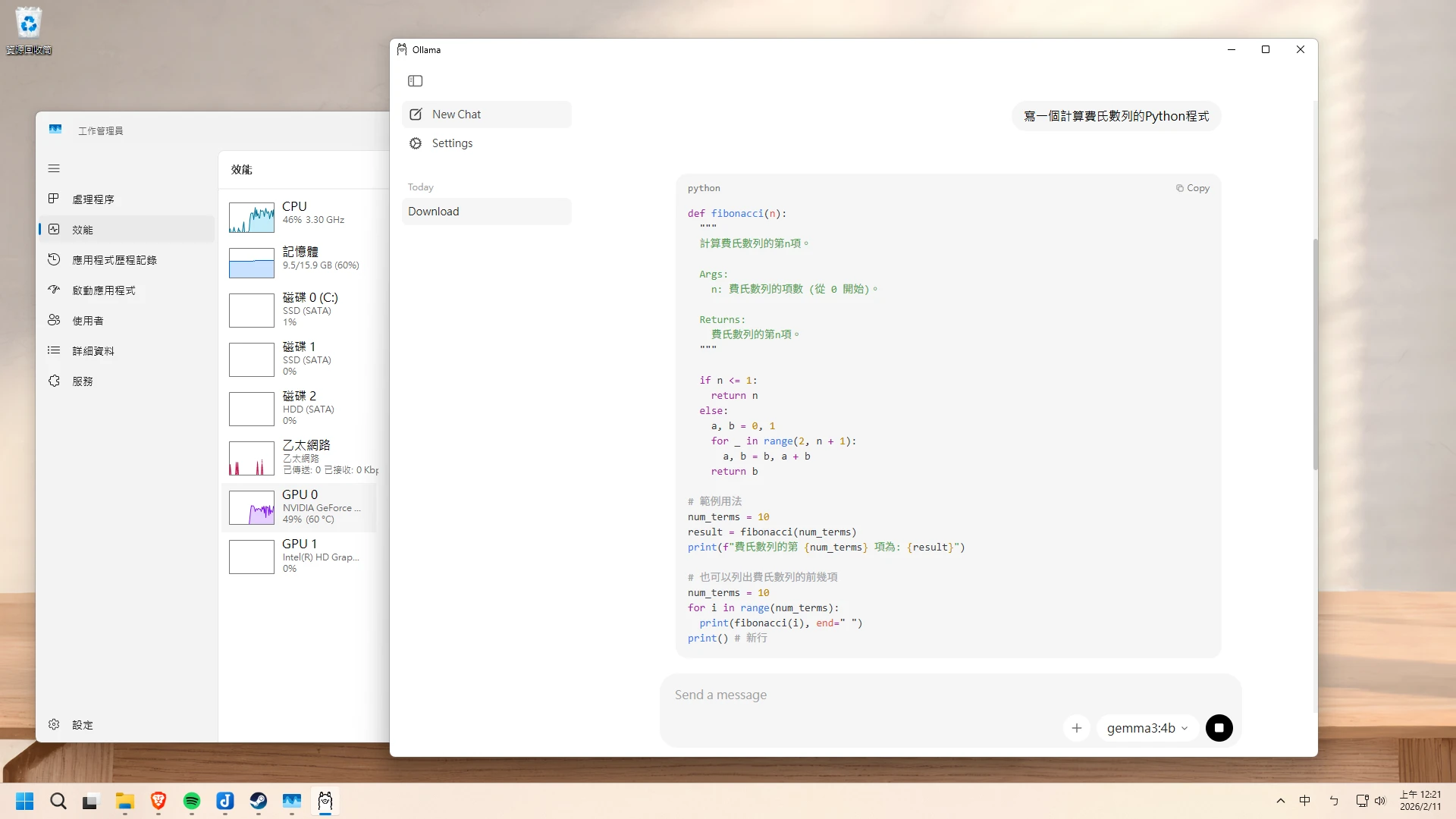
Ollama的服務會在開機自動啟動,這點可以從工作管理員看到。
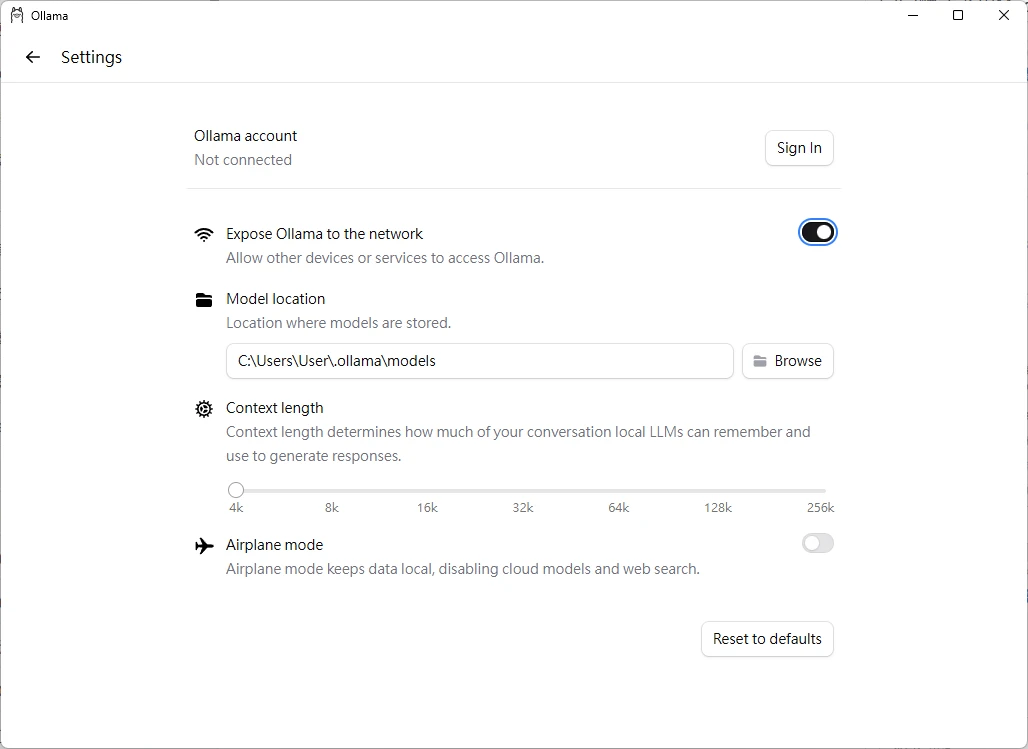
如果要使用API模式,讓其他程式透過網路存取Ollama模型,需要在設定裡面勾選Expose Ollama to Network。
如果要用指令操作,請開啟Windows終端機,輸入
ollama指令即可。
Linux#
Linux版的Ollama沒有圖形界面,要用指令操作。使用者需要自行找個前端來用。
- 使用官網提供的指令稿安裝。例如我的系統為Ubuntu,它應該會自動偵測架構(x86_64或ARM64),並設定好Systemd服務。
curl -fsSL https://ollama.com/install.sh | shOllama的模型預設是用CPU算的。如果要使用Nvidia GPU加速,請記得安裝Nvidia閉源驅動和CUDA。Ollama啟動後會自動偵測並切換到GPU。
確認Ollama服務執行狀況
sudo systemctl status ollama- 如果你要設定Ollama的環境變數,調整模型的參數等等,作者建議你直接改Systemd Unit檔案:
sudo vim /etc/systemd/system/ollama.service
sudo systemctl daemon-reload- 在Linux,下載的模型檔案會儲存到
~/.ollama/models或/usr/share/ollama/.ollama/models/
macOS#
macOS版本的Ollama提供一個簡單的圖形界面,讓使用者與模型對話,也可以在終端機裡面使用ollama指令。
到Ollama官網下載.dmg,安裝即可使用。
下載的模型會儲存到~/.ollama/models。
3. 下載語言模型#
現在網路有很多開源的大型語言模型。
Ollama預設是從自家的官網下載模型,你可以到上面看看有什麼熱門模型,大部分都是GGUF格式的。
下載模型前要自行評估你的硬體是否跑得動。對於大部分電腦來說,可以從7B資料量的開始試起。例如Google在2025年最新發表的「Gemma 3N」,支援中文。
使用Ollama圖形界面,選取一個模型下載: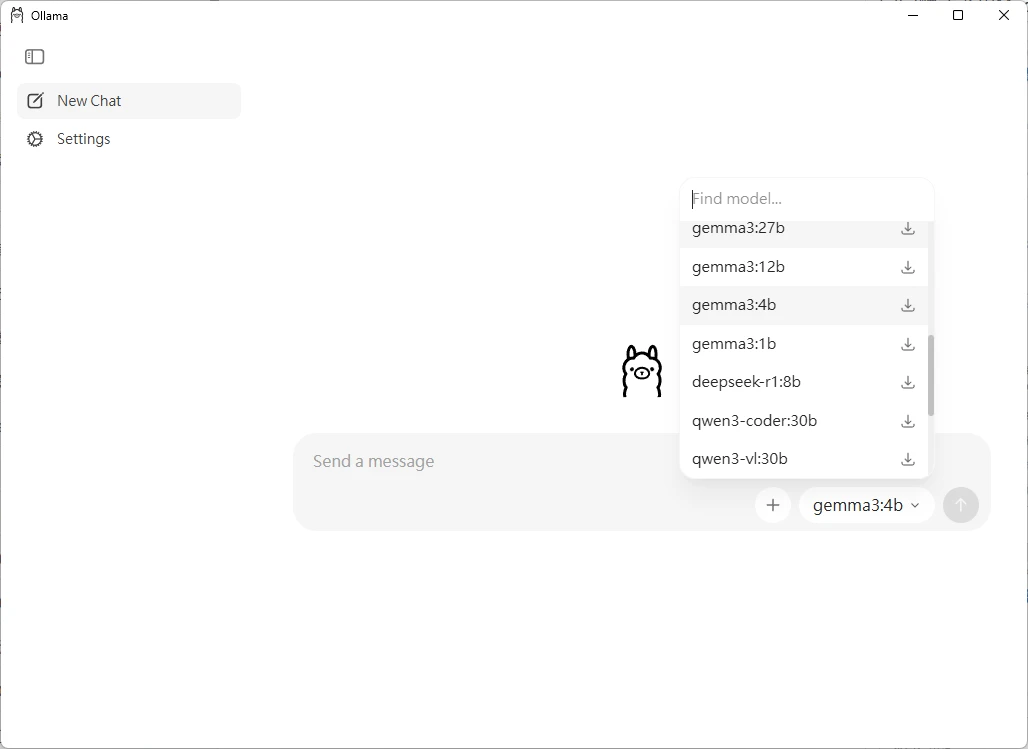
或者執行ollama pull指令下載語言模型:
ollama pull gemma3n:e4b4. Ollama命令行操作#
雖然Ollama有提供圖形界面,不過要管理模型我認為還是用終端機指令比較方便。
- 輸入
ollama run指令載入模型,後面加上模型名稱。加上--verbose的話可以測試模型回覆的速度。
ollama run gemma3n:e4b等待載入完成,開始跟語言模型對話吧。
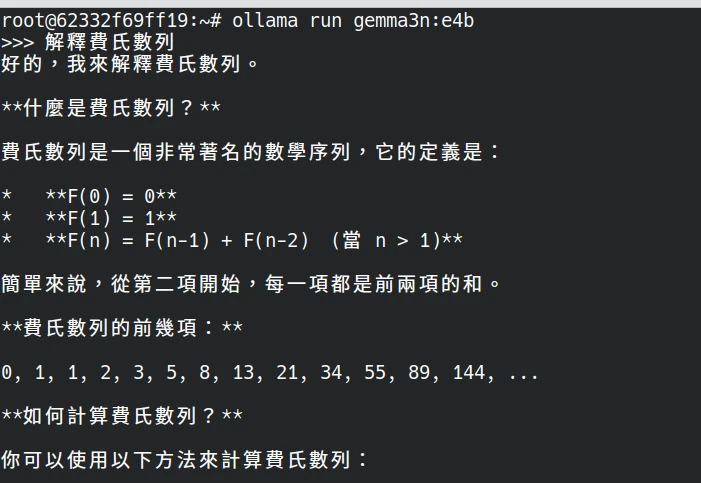
如果要輸入多行指令,使用
""" """把提示詞框起來。你也可以傳圖檔給它辨識(需使用LLaVA模型):
What is in this image? "/home/user/Downloads/smile.png"- Ollama設計的對話程式可以用指令
/save保留工作階段(session),也就是讓AI記住之前的聊天內容。
# 保存目前的聊天內容
/save session1
# 載入上次的聊天內容
/load session1- 你還可以調整目前模型的參數,例如修改token、將一部分offload給GPU加快運算、Temperature、Repetition penalty等。
/set parameter num_ctx 4096
/set parameter num_gpu 10- 使用
ollama ps指令可以確認目前模型是跑在CPU還是GPU上。
6. 將其他程式與Ollama串接#
你可以視需求安裝其他軟體,增強Ollama的威力。
Ollama本身提供API模式,可以開放給其他程式串接。通常是透過http://localhost:11434連線。
你用瀏覽器開啟http://localhost:11434這個網址,看到Ollama is running就代表程式已經準備好讓其他程式連線了!
這裡簡單推薦一個:Open WebUI(舊稱Ollama WebUI)是專為各種語言模型服務設計的網頁界面,同樣高度模組化,可以搭配Ollama或ChatGPT使用。它能把Ollama的一些指令操作圖形化,例如管理模型、提示詞、要處理的文件等等。
推薦使用Docker部署,過程請參考用docker-compose部署Open WebUI + Ollama