Generating subtitles automatically for videos using Kdenlive + Whisper.
剪輯影片上字幕是一件累人的事情,好在現在有很多語音轉文字(speech to text)軟體可以幫我們節省大量時間,自動偵測人聲,生成字幕檔,再加到影片。
開源影片剪輯軟體Kdenlive除了能給影片加字幕以外,其實也有內建語音轉文字,並自動生成srt和字幕軌的功能。使用完全免費。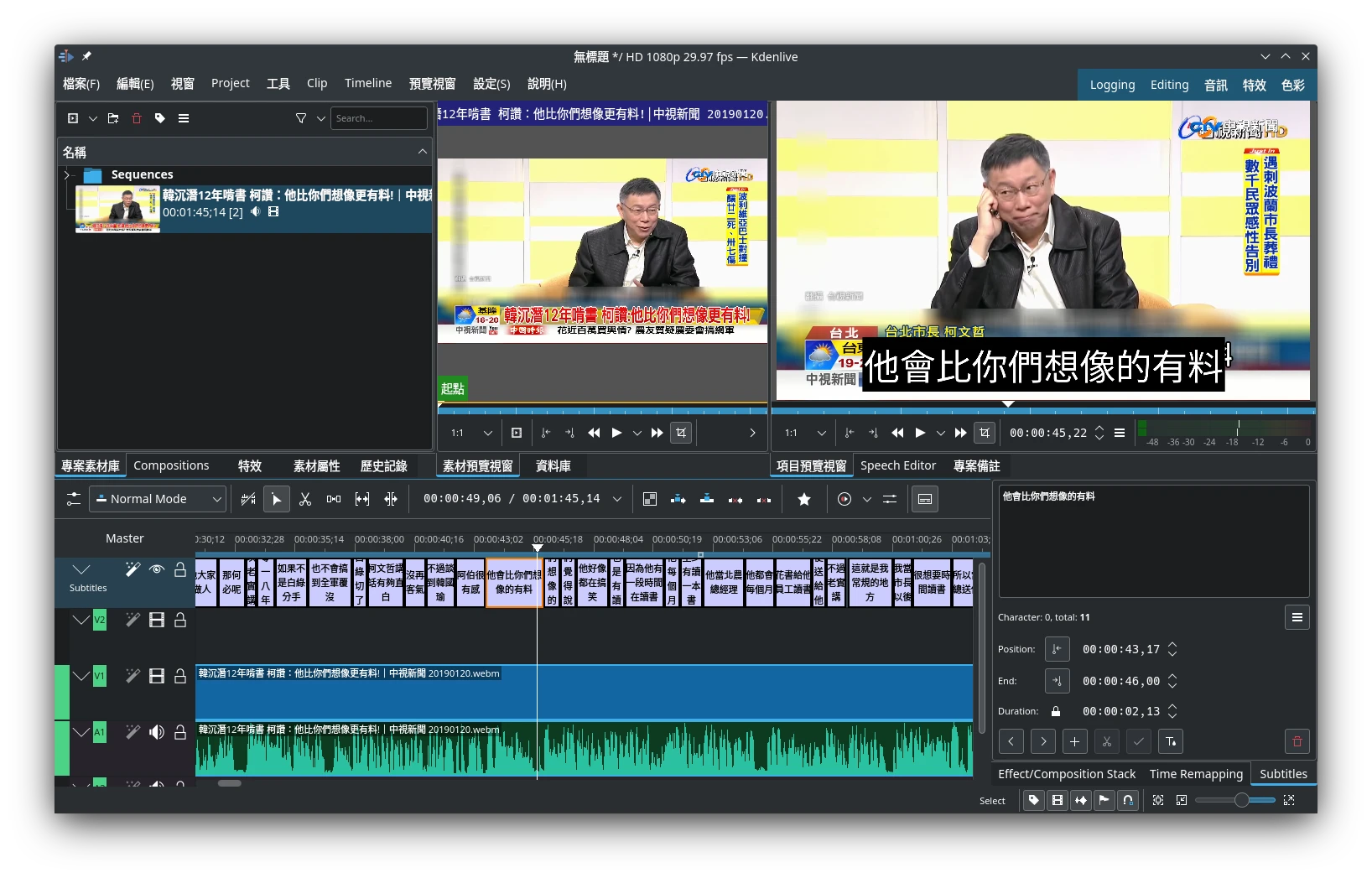
影片版教學
目前Kdenlive支援「VOSK」和「OpenAI Whisper」二種模型,本文我要講的是後者。Whisper的語音辨識十分優秀,很多軟體都使用了Whisper技術來生成逐字稿,現在Kdenlive也可以直接調用Whisper來生成字幕,於是乎你就擁有了開源的語音轉字幕+影片編輯解決方案。
我自己測試的結果是即使講話中英文夾雜,Whisper也能清楚的分辨出來,斷句準確。啊不過如果講話台灣國語太重可能就沒辦法XD
另外一個好處是,Whisper在語音辨識的時候不會連網,全部都是本機運算,保障你的隱私。
本文介紹如何使用Kdenlive搭配語音轉文字服務,讓你剪輯影片更為快速。
1. 安裝Python與語音轉文字套件#
需要Kdenlvie版本:25.08.3以上
語音轉文字技術Linux與Windows皆可使用,詳官方使用手冊:Speech to Text — Kdenlive Manual
開啟Kdenlive,點選上方設定 → 設定Kdenlive → 語音轉文字。點選「安裝多語言資料」,等待Python依賴套件與模型全部下載完成,大約會佔用10GB空間。
接著,語音引擎勾選使用
Whisper模型。接著下載Whisper的模型,Base是基礎模型,最低2GB VRAM就能跑,Turbo則是需要6GB VRAM。越大的模型越準確但也越吃效能,一不小心可能就會爆VRAM。裝置部份,如果你有Nvidia顯示卡就勾選Nvidia顯示卡,沒有的話就維持CPU計算,但是CPU計算很慢。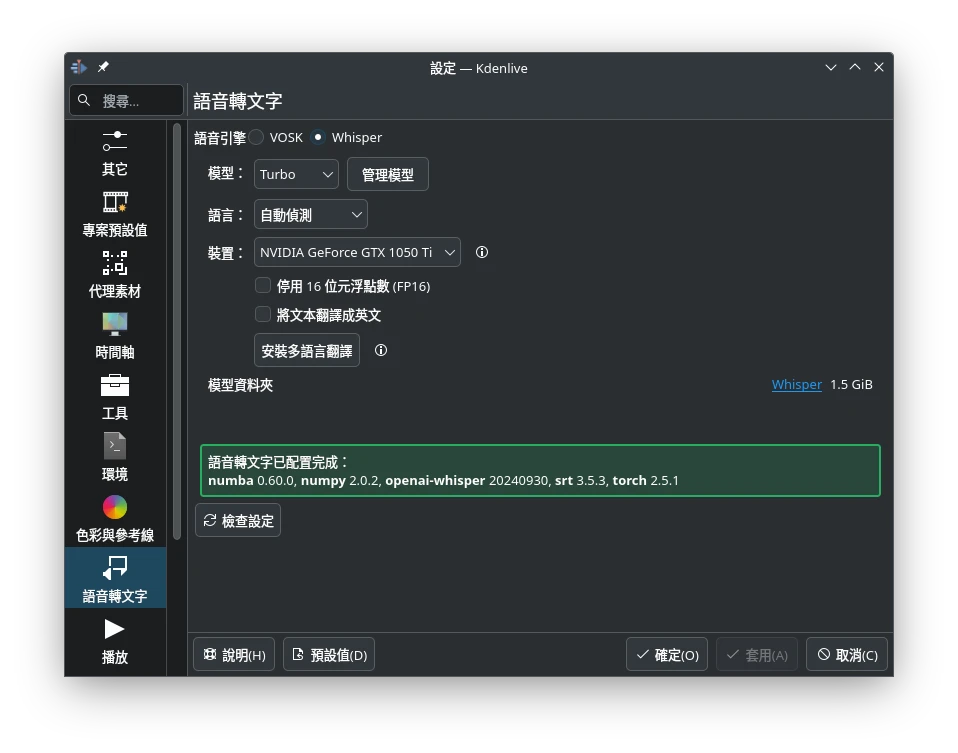
2. 自動語音轉字幕 (subtitle)#
這個功能可以偵測選定片段的語音,生成字幕軌。
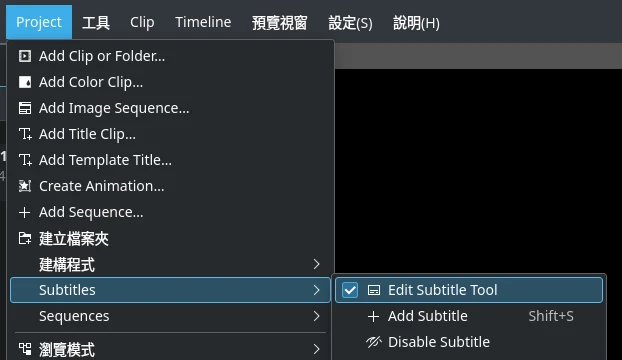
點選專案 → 字幕 → 啟用字幕工具,為專案啟用字幕軌
調整時間軸最上方的藍色橫條,畫出要語音辨識的片段

點選字幕軌左邊的魔術棒或者影片按鈕

語言設定自動偵測,每行最大字數建議不要設太高,免得字幕過於擁擠。點選開始生成字幕。
字幕會直接匯入到Kdenlive的軌道。如果生成的字幕不理想,建議改用更大的模型。
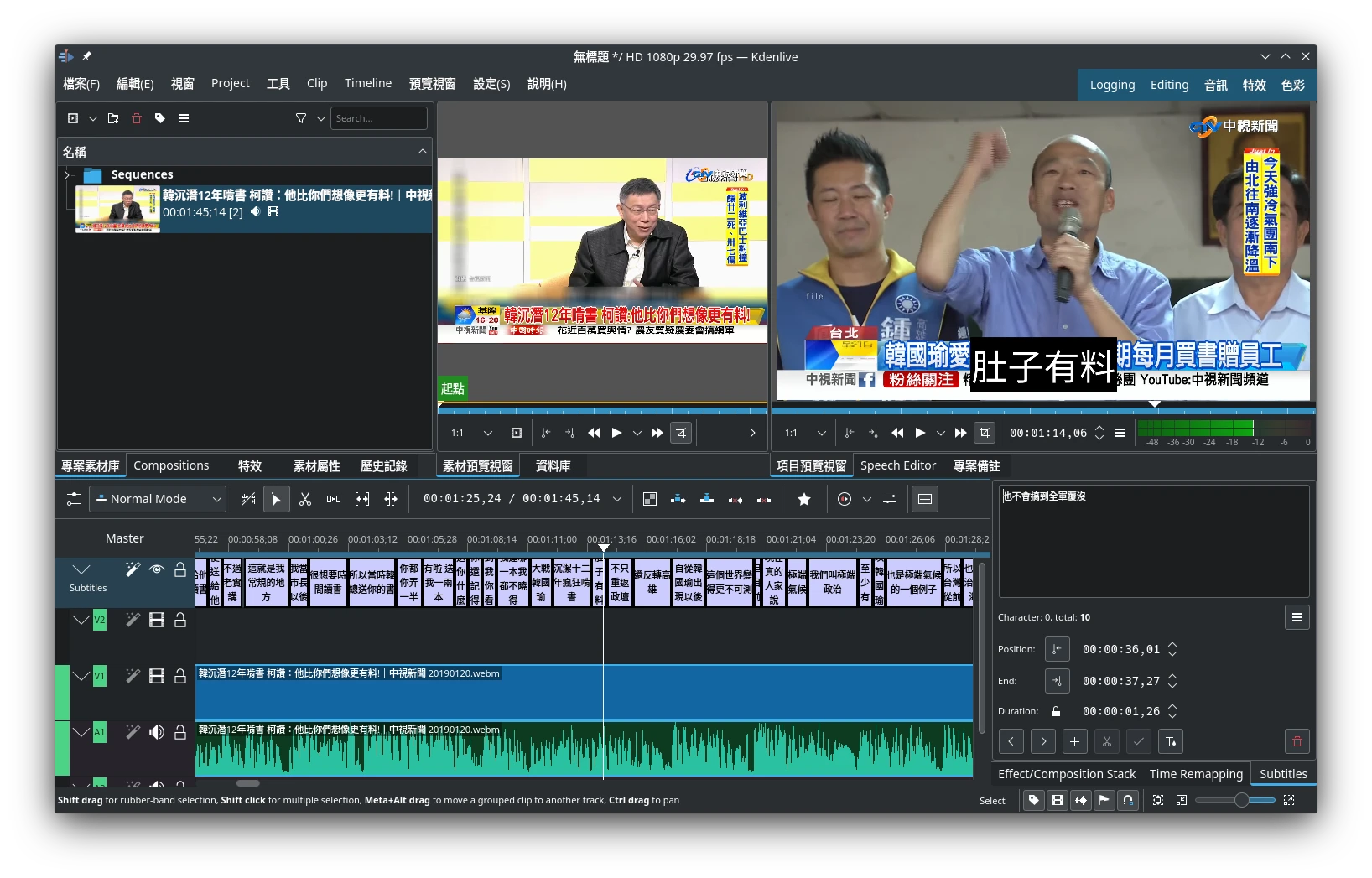
生成字幕後點選專案 → 字幕 → 匯出srt檔案。

3. 給影片生成逐字稿 (clips)#
這個功能可以給素材庫的影片個別生成逐字稿,作為剪輯參考之用。你還可以按照生成的內容,自動分割時間軸的影片片段,方便編輯特效。
點選視窗 → 啟用Speech Editor
選取專案的影片素材,再點選螢幕右邊的Speech Editor按鈕,點選開始語音辨識
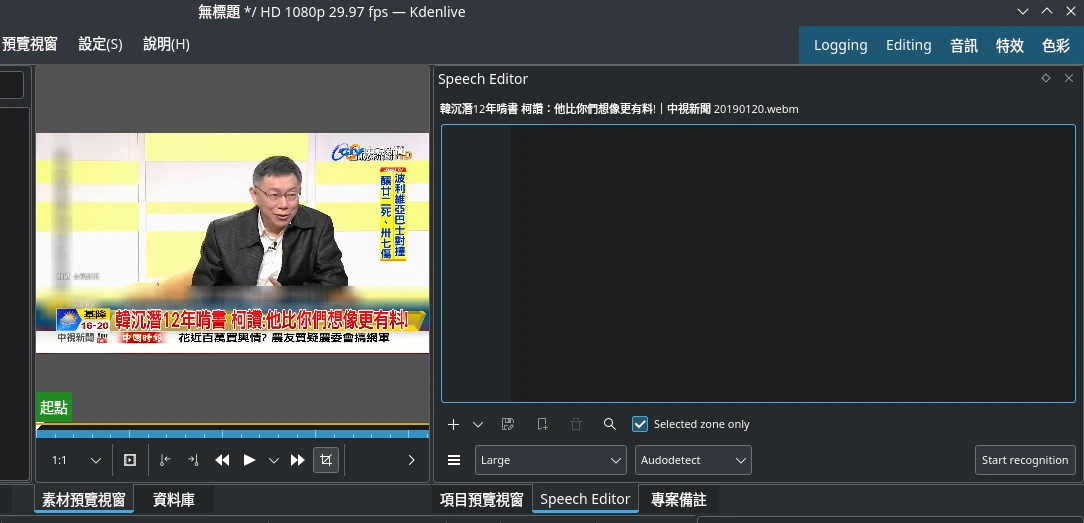
生成的逐字稿不會插到時間軸,這裡比較像是參考用的。
如果你按時間點,再按下書籤按鈕,它就會把註解插到時間軸的影片上

Insert selection in timeline則是按照逐字稿的時間軸內容,將該片段的影片插入到時間軸。Create new sequence with edit會生成一個按照逐字稿的時間軸下去切割的影片序列(sequence)。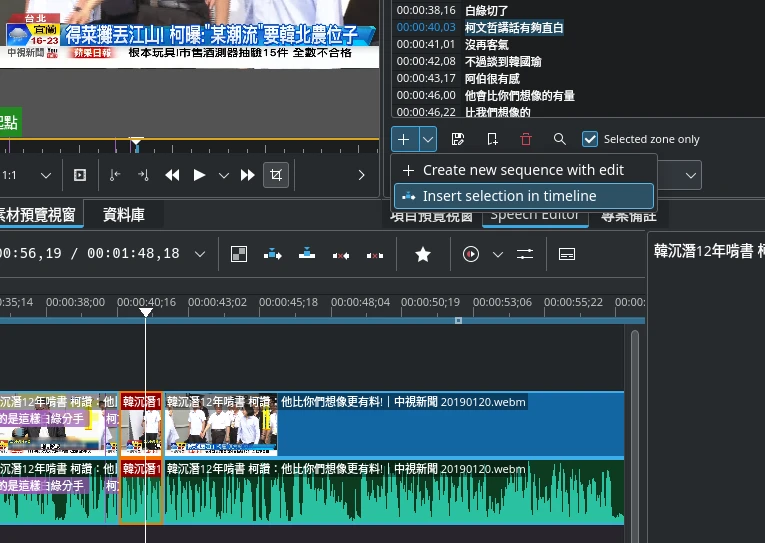
4. 其他語音轉文字工具#
Kdenlive支援匯入srt字幕檔,因此用其他工具處理字幕後再匯入Kdenlive編輯也是可以的。