OCR即是光學字元辨識。
我聽說Windows有「ABBYY FineReader」、「Adobe Acrobat」的專有軟體,能夠將PDF檔案OCR之後變成可編輯的文字,於是我就想在LInux找開源替代品。
正好我手頭上有些設計不良的PDF檔案,裡面文字全部都沒辦法複製也無法搜尋,所以需要一個工具將它們OCR後變成可複製的文字格式。
英文PDF文件範例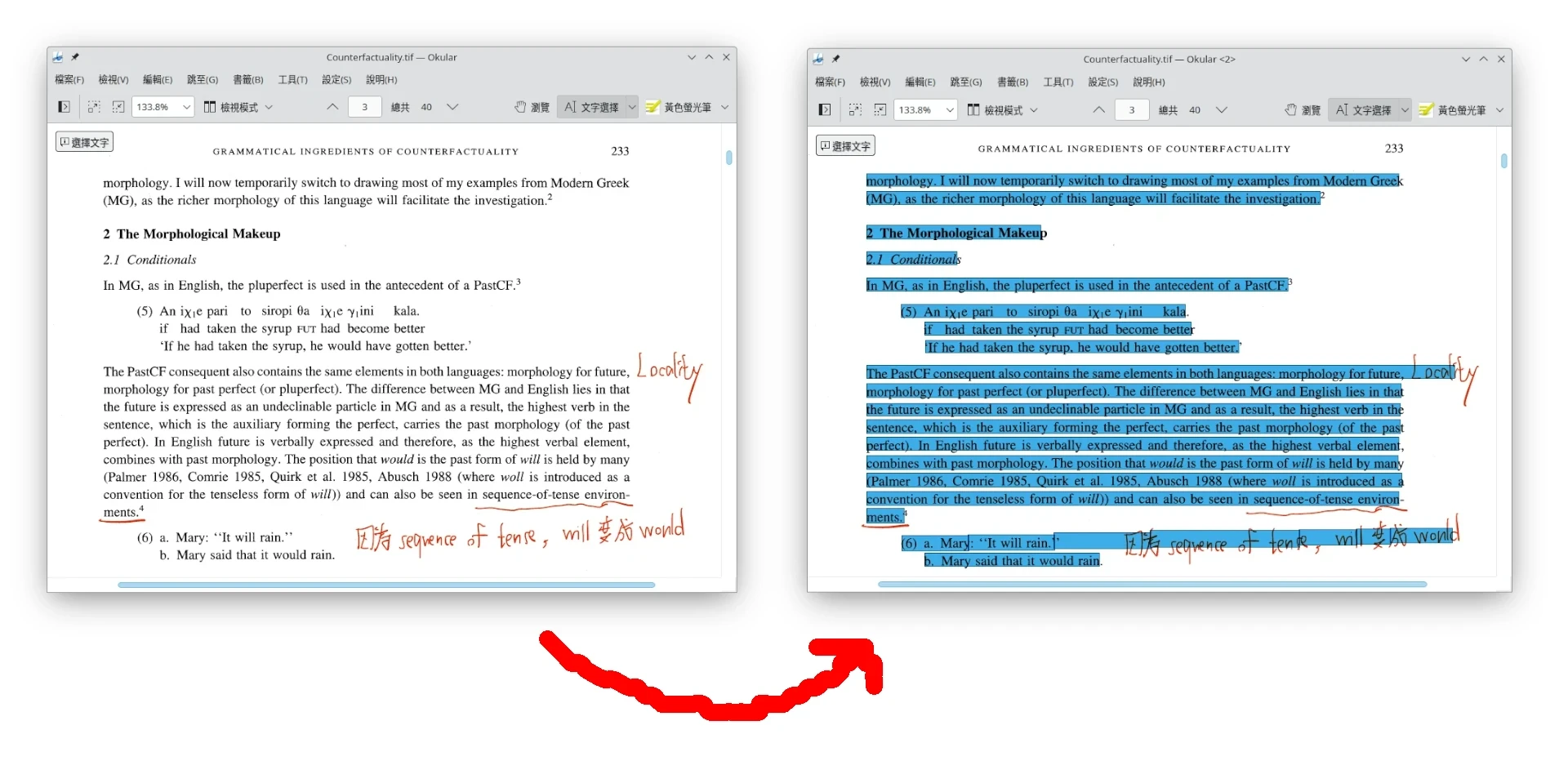
中文PDF文件範例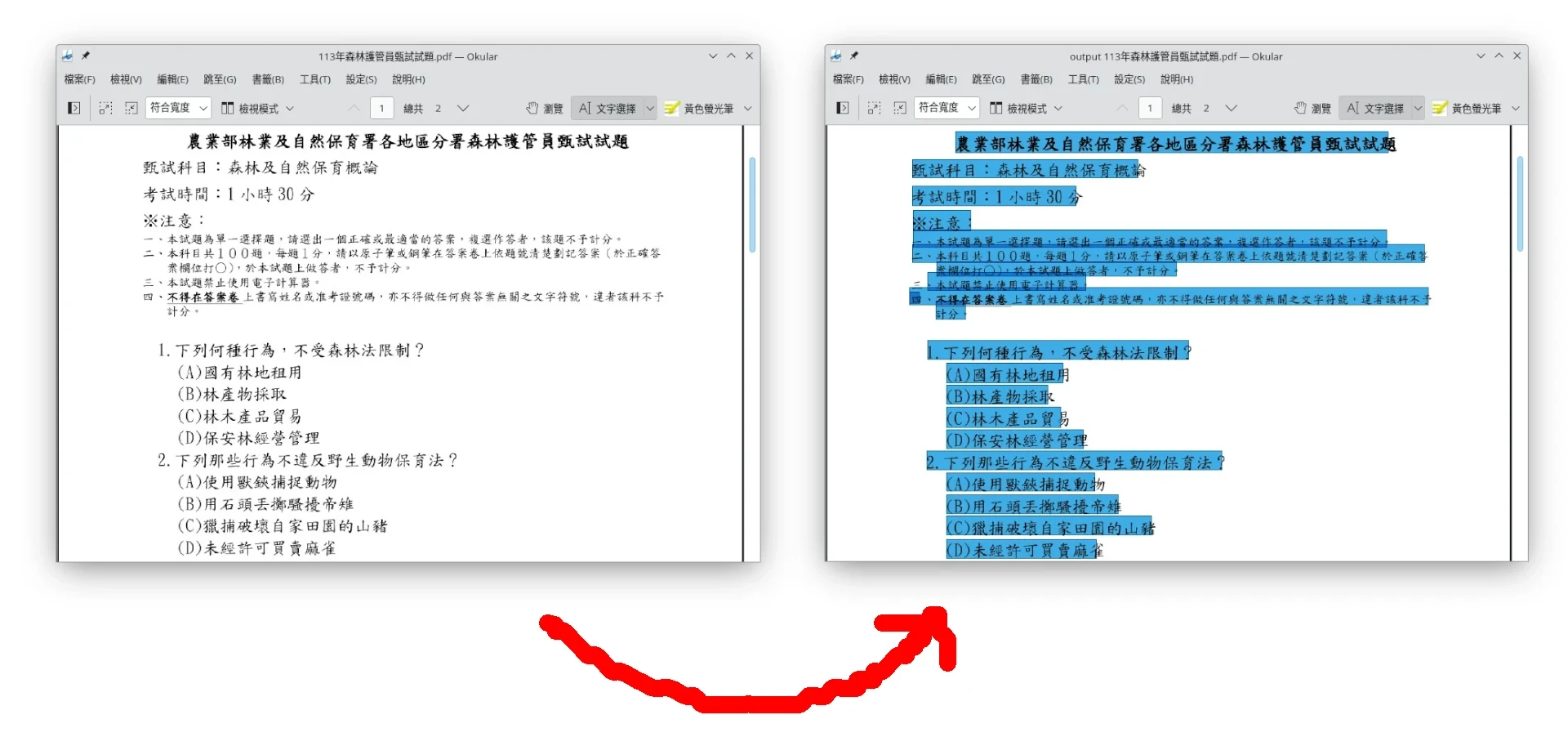
1. Linux的OCR方案探討#
如果需要PDF編輯功能的,那麼LibreOffice Draw便足以勝任。
接著要搞定OCR的部份。
通常Linux的OCR都是使用Google釋出的開源Tesseract引擎,支援中文、英文、日文等多國語言。
Github有很多專案,其中功能最多的應該是這款:LIOS (Linux-intelligent-ocr-solution)。感覺設計不良,安裝後開不起來,可能是GTK版本太老了?
NormCap,擷圖後OCR,僅支援英文,可以用Flatpak一鍵安裝。
TextSnatcher,圖片OCR。可以用Flatpak一鍵安裝。Frog功能亦是類似,支援多國語言。
Pot 派了个萌的翻译器,劃詞翻譯器,支援OCR。
Umi-OCR,基於PaddleOCR製作的圖片與PDF辨識軟體。
OCRmyPDF,命令行PDF轉檔工具,OCR後給PDF加上文字圖層方便後續編輯。英文和中文支援度不錯。
Stirling-PDF,網頁PDF轉檔工具,功能非常多。
另外還有一款ocrfeeder,Gnome的OCR閱讀器,ㄟ…不太好用。
從上述方案來看,還是OCRmyPDF最好了吧。
2. 安裝OCRmyPDF#
因為使用Tesseract引擎,需要先安裝對應語言的套件,Ubuntu套件庫多半有收。例如我要安裝英文與正體中文的套件:
sudo apt search tesseract-ocr
sudo apt install tesseract-ocr-eng tesseract-ocr-chi-tra tesseract-ocr-chi-tra-vert接著再安裝OCRmyPDF套件
sudo apt install ocrmypdf3. 命令行OCRmyPDF用法#
在要處理PDF檔案的目錄開啟終端機。
指定語言為英文,設定輸出為標準PDF(預設的PDF/A格式輸出後便無法修改),再指定輸入檔案為input.pdf與輸出檔案output.pdf,
ocrmypdf -l eng --output-type pdf input.pdf output.pdf如果PDF檔案是英中混合,那就加上多個語言參數:
ocrmypdf -l eng+chi_tra --output-type pdf input.pdf output.pdf關於中文漢字掃描後出現多餘空格問題:這個是Tesseract本身的問題,目前沒有解決方式。
等待辨識轉檔完成,新的PDF就能夠選取文字了。
在LibreOffice Draw開啟的時候,OCR辨識到的文字會成為一個圖層,可以與原始檔案分離。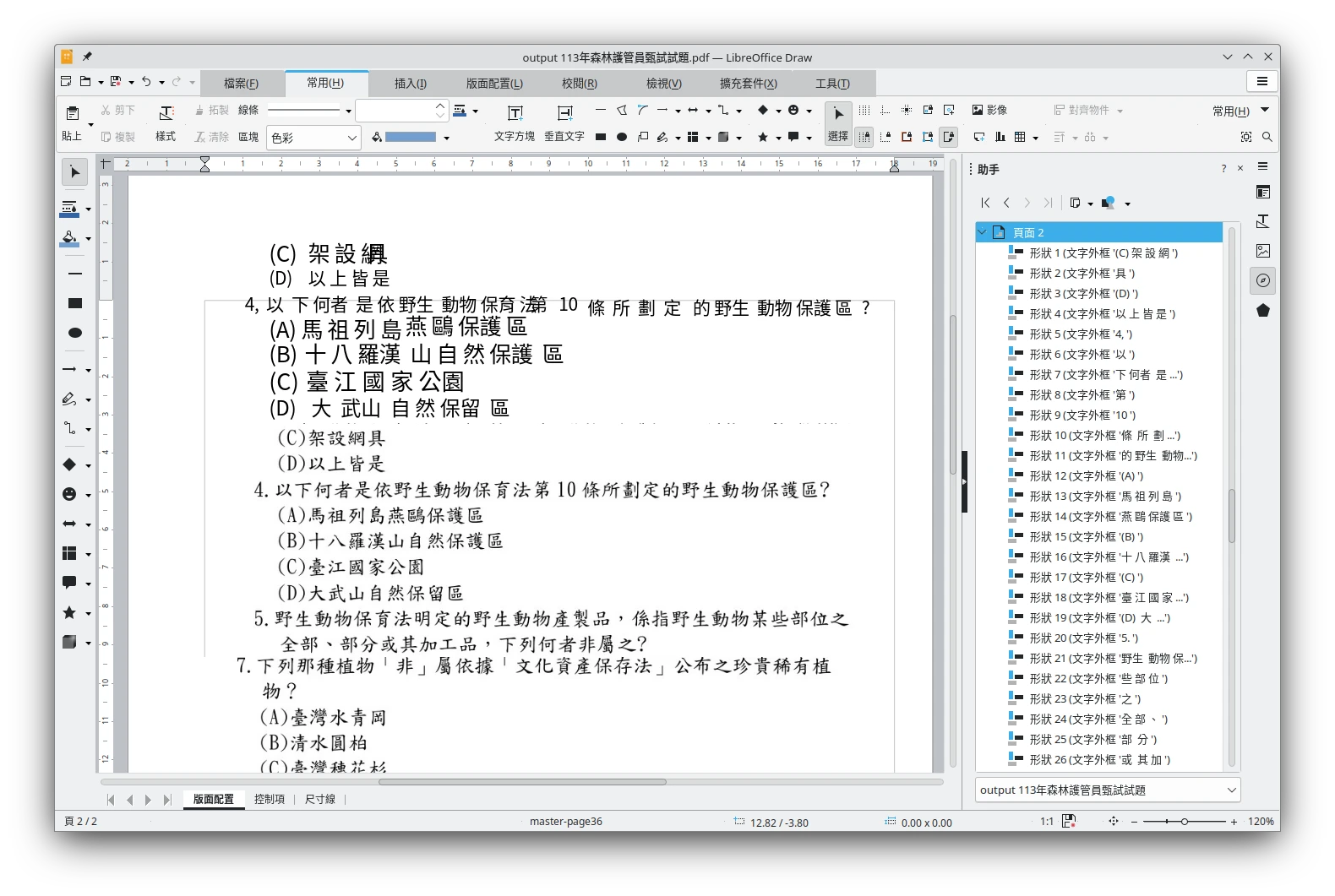
4. 安裝圖形版OCRmyPDF前端#
OCRthyPDF-Essentials是digidigital開發的GUI版本,可以用Snap安裝:
sudo snap install ocrthypdf如果需要遠端處理的,也可以改用Docker部署網頁版razemio/ocrmypdfonweb。