很多作業系統都有內建的文字轉語音服務,例如Windows內建Microsoft文字轉語音服務,Android則是Google TTS。
各個Linux發行版最常見的語音合成系統叫做「Speech Dispatcher」,它是一個獨立的依賴層,能安裝多個文字轉語音(TTS)引擎,再提供界面讓桌面環境的應用程式使用。
所有的語音合成都是在本機處理的,並非透過遠端伺服器合成再回傳。
語音合成系統通常由桌面環境提供,例如GNOME和KDE Plasma的系統設定 → 無障礙輔助,裡面的「螢幕閱讀器」就是用這個發出聲音的。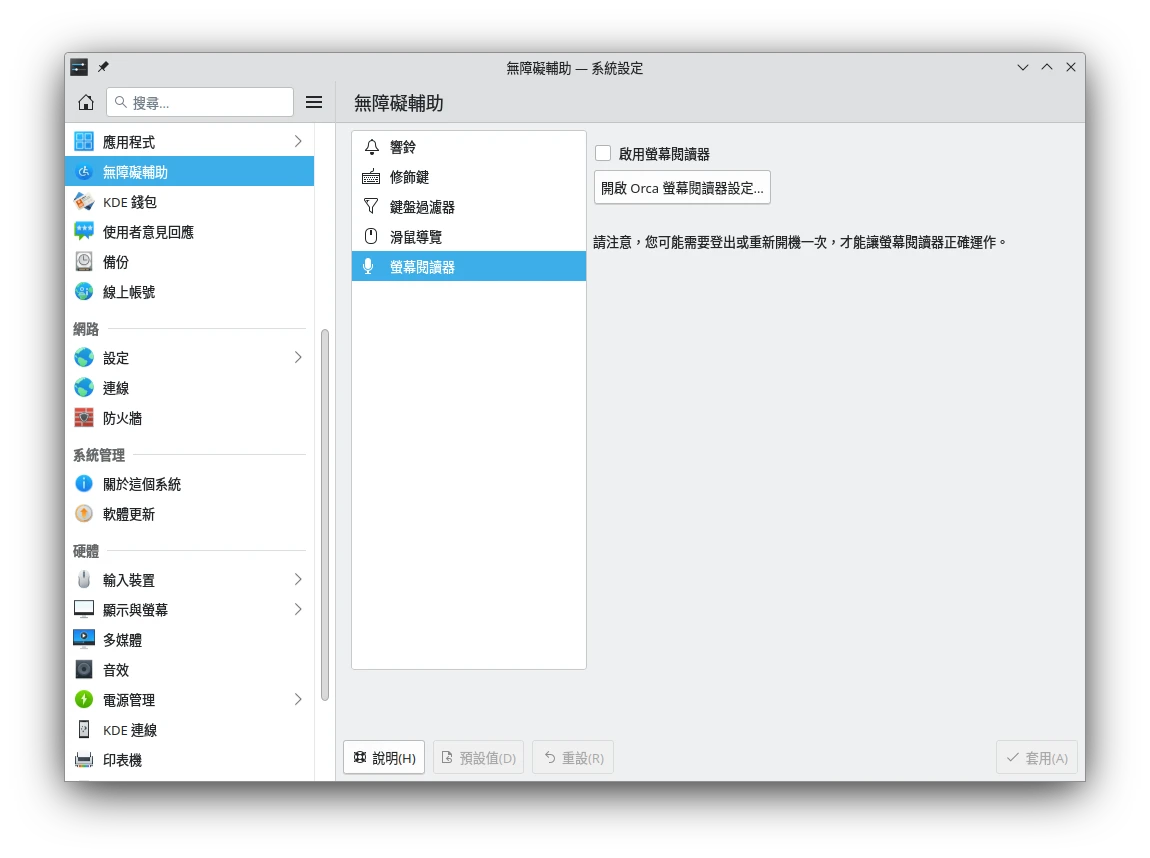
問題是,Speech Dispatcher預設講話聲音是機器人的樣子,非常糟糕。所幸Speech Dispatcher允許載入模組,所以我們可以安裝更好的語音合成引擎。例如eSpeak和CSTR的Festival,但他們都很老了,講話還是跟機器人一樣!
現在有更新的Piper TTS能用,運算十分快速,不需要GPU。Ivon實測英語講話還算自然。
1. 安裝Speech Dispatcher套件#
Ubuntu應該已經內建,沒有的話手動安裝:
sudo apt install speech-dispatcher你可以用這個指令測試文字轉語音功能:
spd-say "Ubuntu is sometimes translated as I am because we are."Speech Dispatcher的使用者設定檔位於~/.config/speech-dispatcher/speechd.conf
2. 安裝Piper TTS#
- 我們使用Elleo開發的安裝器Pied,到Github下載.flatpak套件,透過Flatpak安裝
flatpak --user install ./com.mikeasoft.pied.flatpak開啟後依照指示下載Piper
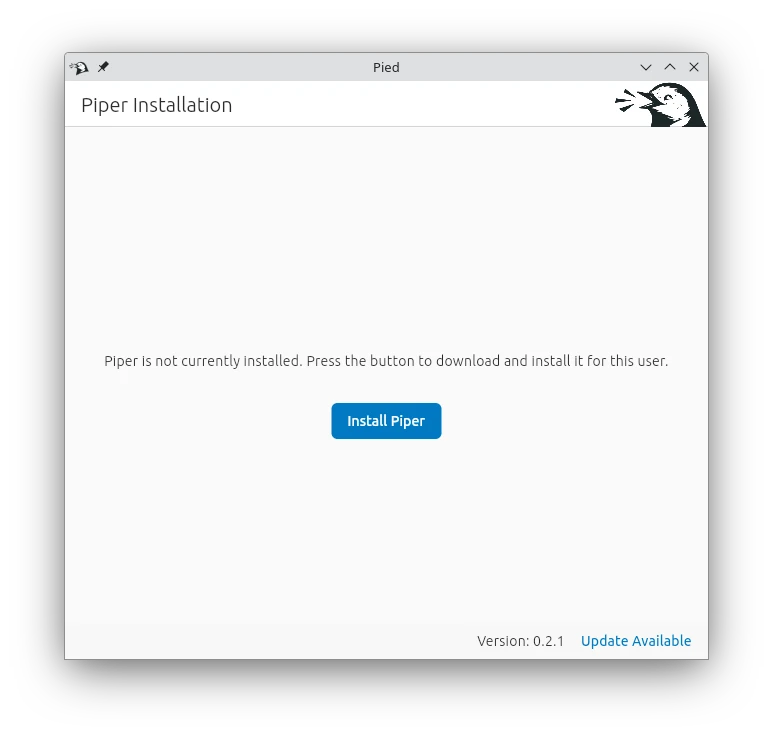
下載語音模型,然後點選Select Voice,設定為目前語音
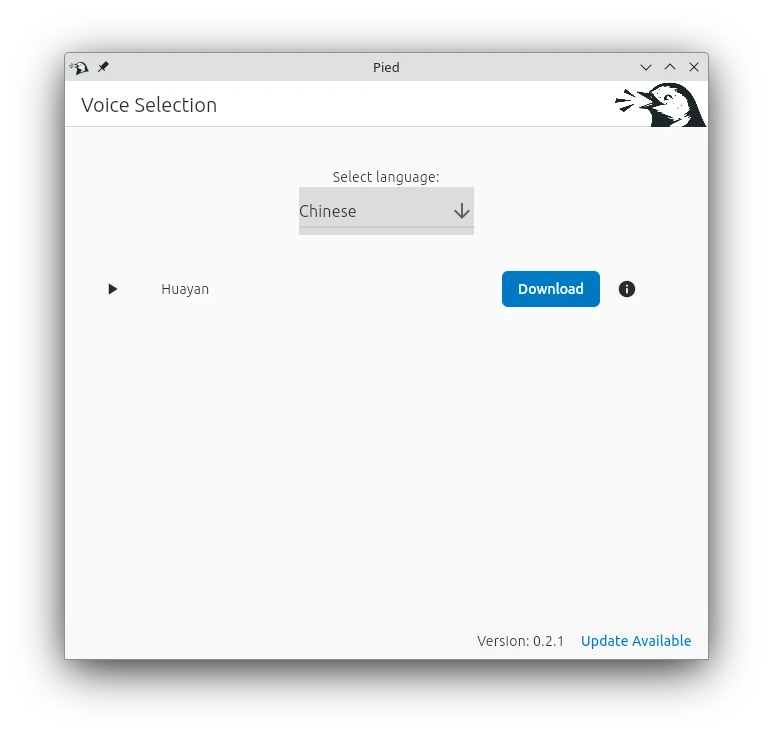
Piper模型會放到~/.var/app/com.mikeasoft.pied/data/pied/piper/piper
我自己測試得出來的結果,Piper的模型對英文支援度較好。
不知道為什麼,Piper的中文模型zh_CN-huayan-medium.onnx準確率很糟糕,明明在其他軟體還行的說….
3. 使用Speech Dispatcher朗讀#
Linux支援Speech Dispatcher的程式不多,目前只有Firefox和Ocular PDF閱讀器有使用到。
Okular選取文字,唸出PDF檔案內容。
Firefox點選對應語言的網頁,進入閱讀器模式,使用Speech Dispatcher朗讀,發聲便會是剛剛Pied所設定的聲音。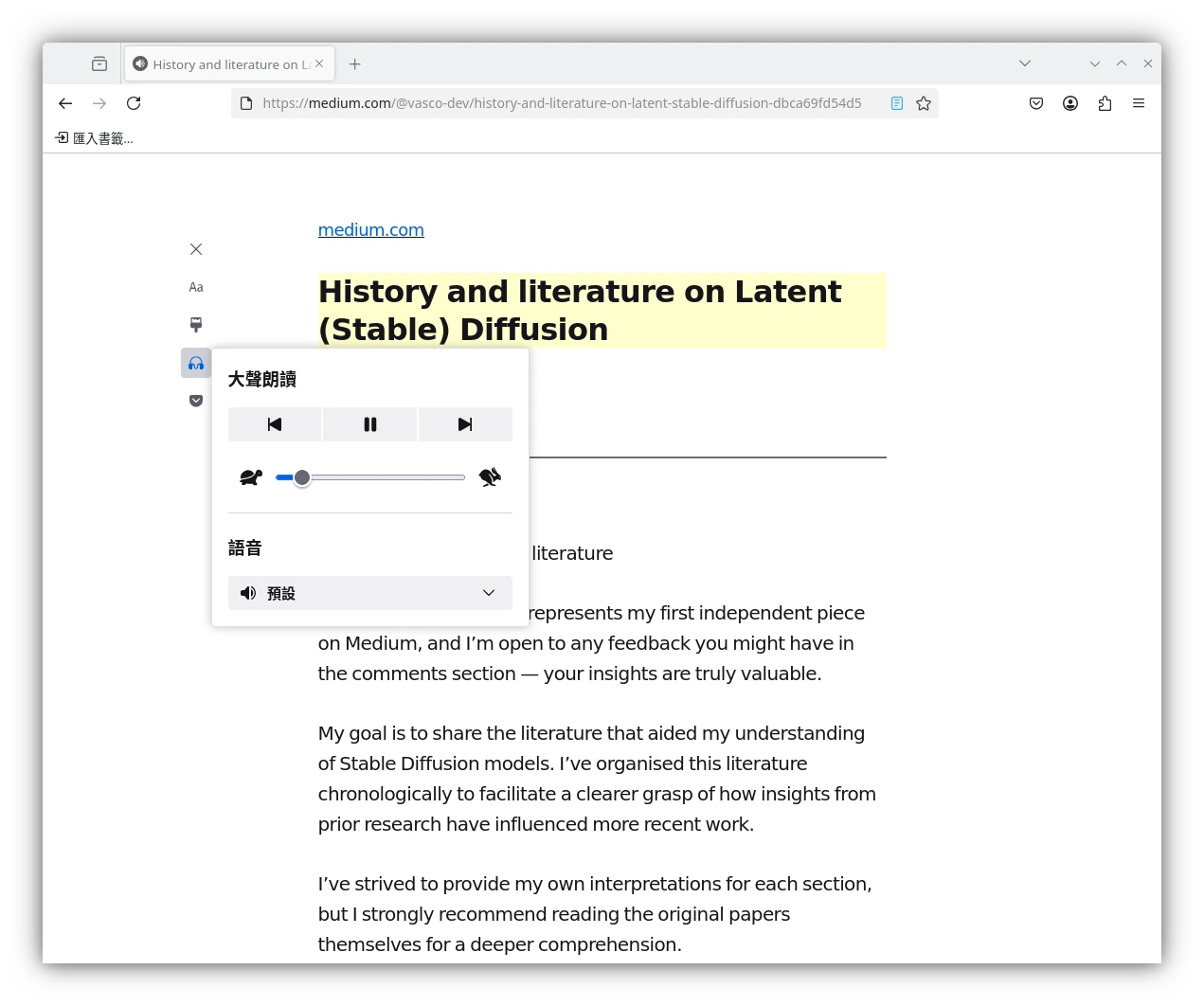
Chromium沒辦法使用Speech Dispatcher,只能用擴充套件安裝Piper。
如果你要全域朗讀畫面上的文字,那麼就開啟桌面環境的無障礙輔助工具,開啟螢幕閱讀器,讓它唸出標題文字。Linux有叫做Orca的程式能調整螢幕閱讀器的設定。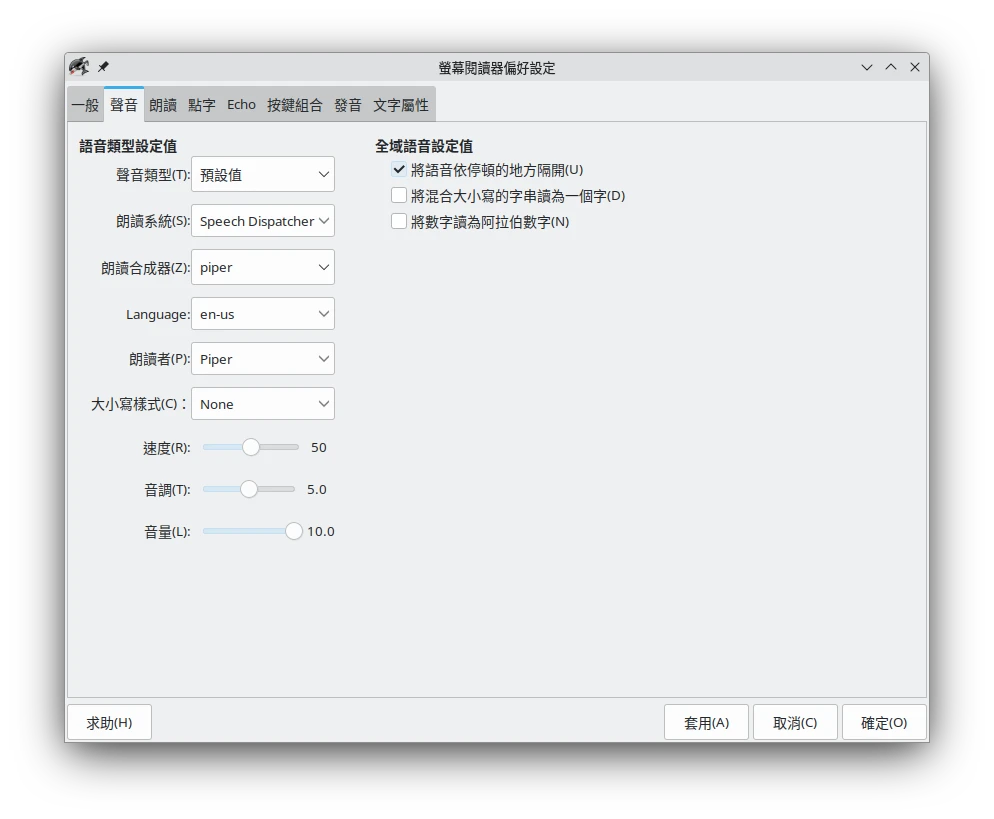
4. 獨立的文字轉語音程式#
全系統的文字轉語音不可行,那麼就用單一程式來文字轉語音吧。
Speech Notes值得一試,兼具語音辨識與文字轉語音的功能,中文支援度更佳。可以用來製作逐字稿與合成講話聲音。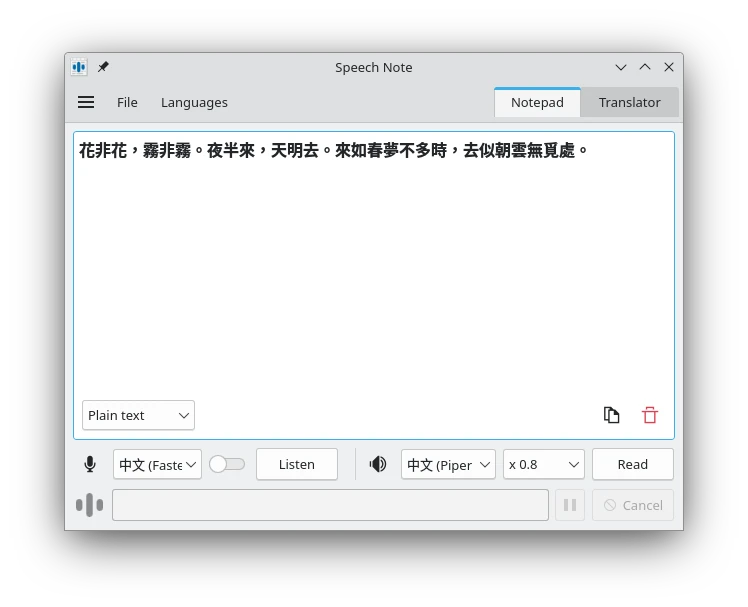
但是,它沒辦法跟Speech Dispatcher整合。