相信很多人跟Ivon一樣都有隨手蒐集梗圖 (meme) 的習慣,方便在網路筆戰的時候隨手丟出一張表情包,然後高歌離席。
不過圖片一旦多起來,單單用資料夾分類已經不能整理了吧。
我嘗試用相簿軟體(例如Immich、PhoroPrism、digiKam)整理梗圖,但都感覺不太合適。
我在Github有看到一個專案就叫Meme Search的,它基本上是從一個圖片資料夾讀取裡面的圖片,用OCR抽出文字之後,再生成能夠搜尋的文本,還能夠用AI模型生成描述圖片的一串文字。但缺點是Meme Search介面很陽春。我試了沒辦法下載模型。還有AI模型辨識太吃硬體資源,需要GPU才能跑得快。
故我放棄使用這種專門軟體的想法,改用Hydrus Network。
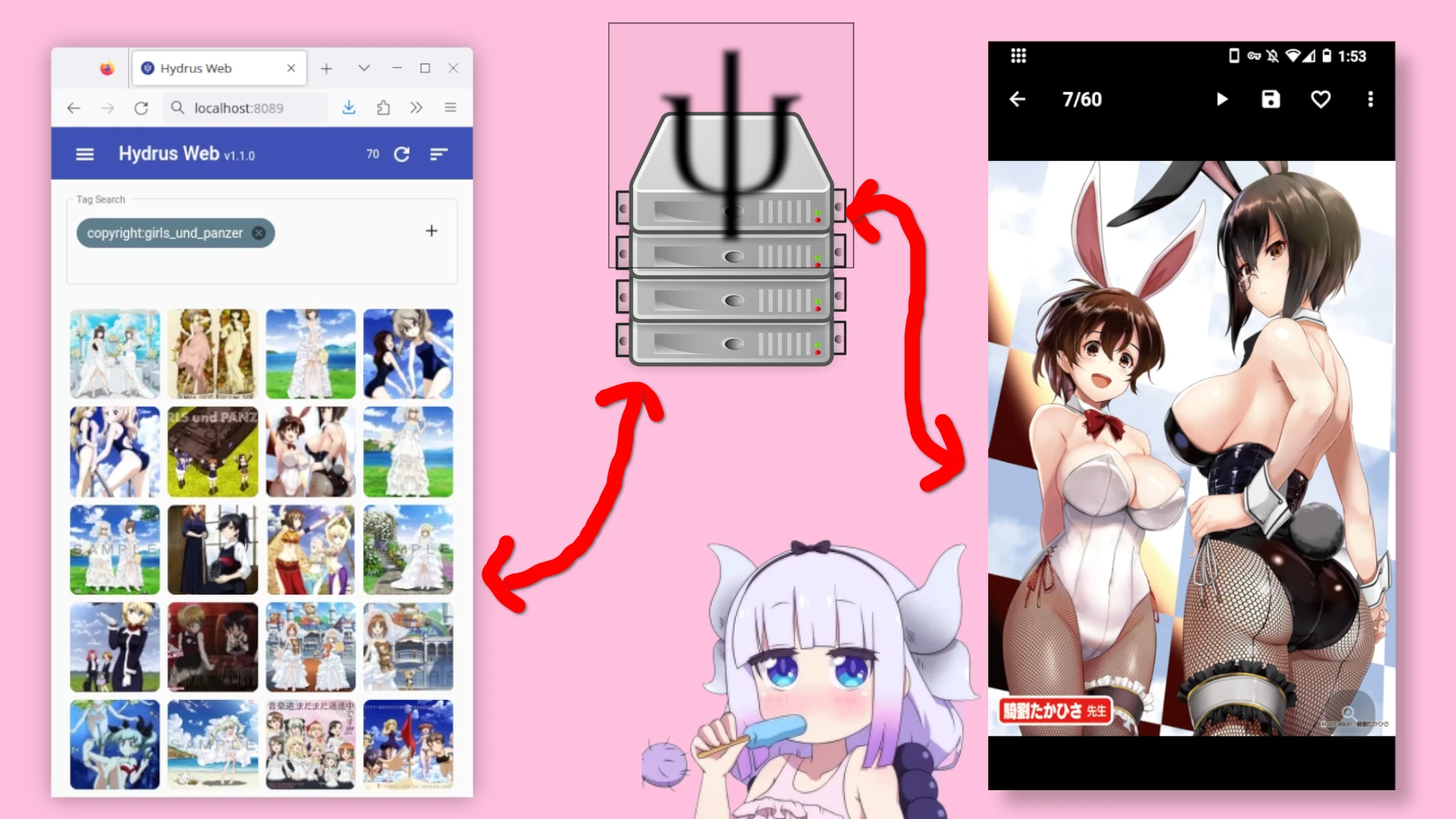
Hydrus Network是能夠整理各種雜圖的開源軟體,裡面沒有資料夾機制,全靠打標籤搜尋,加上有評分以及寫筆記的功能。那麼用來整理梗圖就是再好也不過了。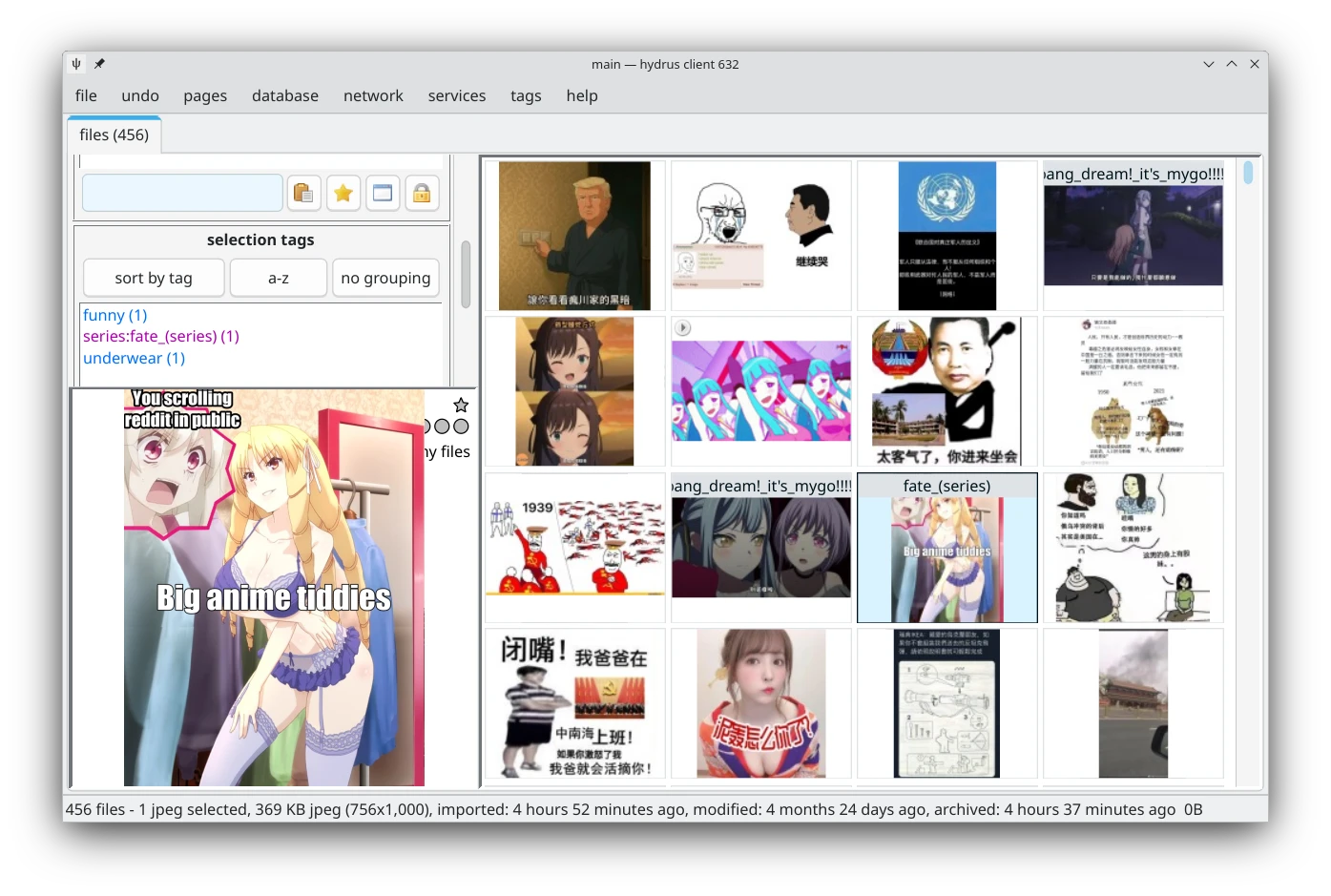
Hydrus Network能將所有關於圖片的資料記載下來,方便日後搜尋。這個軟體偏向手動整理圖片,沒有AI自動分類。不過因為開放API,Hydrus Network尚有其他開發者寫的OCR插件能用。
再搭配Hydrus Web客戶端,隨時隨地都能找到需要的梗圖。例如在手機上搜尋遠端Hydrus Network伺服器的梗圖。

1. 我的梗圖蒐集機制#
梗圖通常來自於瀏覽器看的網頁,還有在手機APP上看到的內容。
把圖片存下來之後,我會使用簡單的資料夾暫時進行分類,然後再放到電腦上的Hydrus Network整理。
一個「梗圖」資料夾下的分類法大概像這樣,主要是依照用途分類:
- 科技梗圖
- 動物梗圖
- 動漫梗圖
- 政治梗圖
- 智慧語錄
- 啟發靈感的素材
2. Hydrus Network用法簡介#
安裝Hydrus Network客戶端。這個軟體支援Linux、Windows、macOS系統。
Hydrus Network需要匯入圖片才能處理。選取一資料夾,拖曳到Hydrus Network視窗,會出現匯入視窗。
匯入之後,Hydrus Network會自動開一個新分頁。
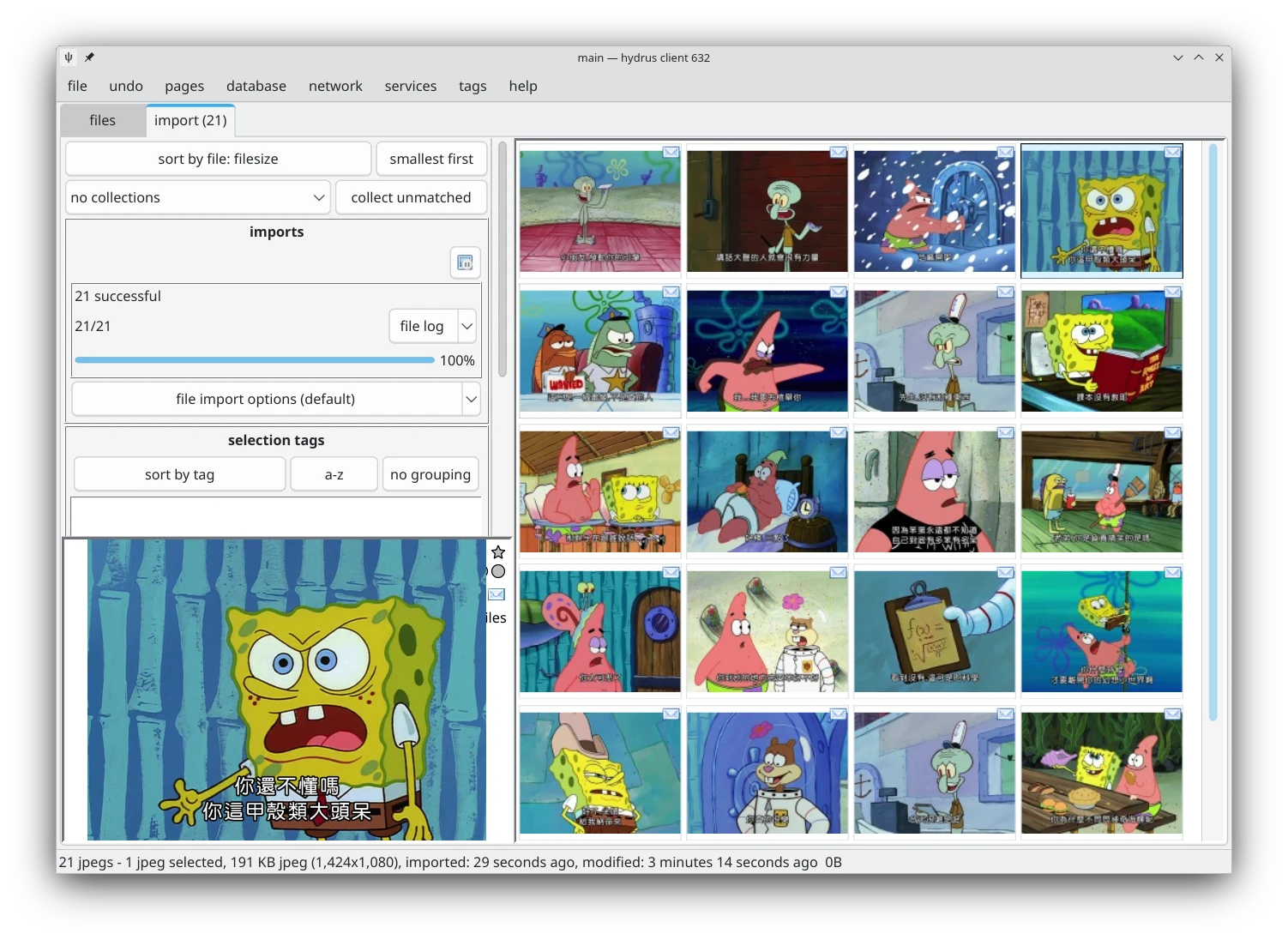
在這裡多選圖片,按右鍵tag,批次編輯標籤之後,再按右鍵archive,正式封存到資料庫。
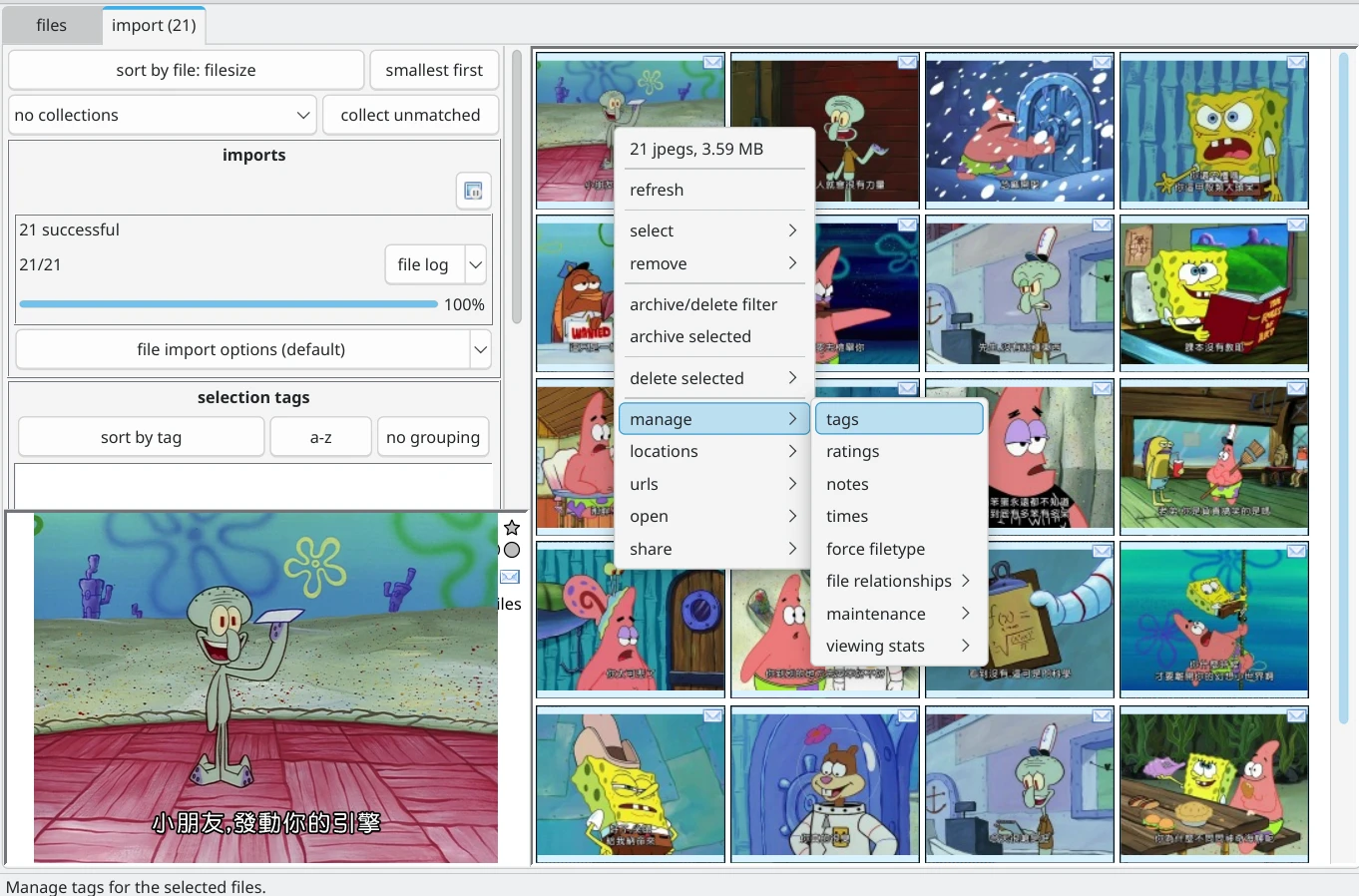
3. Hydrus Network內部標籤打法#
這沒有絕對的格式,我只用自己覺得方便的作法。
因為我覺得用英文打字比較快,所以標籤大部分都是用英文表示。
首先,因為Hydrus Network我不只是拿來放梗圖,所以梗圖都要有一個funny的標籤。這樣至少日後在找的時候知道我是在找好笑的東西。
針對我上面提過的分類:我會加上標籤來說明這張梗圖的性質,例如technology表示跟科技有關的梗圖,animal表示動物梗圖,諸如此類。
這在大批次匯入梗圖的時候非常重要,至少我能在一個介面就先批次歸類出這批梗圖的性質。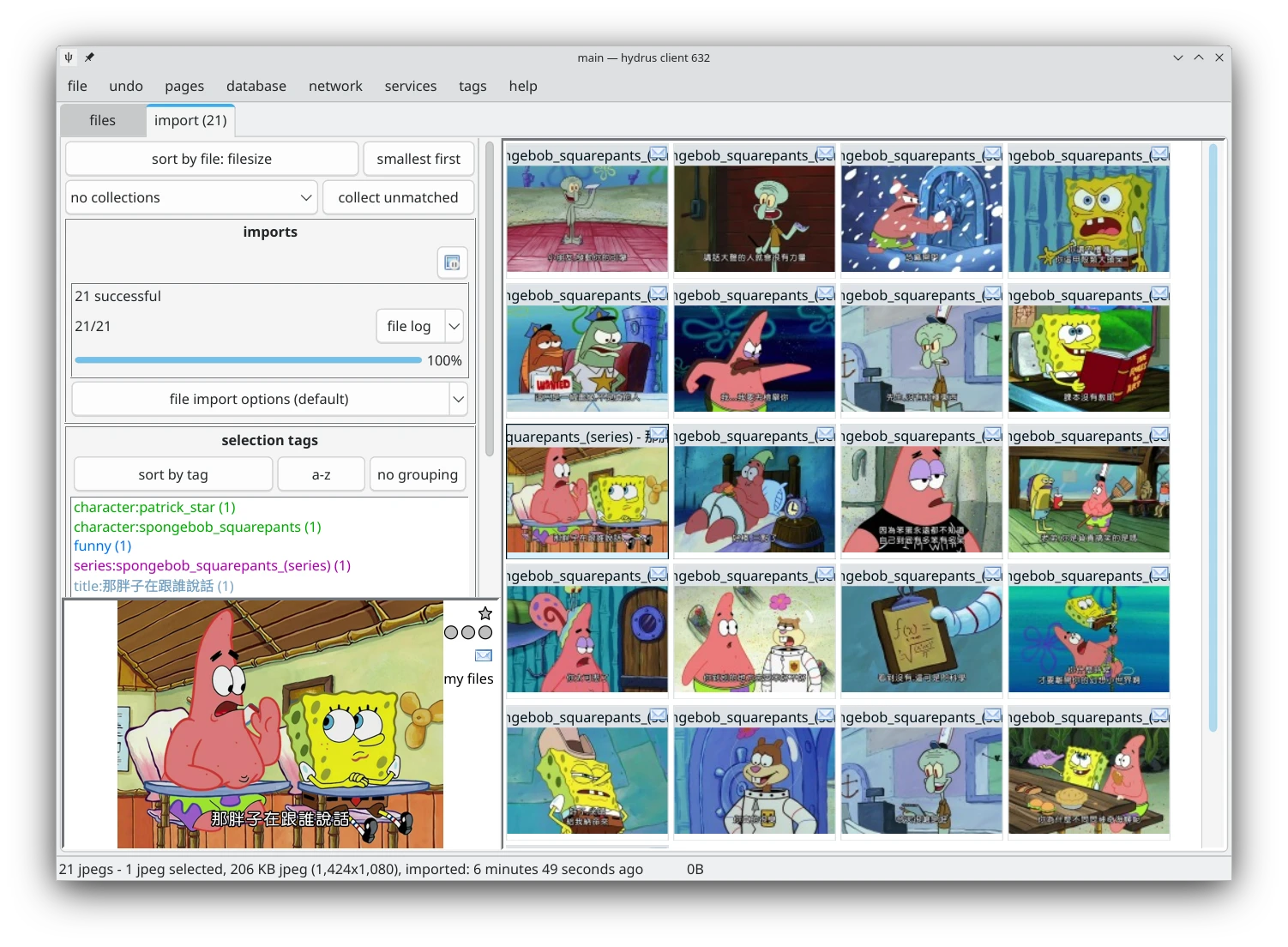
接著是單張圖片的部分。
不是很重要的梗圖,我就只是打上funny還有子分類的標籤而已。
需要紀錄額外資訊的梗圖,就用命名空間:數值的標籤形式,儘量記錄下重要的特徵。
例如,紀錄重要的台詞,我就會用title:文字的標籤寫下來,這對日後搜尋有多種變體的梗圖十分有用。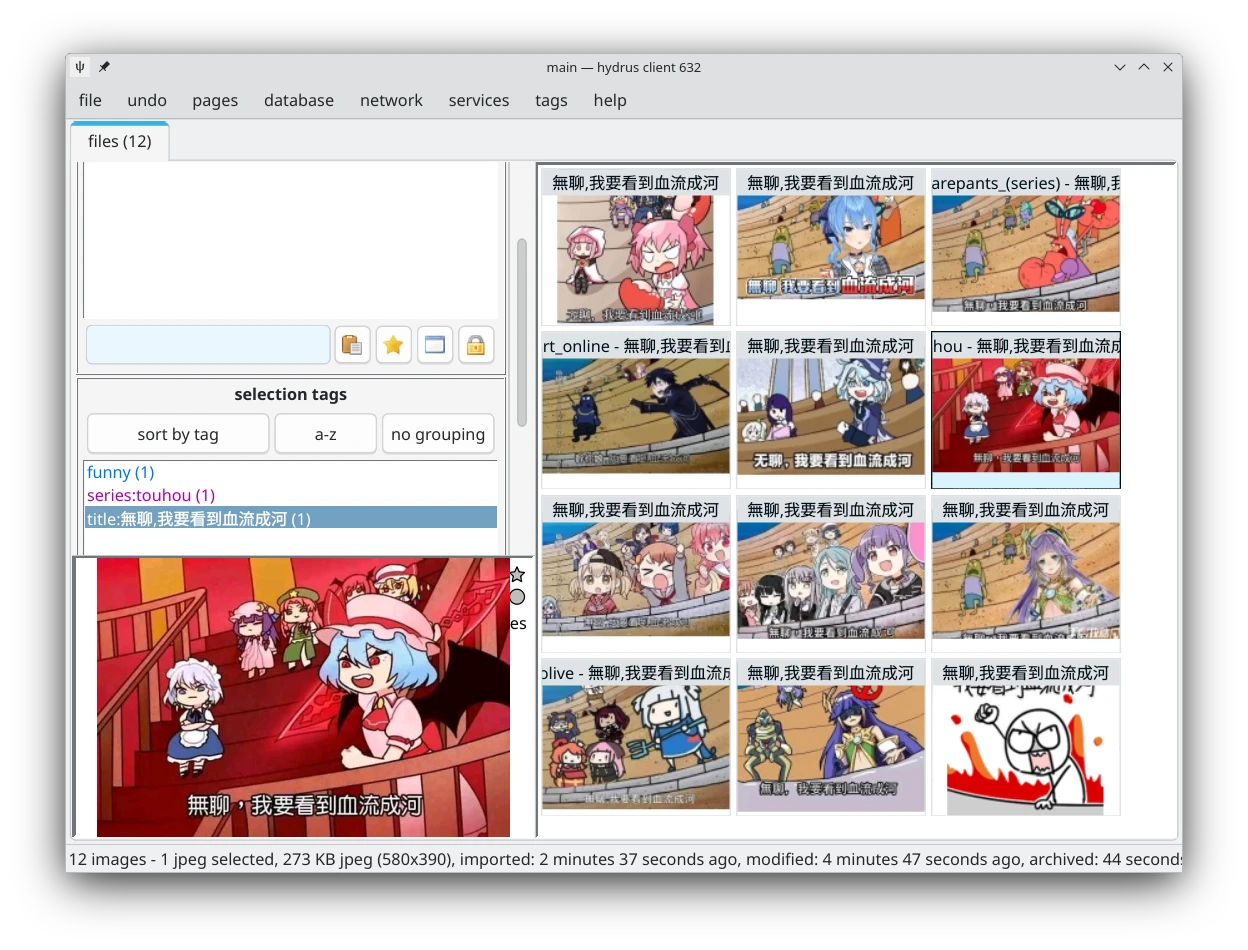
如果很多梗圖都出自同一部卡通,就標注series:卡通名稱標籤。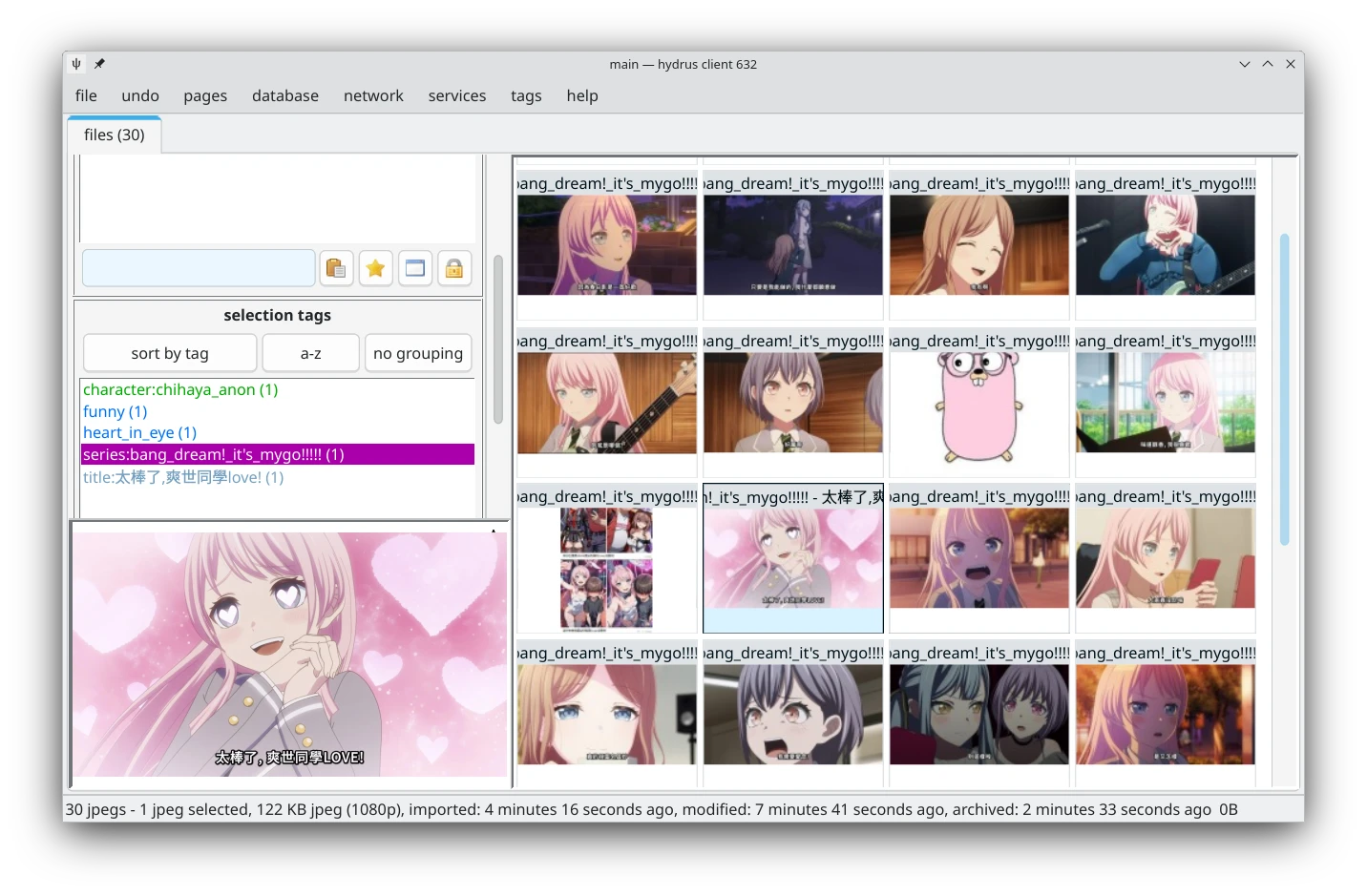
person:人名或character:人名標籤。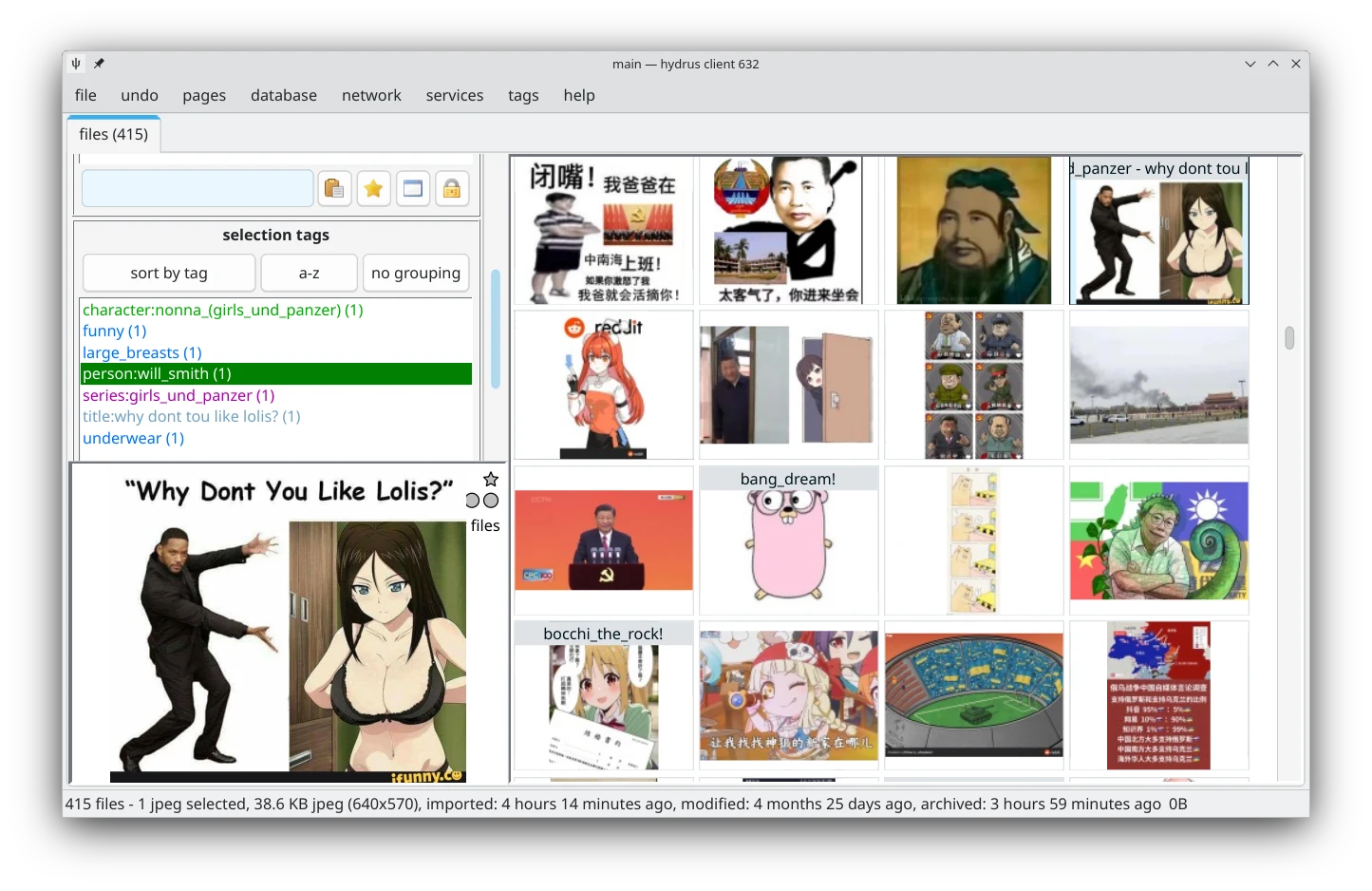
需要更詳細的資訊,就對圖片點右鍵,加上note以及url,詳細記載圖片來源為何。不過這種情況很少見啦,你又不是KnowYourMeme的主編,不用那麼認真。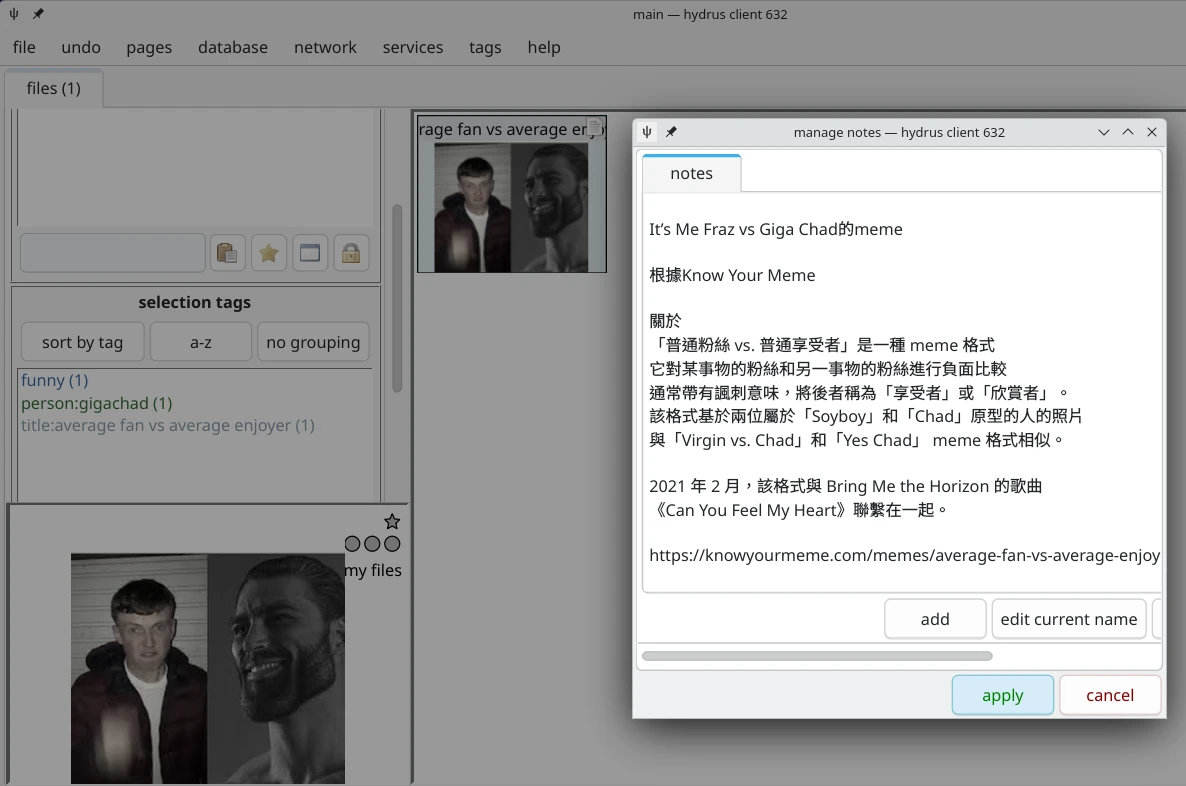
4. 梗圖搜尋方式#
Hydrus Network支援多語言搜尋,善用title:標籤只要打幾個字就能找到完整字串的標籤。有時候連命名空間都不需要打。如果不確定前後文的話,就用星號萬用字元替代。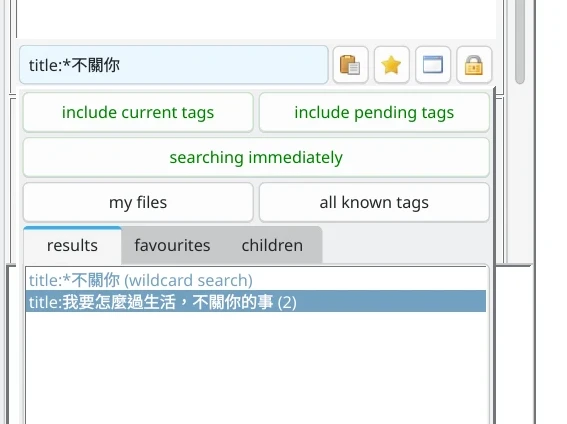
至於其他搜尋梗圖的方式,我會做一個快速搜尋面板。
按一下搜尋欄的星星,點manage favorite search,點add,針對各種梗圖的共通標籤設定搜尋條件。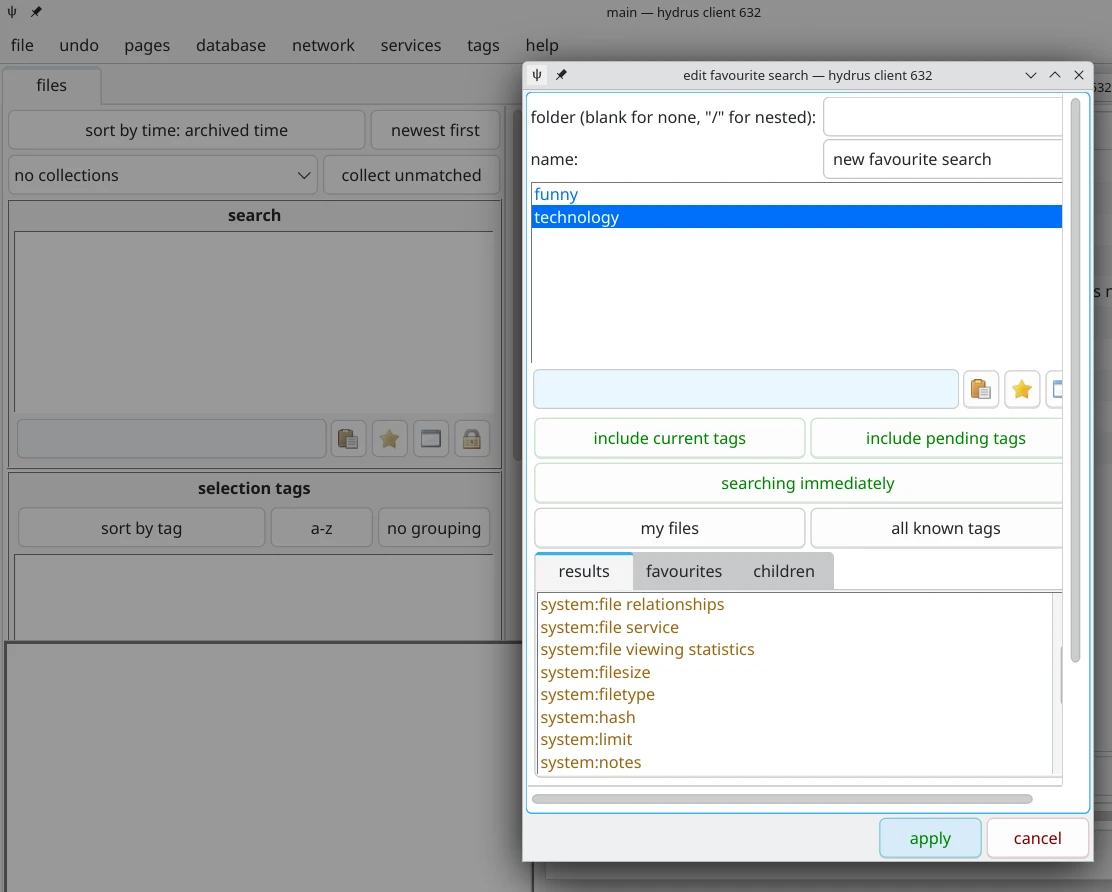
這樣就能快速篩選梗圖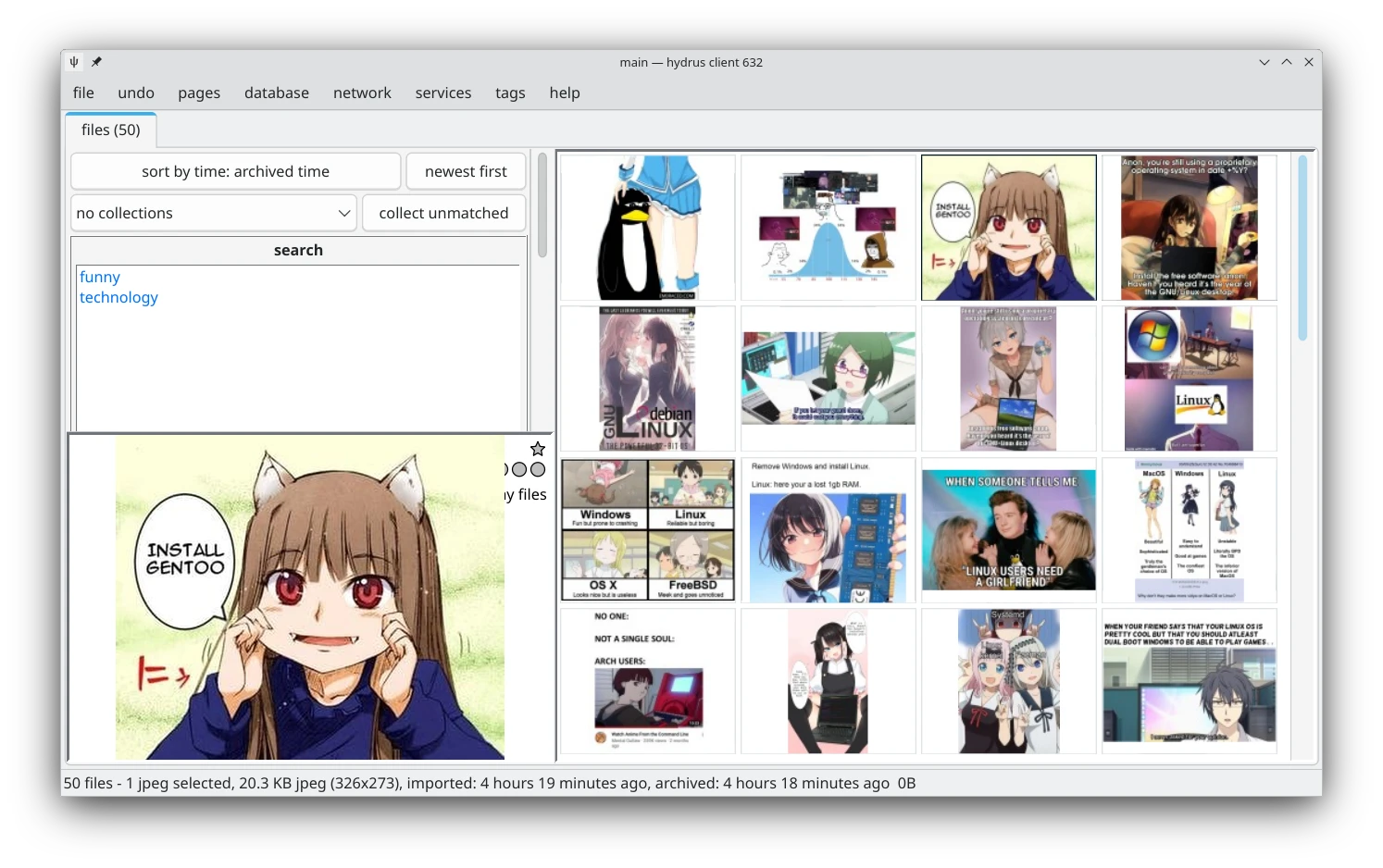
如果需要遠端存取Hydrus Network資料庫的,架設一個Hydrus Web即可。

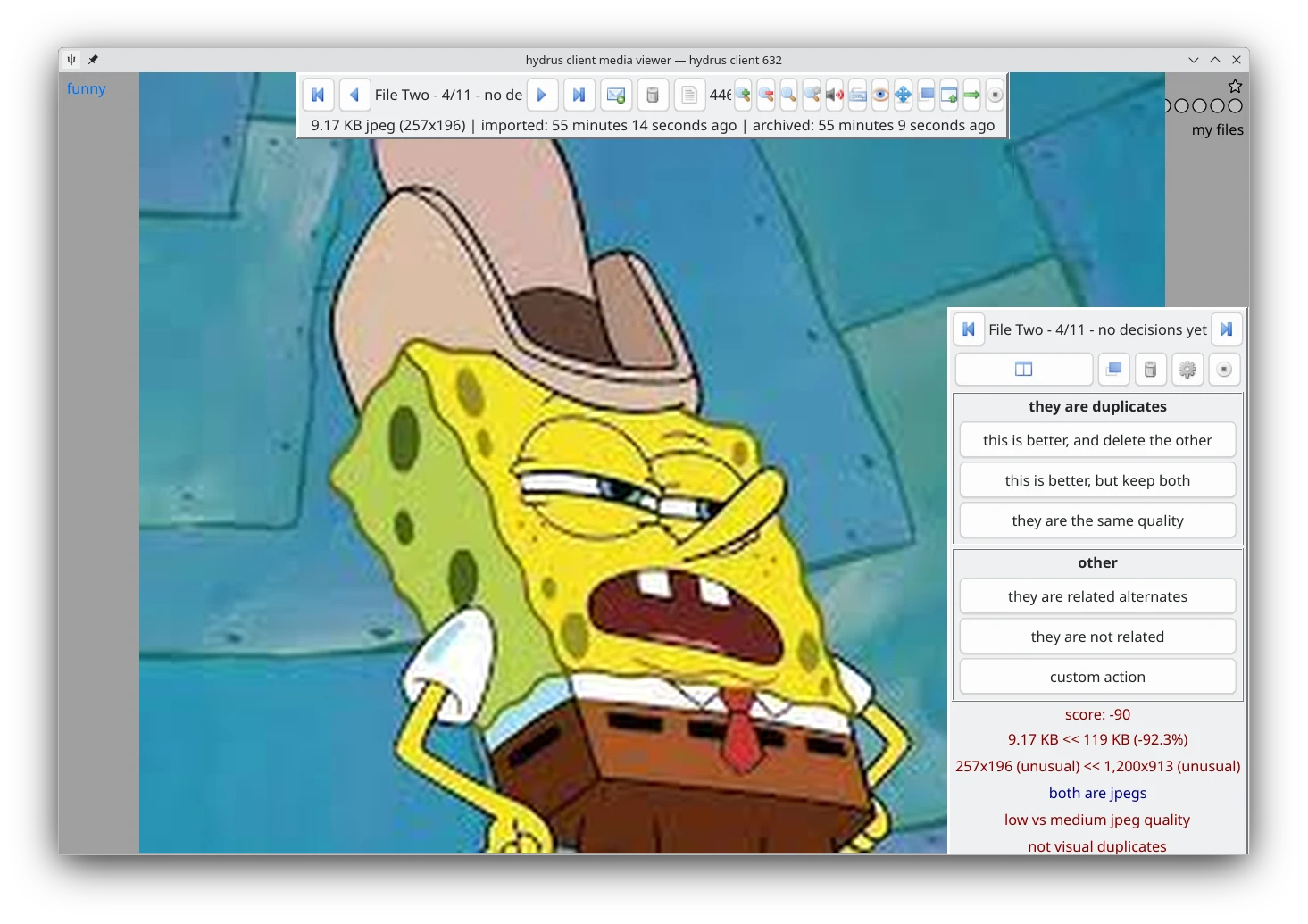
5. 比對重複梗圖#
因為梗圖是到處流傳的,會出現不同的解析度的版本是正常的。我們可能在蒐集資料的當下不經意的下載多張一模一樣的副本。這個時候能夠用Hydrus Network內建的比對程式將他們列出來。
點pages → new special page → duplicates processing
在preparation頁面將相似度設定為speculative,也就是相似度最低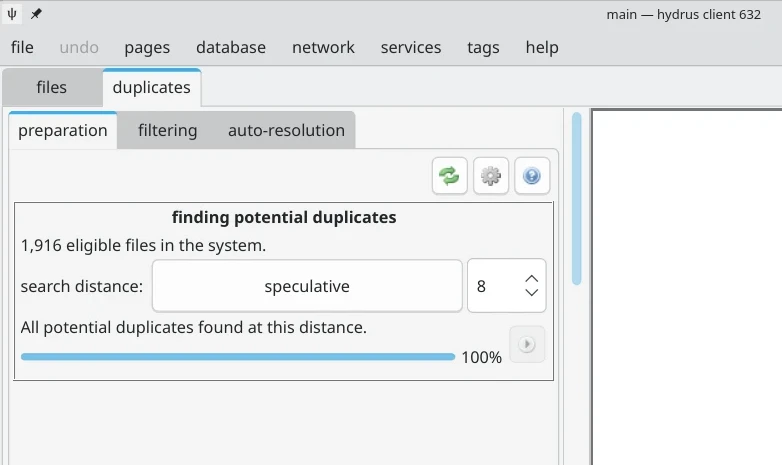
在filter頁面輸入要搜尋的標籤,像我的範例就是限縮到funny標籤。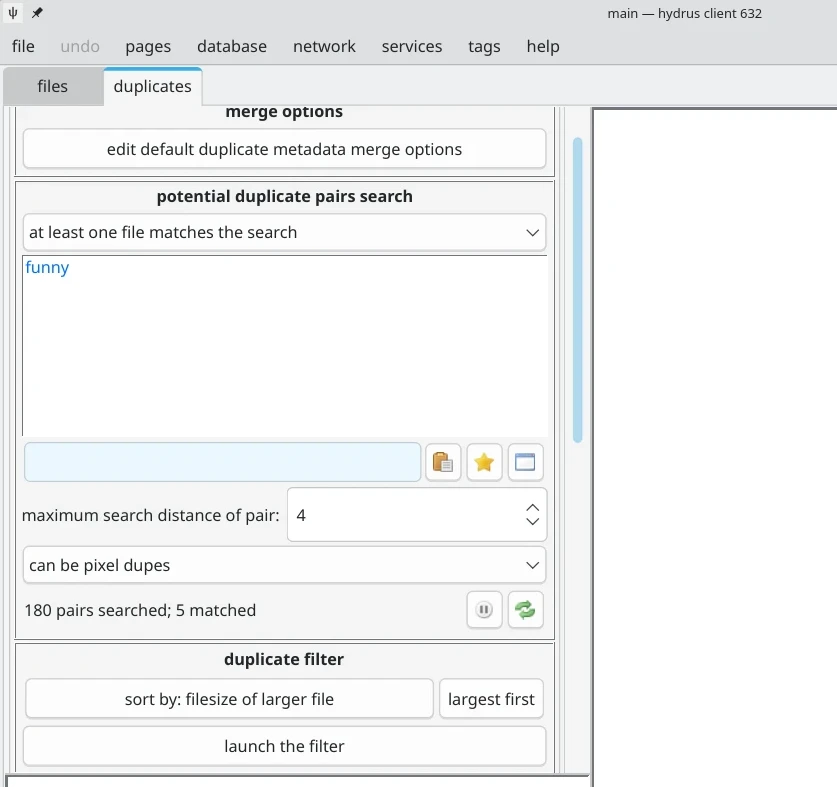
搜尋完成後點launch the filter,上下滾動滑鼠,比對兩張圖片,依照畫面指示決定保留或刪除。