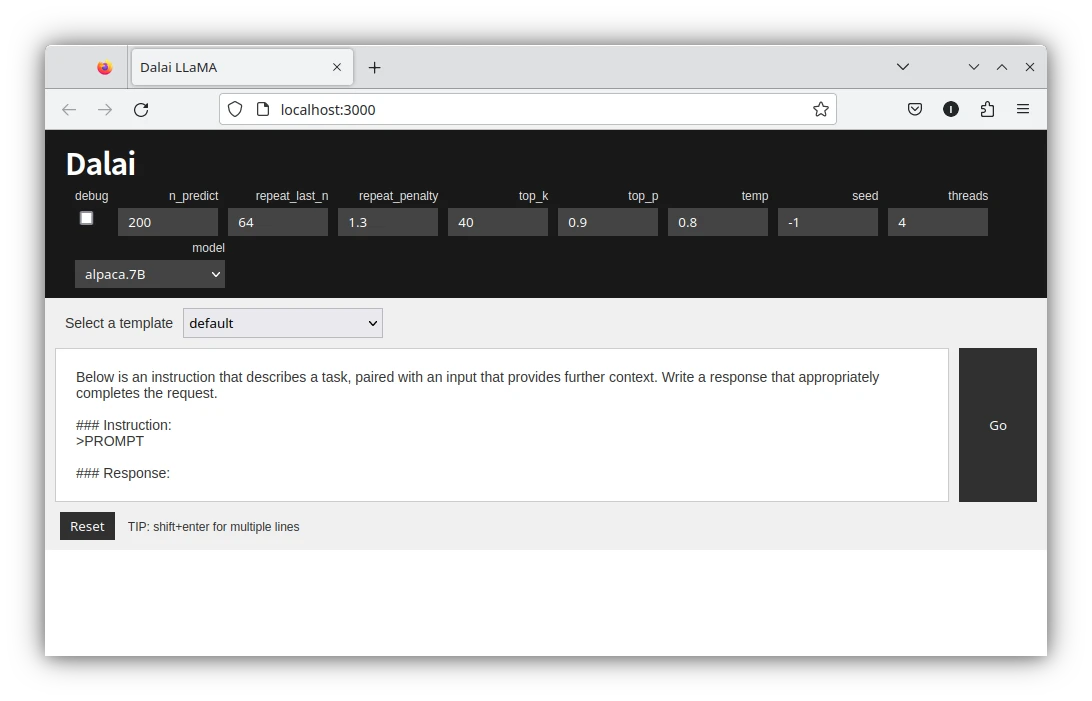
本文Ivon簡介Meta LLaMA AI聊天模型的背景資訊,並解說如何在您的電腦上跑離線版LLaMA AI。
1. LLaMA是什麼?#
隨著OpenAI ChatGPT的出現,讓人們了解到通用大型語言模型的應用潛力。不過ChatGPT有一個很大缺點,就是它跑在OpenAI的伺服器。語言模型龐大需要伺服器等級的硬體支撐,這點可以理解,但是使用會受到廠商限制,導致不能肆意妄為,甚至要「催眠」一下才會聽話(喂)。那麼有沒有可能在個人電腦跑「解除封印」的語言模型呢?LLaMA是目前最新的選擇。
LLaMA是Meta推出的通用大型語言模型(large language model),其硬體需求較低,可安裝在個人電腦,離線與AI聊天,當作OpenAI ChatGPT的低階替代品。
2023年2月,Meta研發的通用大型語言模型「LLaMA」在發表前慘遭外洩,造成轟動,吸引許多人為其撰寫程式。儘管Meta要求各大網站下架,仍阻擋不了相關程式的推出。所以Meta等於「被迫」將LLaMA開源,只不過模型的完整權重(weights)仍需要向Meta填表格索取。
Meta訓練了不同等級的LLaMA模型,依訓練參數數量分為7B、13B、30B、65B。Meta在他們的論文宣稱LLaMA 13B的模型性能超越GPT-3模型。
2023年7月,Meta和Microsoft共同發表新一代模型「LLaMA 2」。
在那之後,基於LLaMA訓練的模型如雨後春筍出現,人們餵給LLaMA各式各樣的資料,從而強化了LLaMA的聊天能力,甚至使其支援中文對答。
即使如此,LLaMA的訓練參數還是差ChatGPT一截,所以不能預期回答品質超越ChatGPT,更何況GPT 4了。
訓練參數越多的LLaMA模型理論上越聰明,但是最大的(65B)跑起來仍需要伺服器等級的硬體;而較小的模型(7B、13B)雖然比較笨,卻是個人電腦跑得動的等級,有些模型甚至不用顯示卡也能跑。
所以LLaMA使個人電腦、手機跑大型語言模型成為可能。
2. LLaMA可以做的事情#
作為大型語言模型,LLaMA可以完成以下這些類似ChatGPT的任務:
解釋學術概念,例如:解釋Skinner行為主義心理學理論的優缺點,並舉出五個例子
寫一個Python程式,解決八皇后演算法問題(Eight queens puzzle)並給出解釋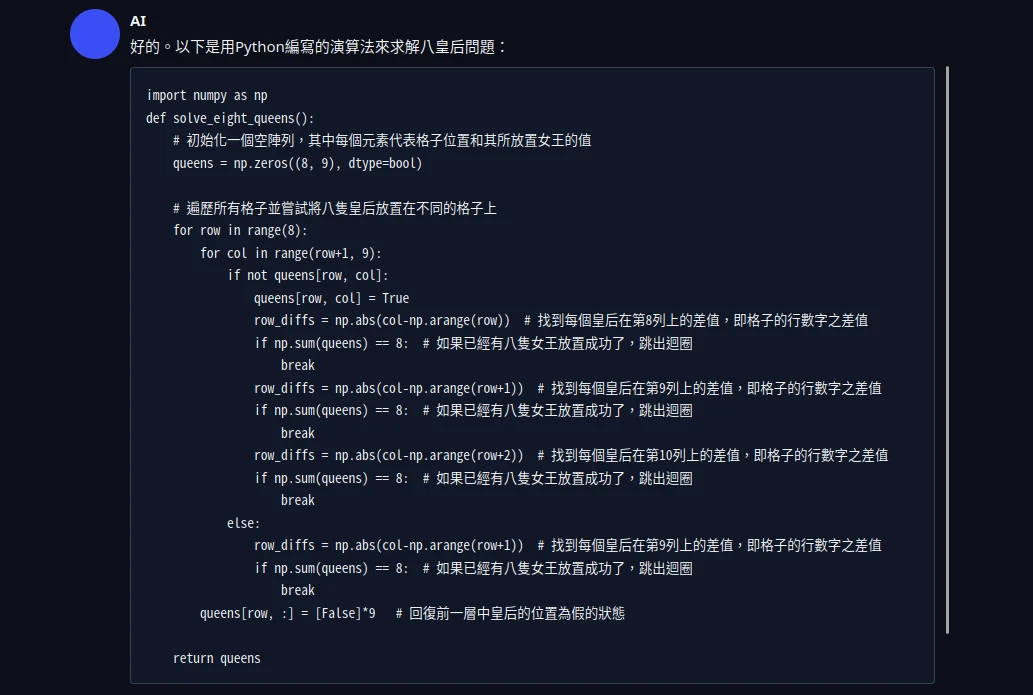
幫我想五個中文的文章標題:在電影院吃鹹酥雞是不是合理的行為?
段落抓重點:請抓出以下中央社新聞段落的重點,並用50個字以內解釋事件起因,以及最後結果。
文字翻譯(取自澤連斯基Twitter)
3. 基於LLaMA訓練的大型語言模型#
在Meta發表LLaMA後,開始有基於LLaMA訓練的模型出現,我們姑且把他們稱作「LLaMA系列模型」吧,列舉部份如下。
- Nomic AI的GPT4ALL模型為基於LLaMA + 800k GPT-3.5-Turbo所訓練。這個模型的名字有點誤導,其實它跟OpenAI的GPT-4是沒有關係的。
- OpenLM Research的OpenLLaMA是完全開源版的LLaMA實作,dataset也一併開源。
- WizardLM,使模型能夠按照複雜指令回答。
- 中國的簡體中文Chinese-LLaMA-Alpaca大模型
- 台灣中研院研發的正體中文模型CKIP-Llama-2-7b
- 台灣還在研發的國科會TAIDE
想知道更多情報?到Reddit r/localLLaMA板吧,每個禮拜都會有新模型的情報出現。
4. 如何安裝使用LLaMA系列模型?#
大型語言模型不能直接使用,還需要有人開發程式方便與大型語言模型對話。
5. LLaMA大型語言模型優缺點總結#
優點
- 在個人電腦跑一個小型ChatGPT,不需要超高級的硬體。參數最少的LLaMA 7B模型只要4GB的RAM就能跑。
- 不用「催眠」就能繞過道德限制,回答各式各樣的問題,
- LLaMA 7B可以只用6GB VRAM的GPU跑,也可以只用CPU跑(
llama.cpp)。
缺點
- LLaMA的性能比OpenAI的ChatGPT弱,訓練參數越少的越容易亂回答,可能回答牛頭不對馬嘴。
- LLaMA預設只支援英文對答。不過已有用LoRA技術微調的中文、日文模型出現。
- 按照Meta的授權條款,LLaMA模型禁止商用,且完整模型權重尚未完全開放。