早在2022年Stable Diffusion出來之時,就有人用ChatGPT生成提示詞方便AI生圖了。
所以我們如法炮製,讓OpenWebUI Ollama在本機跑語言模型生成提示詞,傳給生圖軟體,用Stable Diffusion或FLUX模型在本機生成圖片。
Open WebUI支援連接到Stable Diffusion WebUI或ComfyUI,我使用ComfyUI做示範。
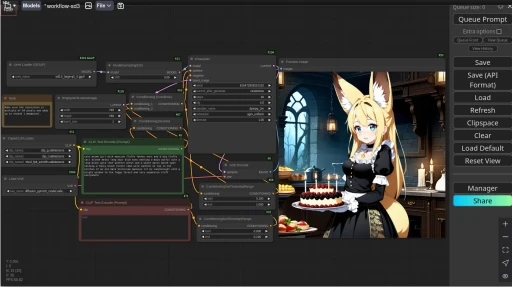
要怎麼做呢?雖然有開發者做了ComfyUI的擴充功能stavsap/comfyui-ollama,可將Ollama對話框加入到ComfyUI工作流作為自訂節點,但是這樣做很醜。
我的構想是,從Open WebUI與語言模型對話,讓其生成提示詞,傳給ComfyUI生成圖片,然後圖片顯示在Open WebUI的聊天欄位。
這樣操作上比較直觀,而且Open WebUI界面較為舒爽,不用在ComfyUI手動拉Ollama節點看著義大利麵條操作。
1. 架設ComfyUI服務 #
-
首先,安裝ComfyUI,Linux可用Python手動安裝ComfyUI或者使用Docker裝ComfyUI
-
接著將要用的ComfyUI工作流存檔,因為Ollama請求ComfyUI只是單純的文生圖,所以使用ComfyUI內建的文生圖工作流即可。
-
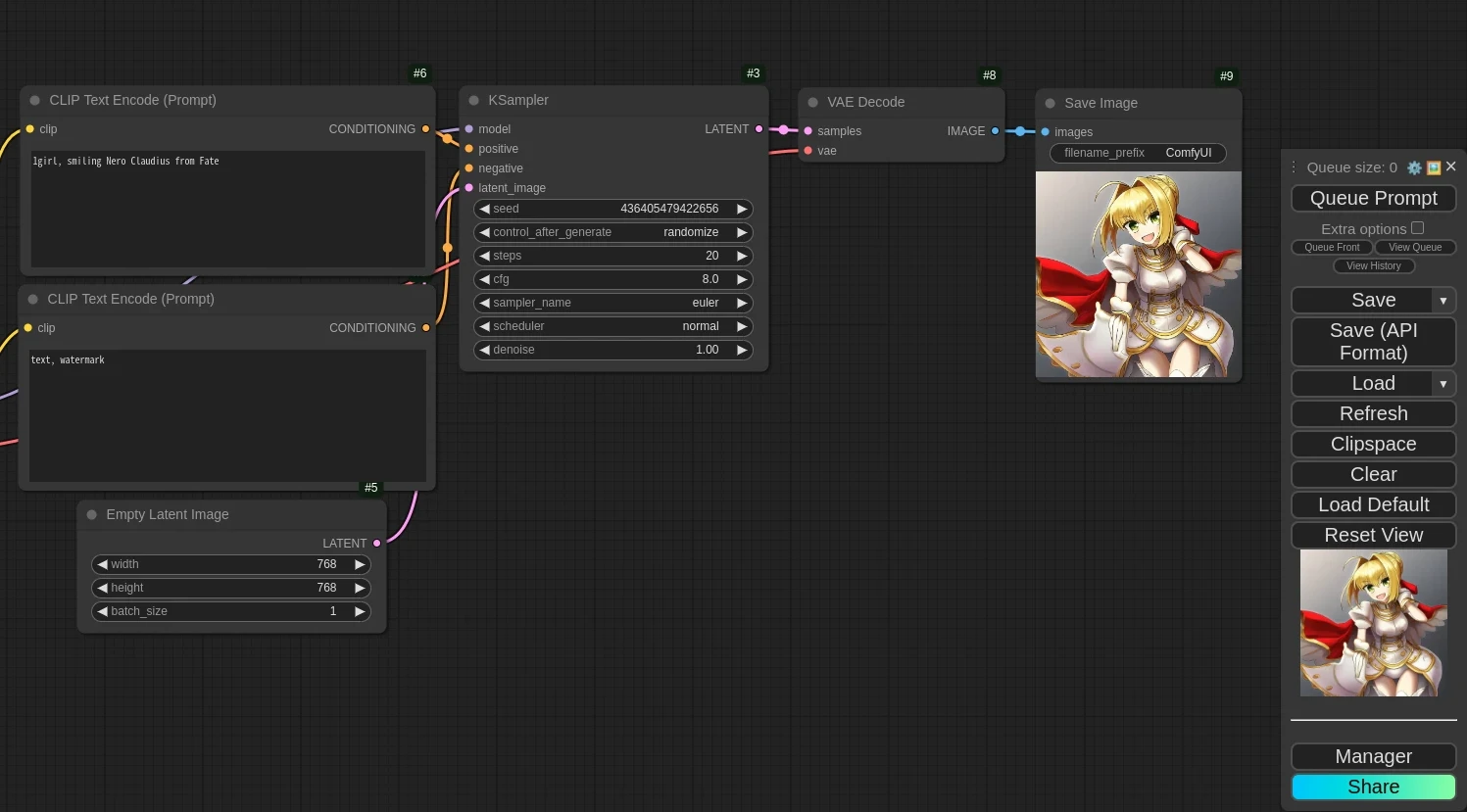
嘗試跑一次,確認該工作流能成功生圖。這裡我使用的是SDXL模型。
-
點ComfyUI設定,啟用Dev Mode
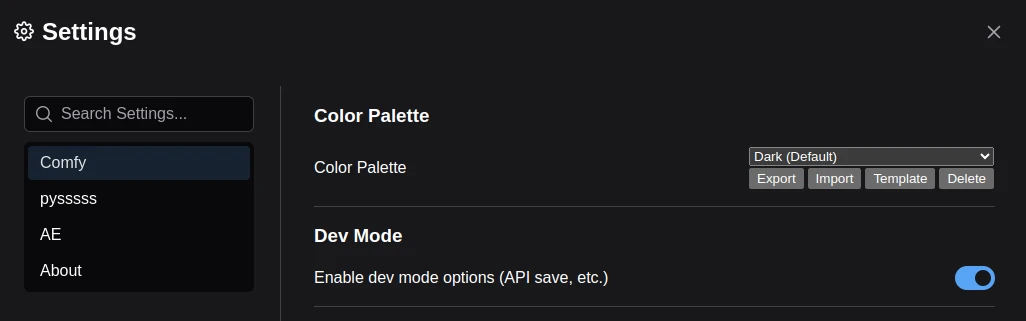
-
點選Save (API Format),得到
workflow_api.json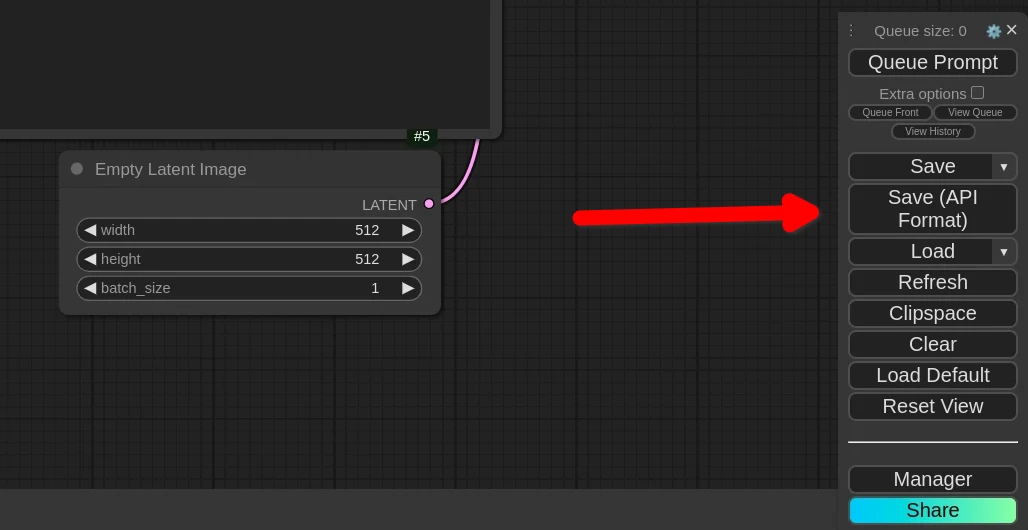
2. 選用生成提示詞的Ollama模型 #
一般的Gemma、LLaMA語言模型應該都能用來生成提示詞。
不過,要求精確的話,網路上還有專為生成提示詞特化的模型,他們可能比較聽話,不會生成提示詞以外的東東,例如llama3_ifai_sd_prompt_mkr_q4km
3. 給Open WebUI啟用AI生圖 #
-
登入Open WebUI,於系統管理員設定啟用Image Generation,選ComfyUI,再輸入ComfyUI伺服器網址,如果是在架在同一台電腦就輸入
http://localhost:8188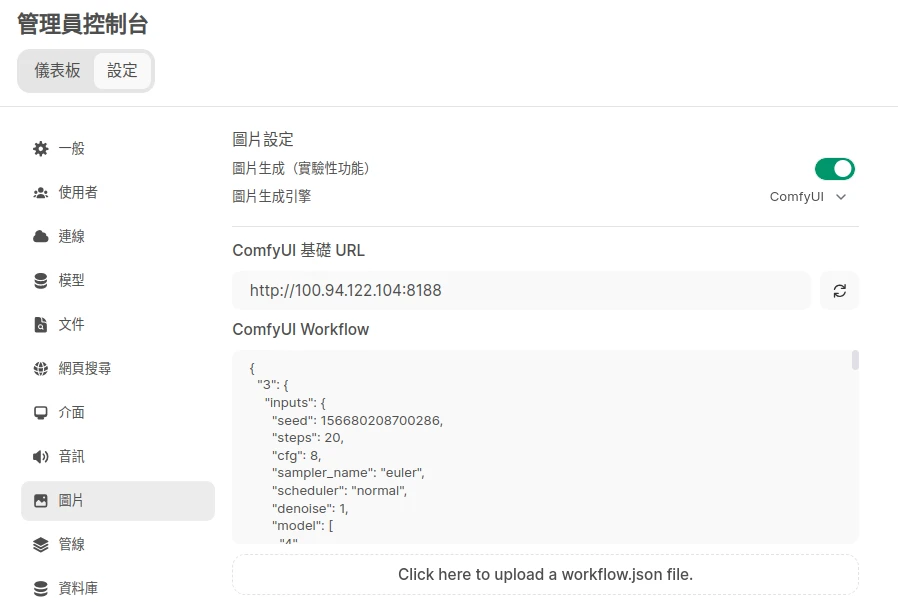
-
上傳ComfyUI工作流
workflow_api.json,會印出JSON。依照上述JSON的設定,在下面綠色欄位填寫每個節點的Node ID,例如這裡Prompt對應CLIPTextEncode的欄位,就填6。JSON裡面的Prompt欄位應該要是空白的。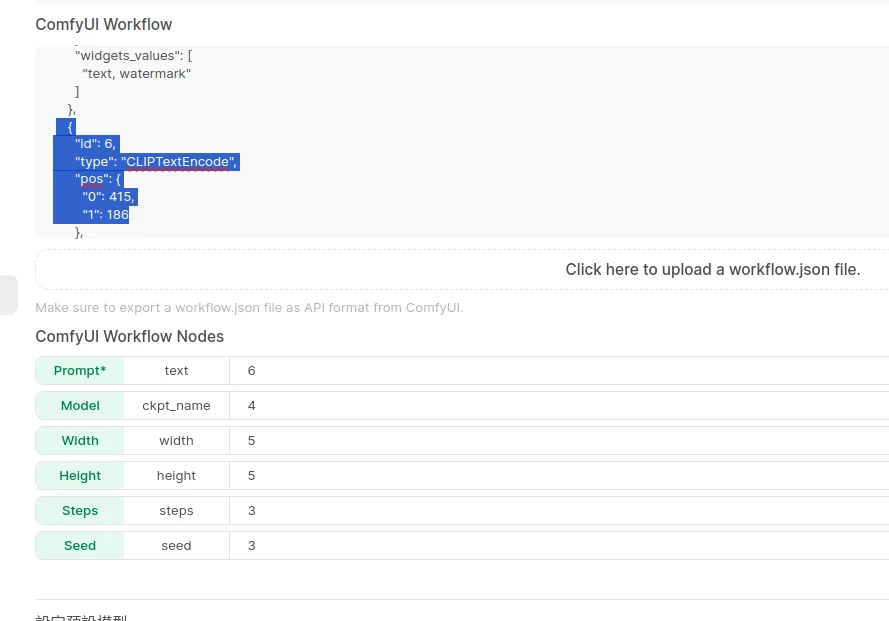
-
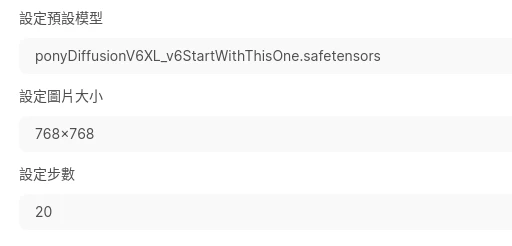
下面設定要生圖的模型檔、圖片大小、步數。點選儲存。預設模型欄位,若Stable Diffusion模型檔非ckpt而是gguf的話,就直接填寫檔案名稱。
4. 如何指示語言模型生成圖片 #
其實任何一句語言模型的回答都能當作生圖的提示詞,不過Stable Diffusion模型偏好特定格式,所以我們要請語言模型生成提示詞。
- 輸入訊息,以
Write a prompt for句子開頭,中間插入你要的場景,最後加上一句Only response the prompt for the image and nothing else.。例如:
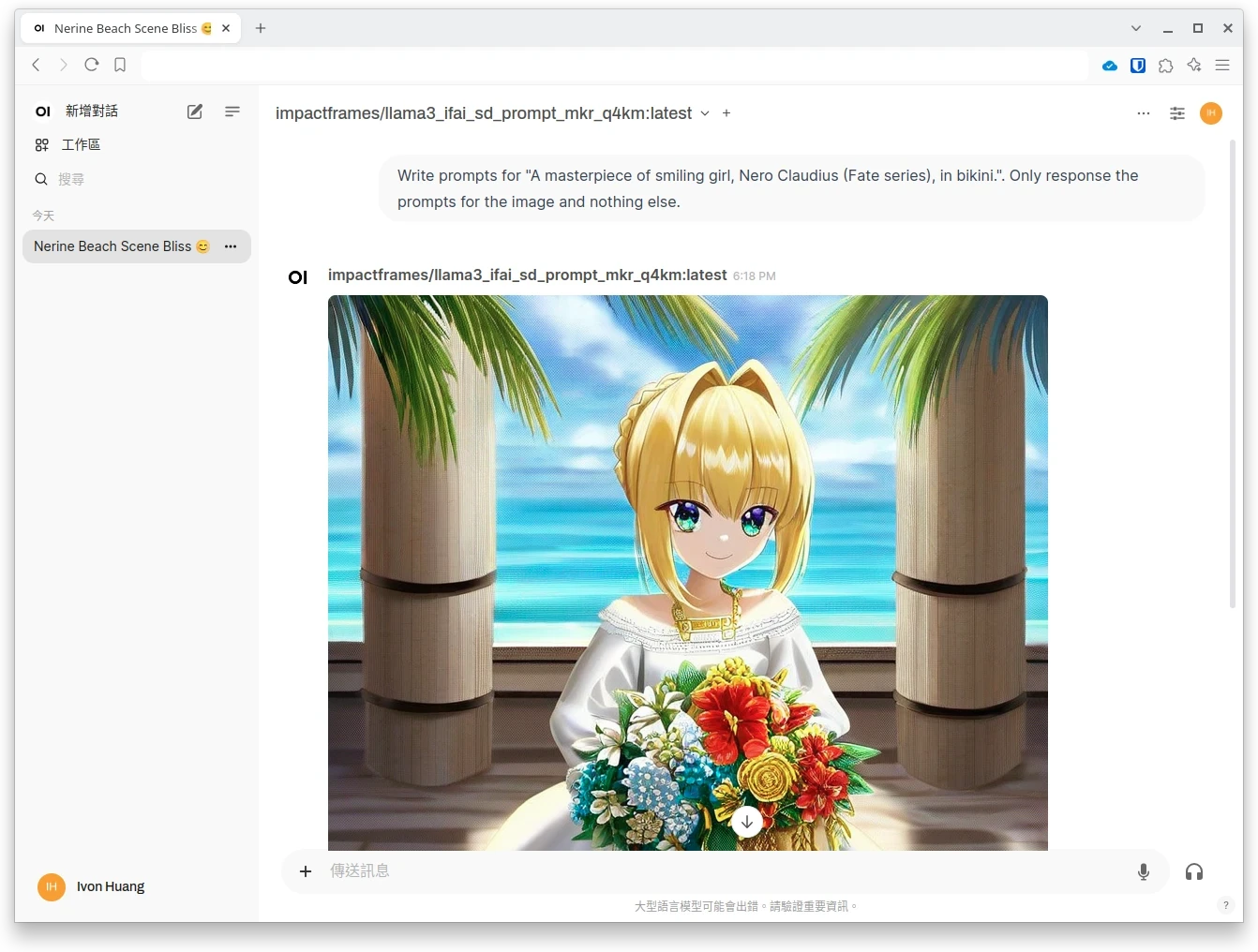
Write prompts for "A smiling girl, Nero Claudius (Fate series), in bikini.". Only response the prompts for the image and nothing else.-
等語言模型回話之後,點選下方「生成圖片」的按鈕,將生圖請求傳給ComfyUI

-
生完圖後就會顯示在OpenWebUI的對話了。(是的,我知道這張圖生歪了,AI還需要多調校😈)