這篇文章Ivon將要用Linux的Docker部署兩個服務,簡單在電腦跑起大型語言模型。
第一個是「Ollama」,開源的大型語言模型執行器,基於llama.cpp開發,能夠執行LLaMA、Mistral、Gemma等開源語言模型。Ollama主要使用CPU運算,必要時再用GPU加速。不過它只有純文字界面,打指令操作頗麻煩的,所以才要裝Open WebUI。
第二個「Open WebUI」是一款多功能的網頁前端,最早叫做Ollama WebUI,它能給Ollama裝上一個漂亮的界面。
Open WebUI很類似ChatGPT網頁版,界面簡潔功能又多,例如聊天紀錄、AI繪圖、圖片辨識、讀取PDF、RAG整理資料、Google搜尋、自訂AI角色等等,可以立即用於生產環境。
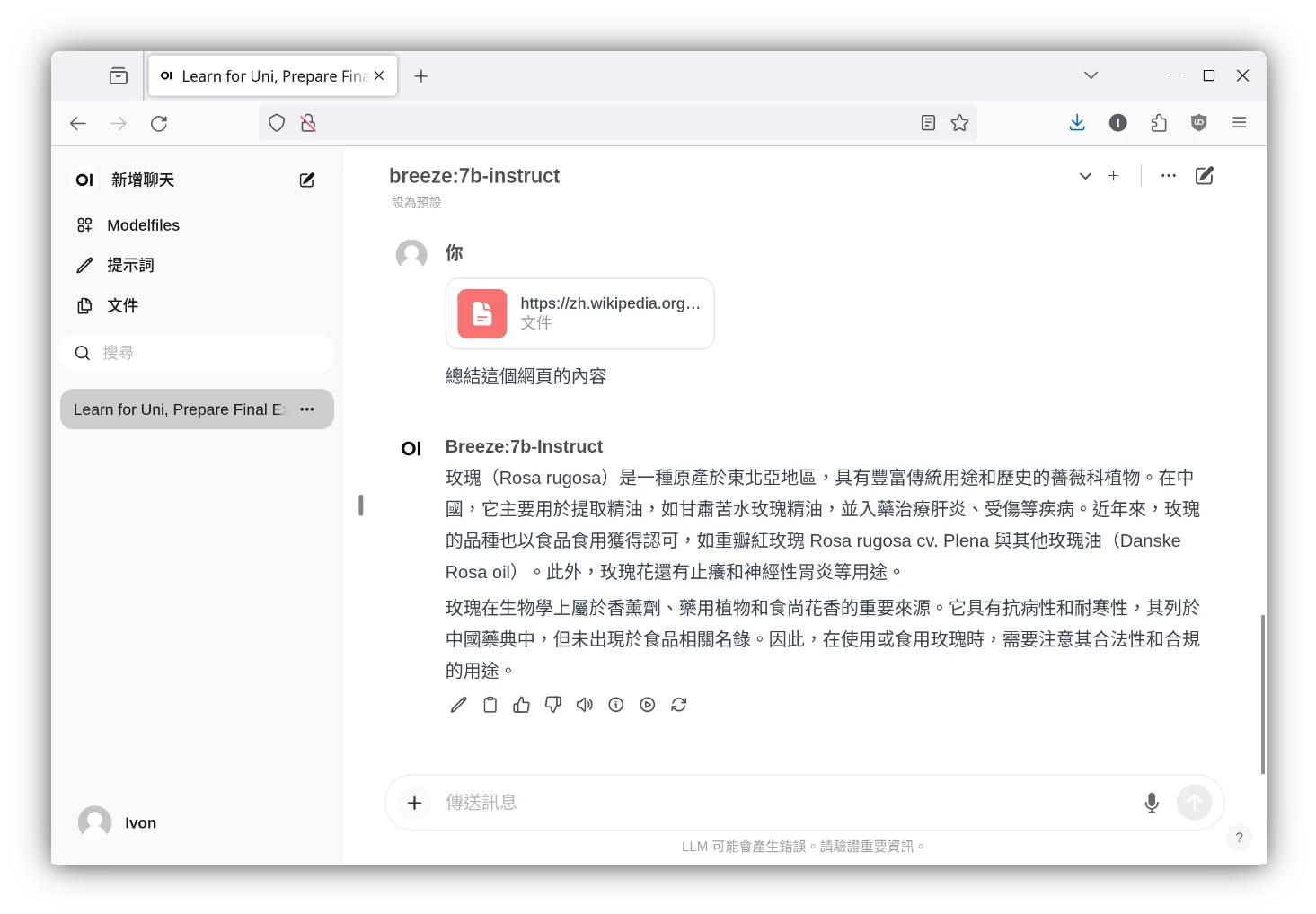
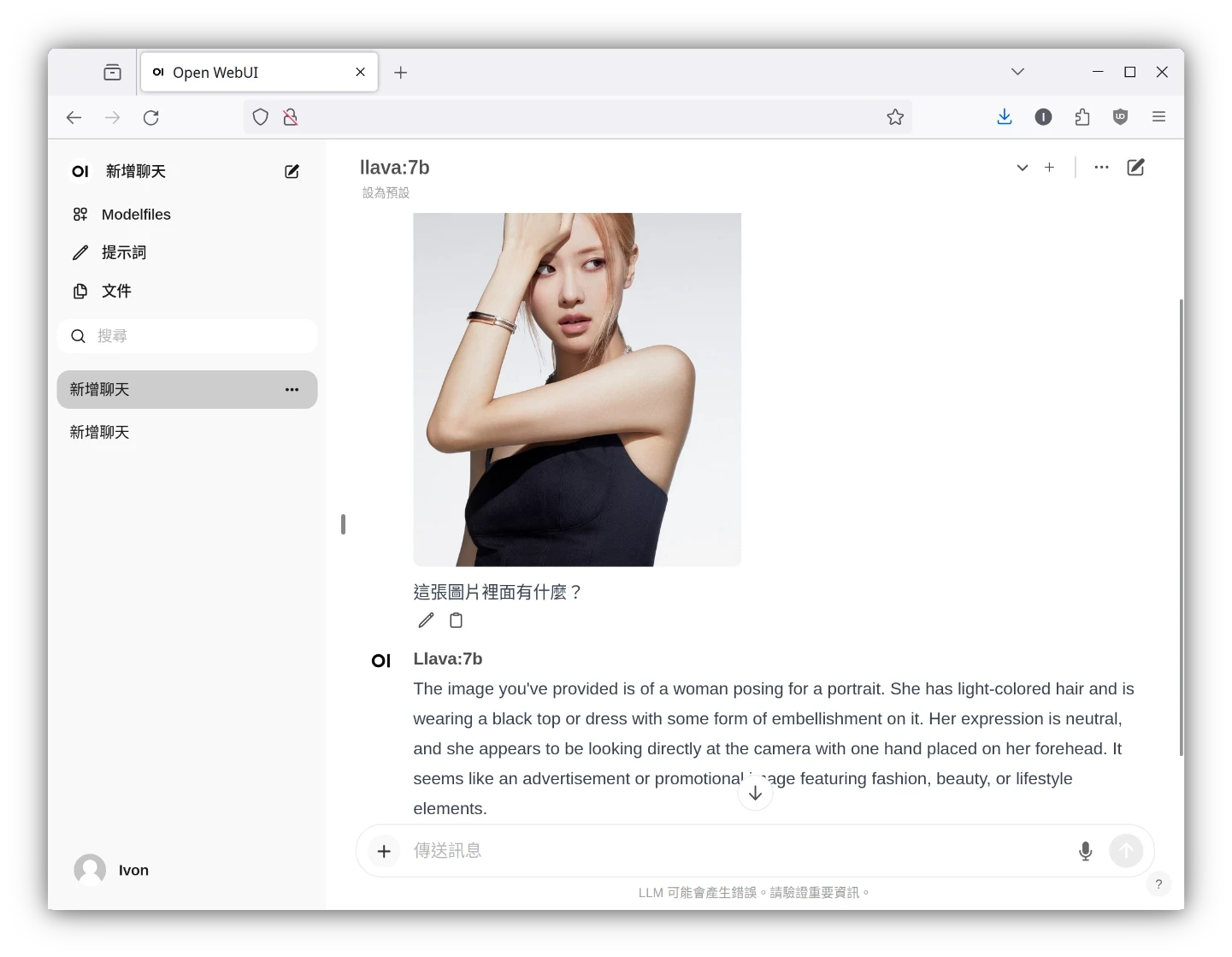
在Linux安裝Ollama教學一文Ivon提過,Ollama作者提供的指令稿會幫你安裝Ollama二進位執行檔到Linux系統,並用Systemd管理服務。現在我們要把Ollama給容器化,這樣能夠大幅簡化架服務的流程,同時方便將Ollama與Open WebUI服務串接在一起。
此外,用Docker部署Ollama之後,還是能夠使用純文字指令下載模型的,Ollama的API伺服器能開放給Open WebUI以外的服務存取。Ollama並沒有限定一定要跟Open WebUI一起用,它能夠單獨執行,並跟其他語言模型軟體連線。我選擇Open WebUI主要是因為它的界面漂亮又多功能。
1. 撰寫docker-compose#
Open WebUI為前端,Ollama為後端。主要負責運算的部份是Ollama,它會在背後透過llama.cpp執行語言模型。建議準備Intel i5以上的四核心CPU,8GB RAM以上等級的電腦。如果有Nvidia GPU更好,VRAM至少要有4GB。
- 我們要將Ollama容器化,若你已經用指令稿安裝過Ollama了,請將服務關閉,例如Ubuntu的指令就是:
sudo systemctl disable --now ollamaOllama預設只用CPU跑,要更快的生成速度得使用Nvidia GPU加速。要在Docker裡面跑CUDA,請安裝Nvidia Container Toolkit
複製Open WebUI儲存庫
git clone https://github.com/open-webui/open-webui.git
cd open-webui- 新增.env環境變數
cp .env.example .envOpen WebUI開發者已經幫我們寫好了docker-compose,可以直接用他們的範本跑服務。所有的服務都寫在
docker-compose.yaml檔案裡面,裡面會啟動Ollama和Open WebUI兩個服務,並用Docker volume儲存資料。使用該docker-compose啟動Open WebUI容器服務,擇一指令啟動:
# 預設是純CPU計算:
docker compose -f docker-compose.yaml up -d
# 若要使用Nvidia GPU加速,額外加上`docker-compose.gpu.yaml`這個檔案:
docker compose -f docker-compose.yaml -f docker-compose.gpu.yaml up -d
# Ollama的API伺服器只有Open WebUI能存取,如果你有其他服務需要使用Ollama,請用這個指令,啟動額外的API伺服器:
docker compose -f docker-compose.yaml -f docker-compose.gpu.yaml -f docker-compose.api.yaml up -d- 這裡提一下,其實三個檔案的內容可以自行改寫,合併成為單一的docker-compose.yml檔案,例如:
services:
ollama:
volumes:
- ollama:/root/.ollama
container_name: ollama
pull_policy: always
tty: true
restart: unless-stopped
image: ollama/ollama:${OLLAMA_DOCKER_TAG-latest}
ports:
- ${OLLAMA_WEBAPI_PORT-11434}:11434
deploy:
resources:
reservations:
devices:
- driver: ${OLLAMA_GPU_DRIVER-nvidia}
count: ${OLLAMA_GPU_COUNT-1}
capabilities:
- gpu
open-webui:
build:
context: .
args:
OLLAMA_BASE_URL: '/ollama'
dockerfile: Dockerfile
image: ghcr.io/open-webui/open-webui:${WEBUI_DOCKER_TAG-main}
container_name: open-webui
volumes:
- open-webui:/app/backend/data
depends_on:
- ollama
ports:
- ${OPEN_WEBUI_PORT-3000}:8080
environment:
- 'OLLAMA_BASE_URL=http://ollama:11434'
- 'WEBUI_SECRET_KEY='
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stopped
volumes:
ollama: {}
open-webui: {}- 日後更新所有容器映像檔的指令:
docker compose pull2. Open WebUI下載語言模型#
用瀏覽器開啟
http://Linux電腦IP:3000,進入網頁,註冊一個帳號(資料皆是存在本機,不會傳輸給第三方),登入Open WebUI
點選左下角的帳號大頭貼 → 設定 → 管理員設定 → 連線,點選Ollama旁邊的扳手圖示,輸入模型ID下載模型。請參閱著名的開源大型語言模型列表。模型ID到Ollama官網查找,例如我用台灣正體中文模型
Llama-3-Taiwan-8B: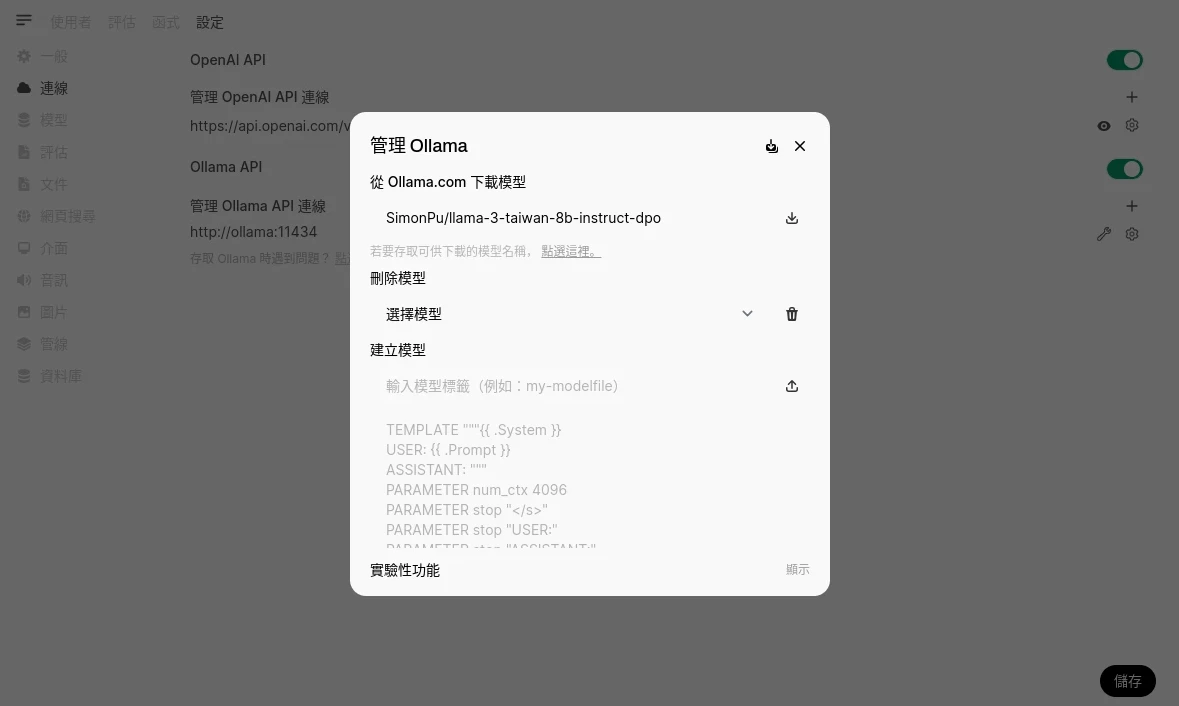
也可以使用
ollama pull指令來下載模型:
docker exec -it ollama ollama pull SimonPu/llama-3-taiwan-8b-instruct-dpo- 所有下載的模型都會存在Ollama容器的Docker volume之中。
3. 修改Open WebUI的GPU加速設定#
3B以上資料量的語言模型,純用CPU跑會非常慢。
如果有設定Nvidia GPU加速,那麼Ollama會自動分配一些資源給GPU,加速語言模型的回應速度。不過有時候Ollama只用CPU跑,白白浪費GPU資源,這個時候可以手動指定要offload多少層給GPU計算。
要offload多少層具體多少取決於GPU的VRAM多大,比如我的VRAM只有4GB,那上限就是20層左右。
點選Open WebUI的設定,點選一般,展開進階參數,設定num_gpu的數值。至於num_threads的數值是設定要使用多少CPU執行緒,可以的話也設定高一些。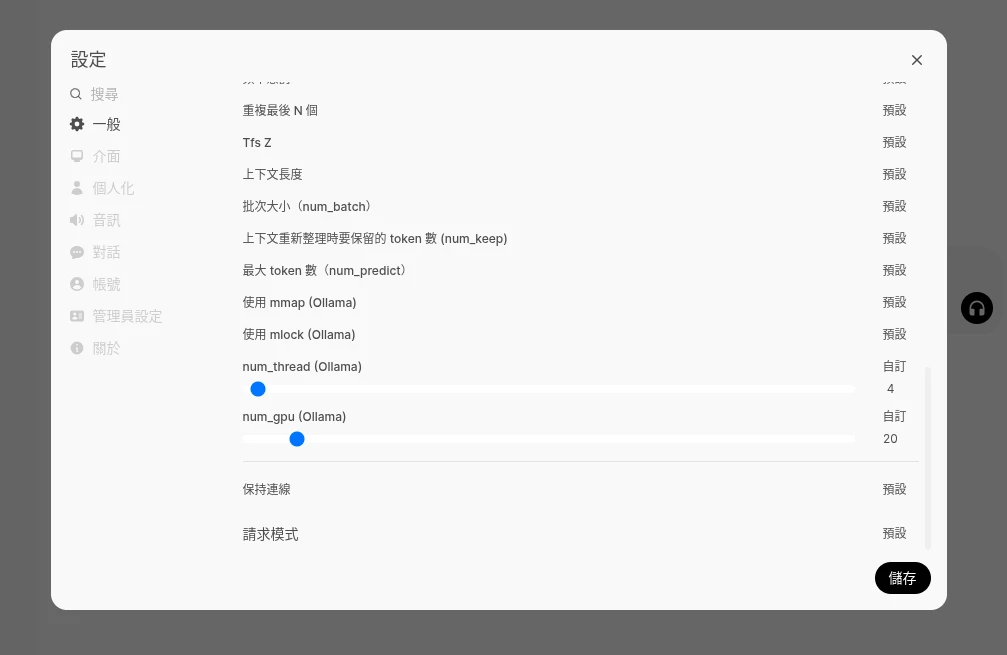
或者進入Open WebUI管理員設定 → 編輯模型,個別設定該模型要使用多少GPU。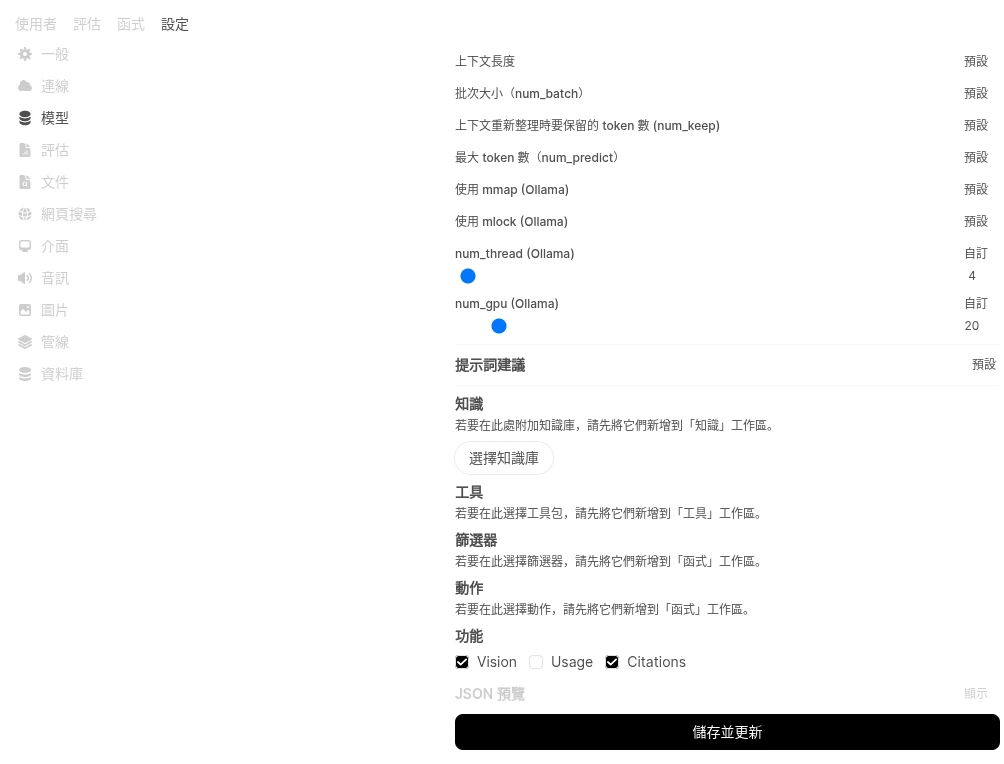
在語言模型載入的時候執行docker exec -it ollama ollama ps指令,查看模型使用了多少CPU和GPU。
4. 外網存取Open WebUI網頁#
點左上角選取要使用的模型,即可開始對話!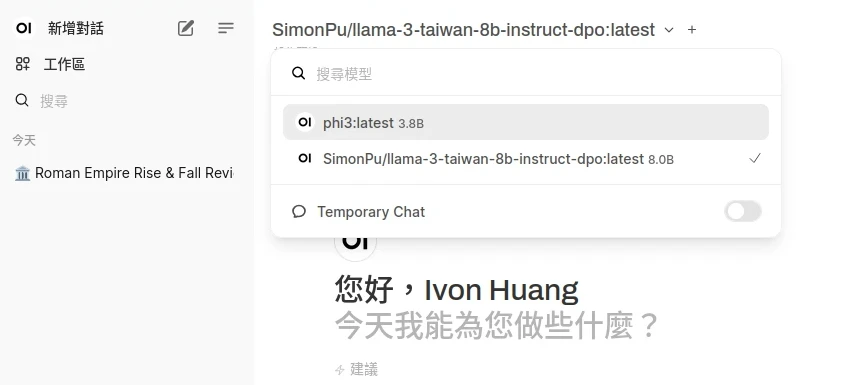
如何從外部網路存取Open WebUI?設定內網穿透軟體,即可用虛擬區域IP存取Open WebUI,界面會自動隨著螢幕大小變化。
值得注意的是:Open WebUI預設只有HTTP,部份功能需要HTTPS才能使用,例如存取裝置麥克風與相機。這個你得用自簽SSL憑證解決,例如使用Tailscale Funnel或者Cloudflare Tunnel


