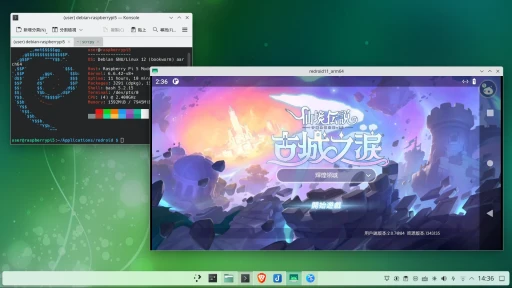
Raspberry Pi也能跑大型語言模型(LLM)嗎?可以,甚至能架個網頁聊天服務呢。
如下圖,在Raspberry Pi跑語言模型,並透過手機瀏覽器與之互動。
Ivon使用的板子為Raspberry Pi 5,加裝風扇。軟體部份採用Ollama的開源解決方案,以它為中心即可執行各種開源語言模型,包括LLaMA、Gemma、Mistral、Phi等等。
要發揮Ollama的更多功效,就是讓它與其他程式整合了吧,Ollama能作為Home Assistant的其中一個服務後端,用於控制智慧家庭的家電,參見官網說明。
1. 部署Ollama與Open WebUI服務#
我使用Raspberry Pi OS 12跑Docker。
執行指令取得樹莓派區域IP
ip addr用電腦或手機連線到
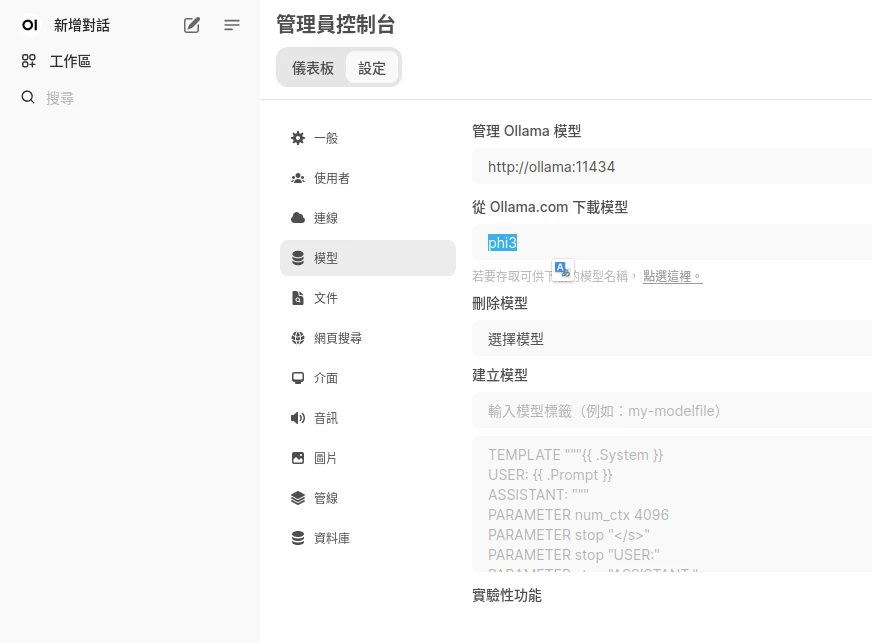
http://樹莓派IP:3000登入Open WebUI我們再從Open WebUI的管理員控制台下載模型,考慮到性能,選擇Microsoft Phi-3。
2. 看看Ollama效能如何#
我們以Ollama指令進入純文字對話模式,測試生成速度:
docker exec -it ollama ollama run phi3 --verbose經測試,Raspberry Pi 5跑3B參數的Phi-3小型語言模型速度還行,10秒內就有回復,速度能達到3 token/s。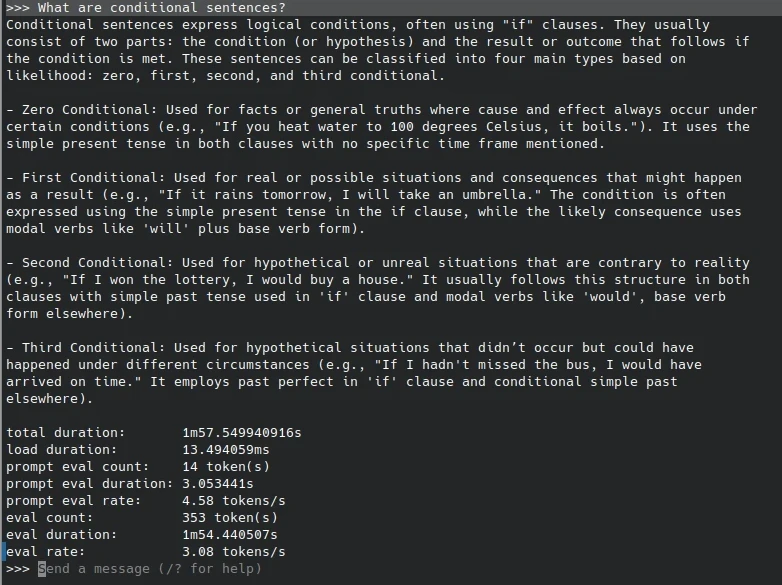
最大極限是跑7B參數的模型,可,Raspberry Pi 5只有8GB RAM,跑7B以上模型很容易記憶體不足,得用dphys-swapfile指令設定變數CONF_MAXSWAP,加大系統的SWAP才夠跑。不過即使如此,7B模型回應速度也是十分之緩慢,可能要把SD卡換成SSD才能加快模型載入速度。
還有,目前Ollama在Raspberry Pi無法使用GPU加速,全部都用CPU算,模型一跑起來CPU全滿,風扇就起飛了。要用Vulkan加速的話倒是有MLC LLM
從實用性考慮,Raspberry Pi的硬體比較適合跑訓練參數在1B以下的模型,例如Google EmbeddingGemma,這樣才能得到比較即時的回應速度。