Ollama讓你透過簡單的幾個步驟,即可將大型語言模型部署到Linux、macOS、Windows,並於本機離線執行。

Ollama不是單純地LLM,而是協助你快速安裝各種大型語言模型的一個開源軟體。
爲什麼要用Ollama?
本節Ivon介紹Ollama的優點。之後的文章我們再來討論如何安裝Ollama,
自從離線大型語言模型LLaMA問世以來,便有很多前端程式出現,例如Text Generation WebUI、Serge、Dalai、LangChain,讓使用者在自己的電腦離線跑LLM,保障隱私權。
不過隨着開源模型的多樣化,大型語言模型部署變得越來越複雜,例如Text Generation WebUI就要調一堆參數,辨別它是用GPU運算還是llama.cpp的模型,用起來不直覺。
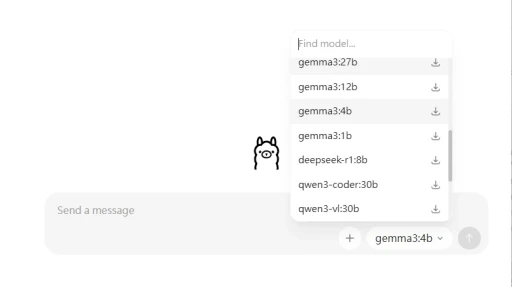
Ivon認為,要簡化部署難度就用Ollama吧,這是用Go語言寫成的程式,將執行大型語言模型所需的東西封裝成單一執行檔,只要一行指令就能讓大型語言模型在你的電腦跑起來,用指令與AI互動。
它背後採用的是一個更早期的專案llama.cpp的技術。Ollama簡化了部署的過程,讓人比較容易上手。
我覺得Ollama是很智慧的軟體,它會自動偵測系統可用的VRAM分配給語言模型,讓CPU和GPU協同工作,即使是4GB VRAM的顯示卡也能夠順暢跑語言模型。
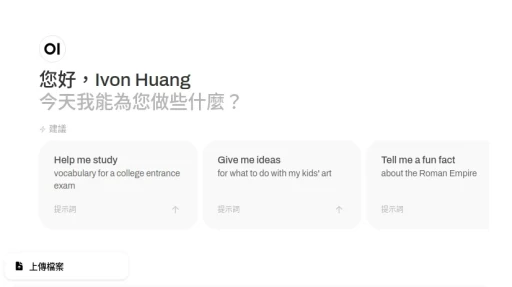
嫌Ollama指令操作很麻煩?你可以裝圖形界面!Ollama可以搭配「Open WebUI」操作,界面設計十分類似ChatGPT。
你可以用Open WebUI聊天、跑AI繪圖、辨識圖片、執行RAG檢索增強生成、讓它整理PDF檔案內容、搜尋網頁等。
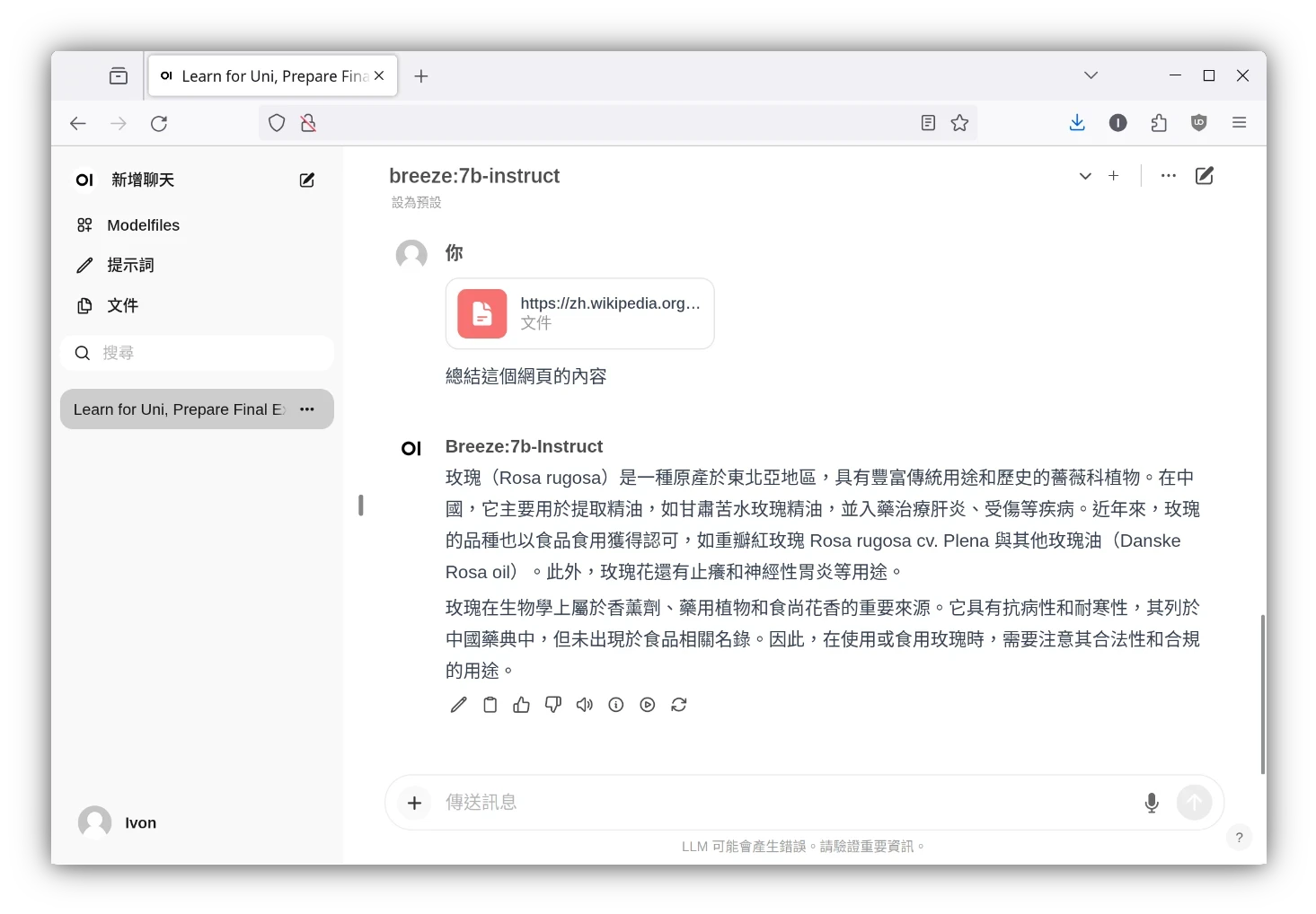
Ollama設計的理念是預設模式很簡單,要折騰也行的那種。使用者可以用類似Dockerfile的方式自訂Ollama的模型參數,快速建立自訂模型。
此外,Ollama不只是設計成一個傻瓜式的大型語言模型軟體而已!
Ollama是開放原始碼的軟體,它提供REST API,讓開發者可以在其他程式輕鬆整合Ollama,作為其他AI軟體的後端服務。
比如LM Studio可以連接到Ollama。
功能更複雜的「LangChain」軟體亦可以搭配Ollama使用。