檢索增強生成 (RAG) 是能夠擴充語言模型知識量的技術,在Open WebUI裡面這個功能叫做知識庫(Knowledge Base)
如果你已經玩過Open WebUI,應該會發現網頁界面是能夠上傳單個檔案叫語言模型分析的。

除了在對話的時候即時上傳檔案請語言模型分析之外,你也可以預先準備一些資料,上傳到Open WebUI的知識庫,並新增以該知識庫為主的語言模型,擴充它的腦容量。這樣語言模型在與你問答的時候,便會自動參考知識庫的檔案內容,有助於產生更精確的答案。
例如問:「游良福是誰?」預設情況下LLaMA 3模型沒有收錄他的資料,就會無法回答,或者產生幻覺亂生成答案。

但在Ivon準備幾份有關他事蹟的檔案給他掃描後,語言模型便能依照該檔案內容回答,還會指出他參考了哪些文件。

RAG跟上網搜尋有什麼差呢?雖然Open WebUI是能讓語言模型整理搜尋結果,但是參差不齊,撈到的資料可能會是道聽塗說。而你自己準備的資料,就是已經篩選過,精度較高又品質好的資訊。
1. 準備RAG資料的前提#
Open WebUI接受許多檔案格式,舉凡txt、markdown、pdf、parquet都可以,為了方便處理我們以txt為例。
準備檔案前要注意文字長度。上下文(context length)越長,佔用資源越大。Ollama預設的上下文長度是2048個token,跑LLaMA 3 8B的模型運算的時候大約會佔4GB VRAM和8GB RAM。所以這限制了輸入檔案的長度,所有檔案總計不能超過1024個中文字元,否則語言模型會無法吸收。即使你用支援128K token的LLaMA 3模型,也會被Ollama的上下文限制住。
除非你在Open WebUI的網頁 → 管理員控制台 → 模型 → 進階參數,修改「上下文長度」,強制指示Ollama使用超過2048個token,才能夠搜尋更長的文本。Open WebUI的文件是建議調到8000以上。
相應的VRAM與RAM佔用會上升,請注意你的系統是否能負荷。
2. 設定Open WebUI的RAG#
以Docker架設Open WebUI
以Docker架設內容擷取引擎Apache Tika,範例docker-compose如下:
services:
tika:
image: apache/tika:latest-full
restart: on-failure
ports:
- "9998:9998"Open WebUI內建的嵌入模型不好用,點選Open WebUI左下角,切換到管理員設定 → Ollama模型,下載嵌入模型
mxbai-embed-large
切換到文件頁面,設定嵌入模型引擎為Ollama,將嵌入模型改為
mxbai-embed-large。內容擷取引擎設定為連線到Apache Tika伺服器。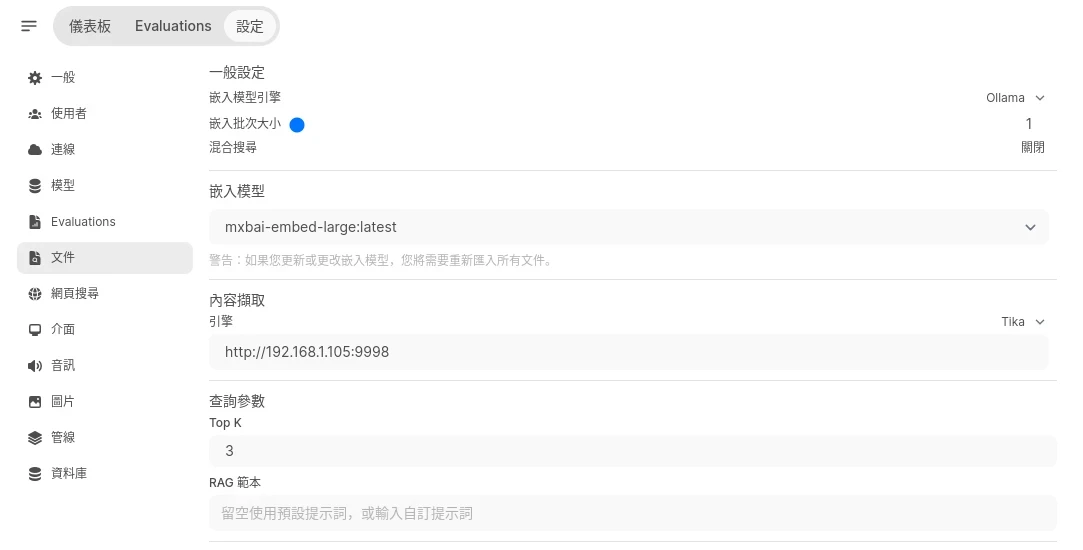
再來注意查詢參數Top K的數值,代表一次最多能搜尋幾個檔案,預設是3個。若你需要強制語言模型查看所有檔案,請設定跟你的檔案數目相同,否則搜尋時可能會跳過一些檔案導致不準確。
3. 新增知識庫與自訂語言模型#
到Open WebUI主畫面,左上角工作區 → 知識,點選新增知識庫
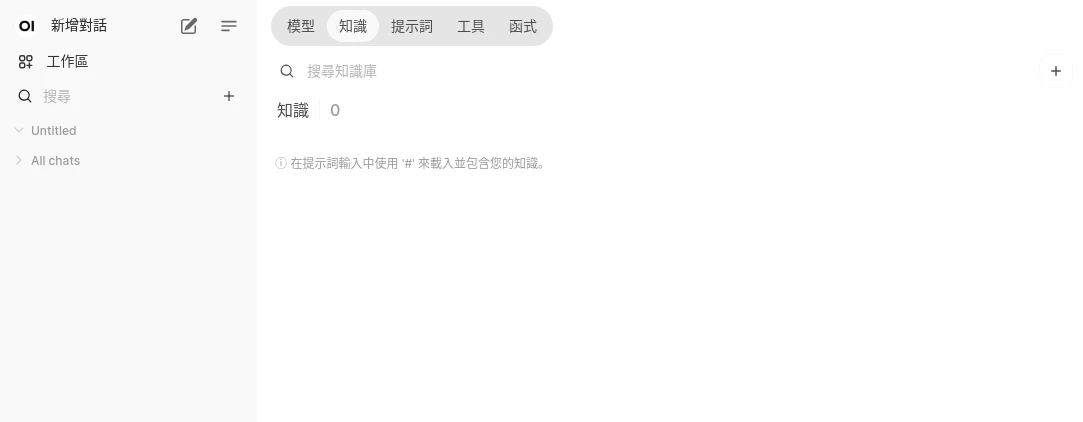
在這裡上傳你要的txt檔案。上傳的檔案會經過處理後,儲存到向量資料庫。這裡的知識庫是可以隨時變動的,日後上傳到知識庫的新檔案都能讓語言模型取用。

接著切換到模型頁面,點選新增自訂語言模型,以現有的模型為基礎,這裡使用LLaMA 3。
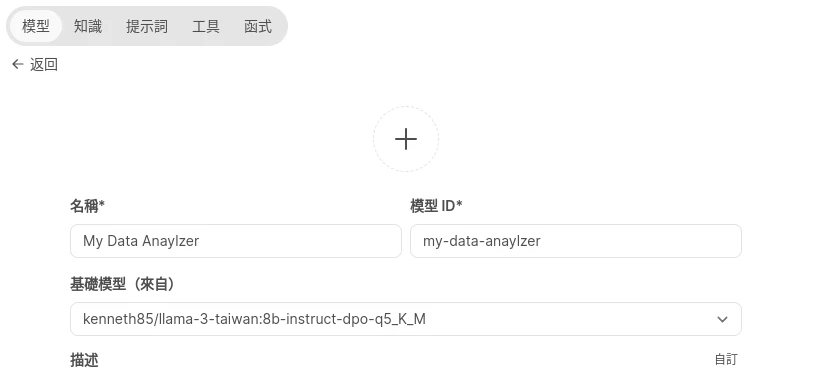
在下面選取使用剛剛建立的知識庫。
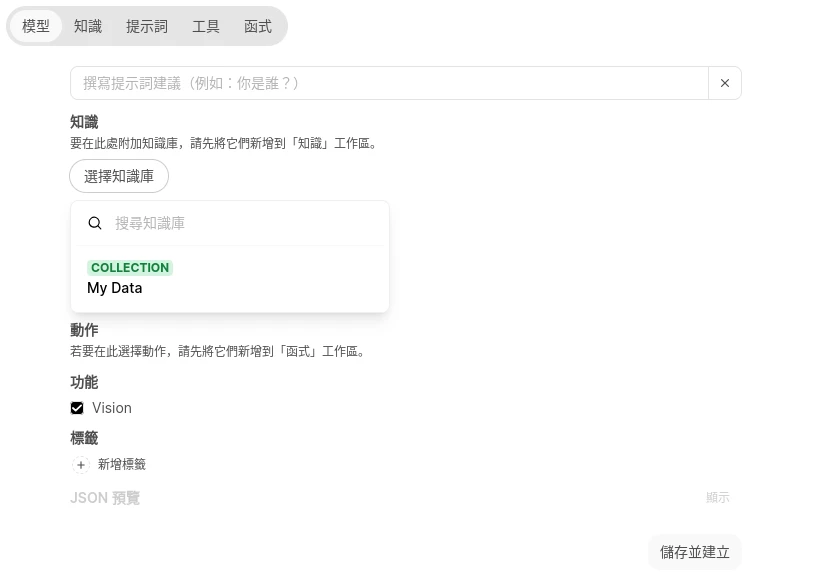
嘗試與自訂語言模型問答,它就會優先搜尋知識庫的內容來回答。


如果你希望搜尋更長上下文,點選側邊的Ollama設定,調高上下文長度。