Open WebUI提供文字轉語音的功能,可以讓你在與語言模型對話的時候聽到對方唸出來的聲音。這個適合用在與AI即時對話,搭配Open WebUI的麥克風輸入功能,便能與AI即時聊天對話,再用文字儲存對話紀錄。
用途為何?或許可以將文字轉語音的技術用於語言學習,與語言模型練習對話。或者讓Open WebUI上網搜尋資訊,並讓它把內容朗讀出來。
文字轉語音的服務也適合用在Open WebUI的視訊模式,讓語言模型能夠即時回應它所看的東西,並唸出來給你聽。
相較於語音轉文字(STT)只有Whisper AI一種選項,Open WebUI文字轉語音(TTS)支援的服務非常多元。
下面Ivon主要探討本機執行的文字轉語音方案,線上服務次之。
1. Open WebUI支援的文字轉語音服務 #
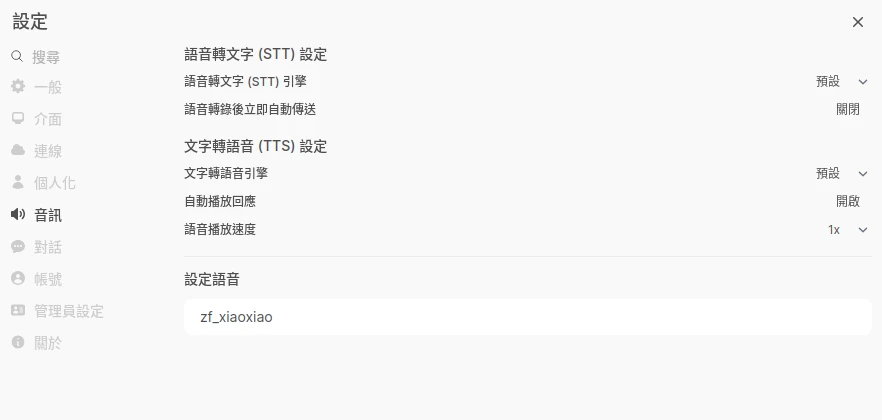
點選Open WebUI管理員設定 → 音訊,進入文字轉語音設定。
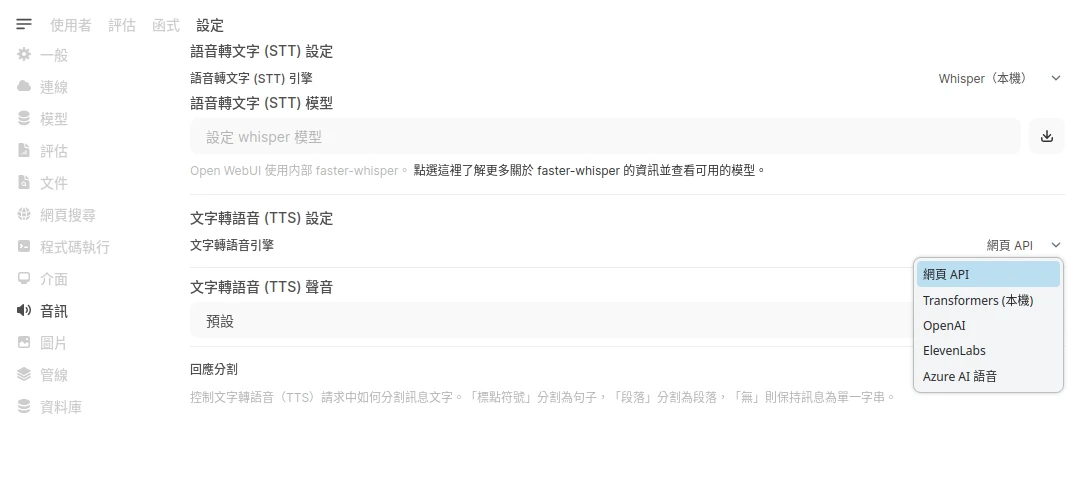
網頁API: 使用作業系統提供的TTS,例如Windows為Microsoft TTS、Linux為Speech Dispatcher(僅限Firefox)、Android為Google TTS、iOS為。
Transformer: 本機執行,使用SpeechT5或CMU Arctic嵌入模型。
OpenAI: 使用OpenAI提供的線上文字轉語音服務。亦可以使用模擬OpenAI端點的服務,例如openai-edge-tts、Kokoro-FastAPI、OpenedAI Speech。
ElevenLabs :利用ElevenLabs的API合成語音。
Azure AI: 使用Microsoft Azure線上服務合成語音。
選一個使用就可以了。
這些服務當中,網頁API應該是最簡單的方案,計算幾乎不耗費資源。但依賴客戶端的TTS服務來發出聲音,而非從Open WebUI網頁傳送音訊,故應該考慮其他方案。
有些本機服務是參照OpenAI的端點設計的,所以他們設定方式都大同小異。
例如openai-edge-tts封裝了Azure AI,支援中文,而且還支援台灣國語的發音,雙語混合。但它其實不是在本機運算,而是封裝了Azure AI的免費線上服務。
Kokoro-FastAPI算是不吃資源,品質尚能接受的方案,它封裝了Kokoro-82M模型,支援英文與中文語音(但不能雙語混合)。計算時耗費的CPU與GPU資源非常低。
再看看OpenedAI Speech,封裝了PiperTTS與Coqui XTTS模型,支援多語言。Coqui XTTS還有聲音複製功能,但GPU就至少要4GB VRAM才能跑了。
2. 架設Kokoro-FastAPI服務 #
Open WebUI內建的「Kokoro.js」僅支援英文,所以要另外跑一個Docker服務才有中文語音。
Kokoro-FastAPI提供CPU與GPU執行的版本,這邊以GPU版本為例子。
-
容器內使用Nvidia CUDA加速,需要安裝Nvidia Container Toolkit
-
依照Kokoro-FastAPI指示設定,docker-compose範例如下,讓容器能存取Nvidia GPU。這一段內容可以跟Open WebUI的docker-compose寫在一起。
name: kokoro
services:
kokoro-fastapi-gpu:
ports:
- 8880:8880
image: ghcr.io/remsky/kokoro-fastapi-gpu
restart: always
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities:
- gpu-
啟動服務之後,開啟
http://localhost:8880/web,嘗試進入Kokoro的網頁界面,查看可用語音。因為使用OpenAI端點的格式通訊,Open WebUI端沒辦法指定語言,所以得從這裡記住中文語音的名字,例如zf_xiaoxiao是中文女聲。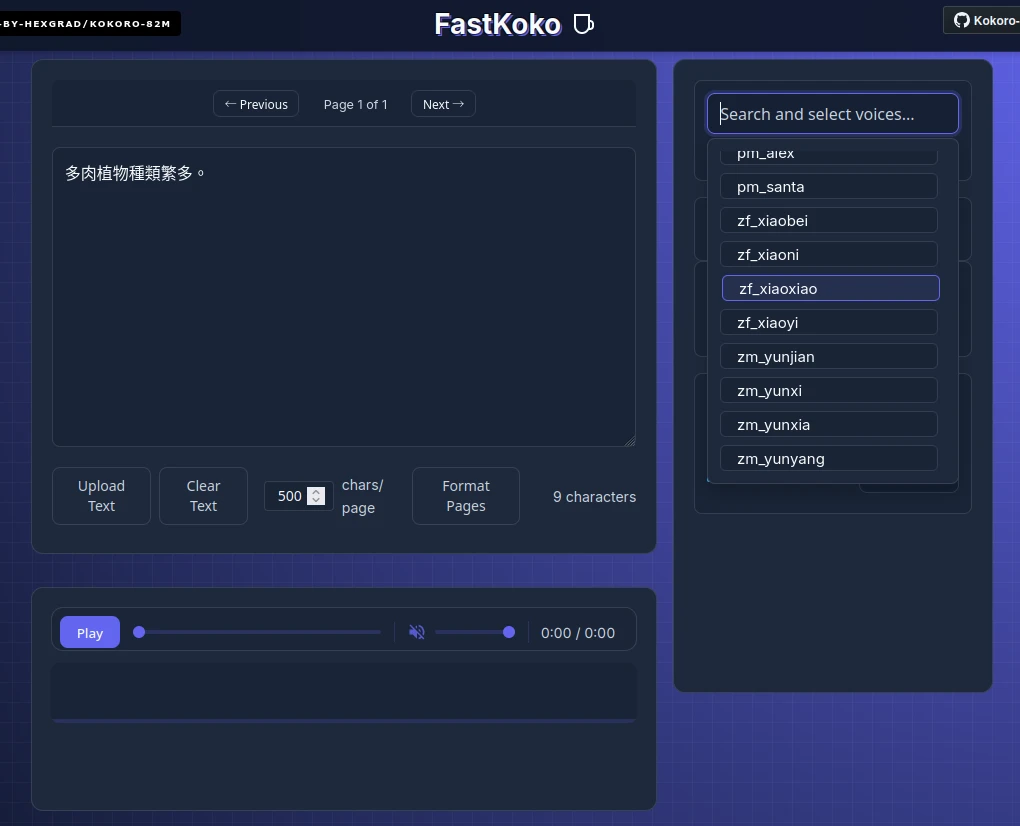
-
點選Open WebUI管理員設定 → 音訊,選取OpenAI,伺服器網址填入
http://Docker容器IP:8880/v1,API金鑰設定為not-needed,然後輸入Kokoro中文語音zf_xiaoxiao。模型選取tts-1。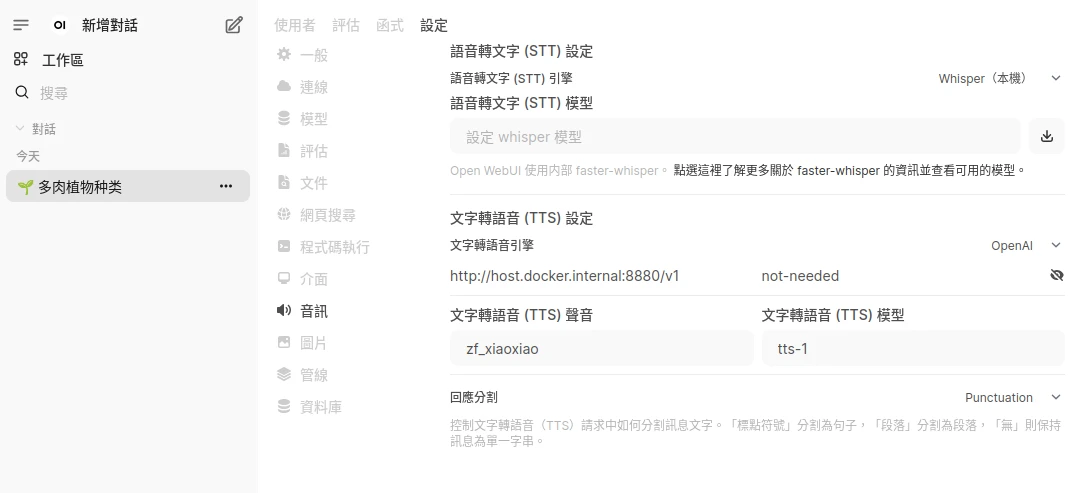
-
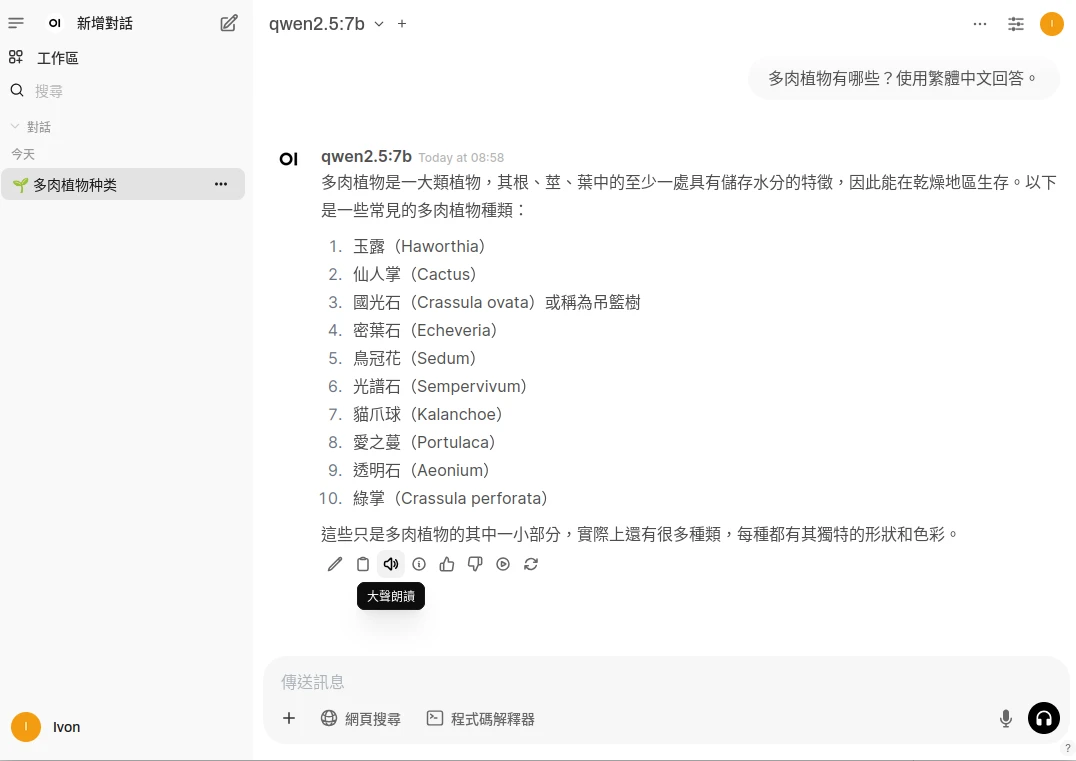
與語言模型對話,按旁邊的喇叭就會唸出句子來了。
-
對話時點選Open WebUI的設定 → 音訊,可以開啟生成文字後自動唸出對話的功能。