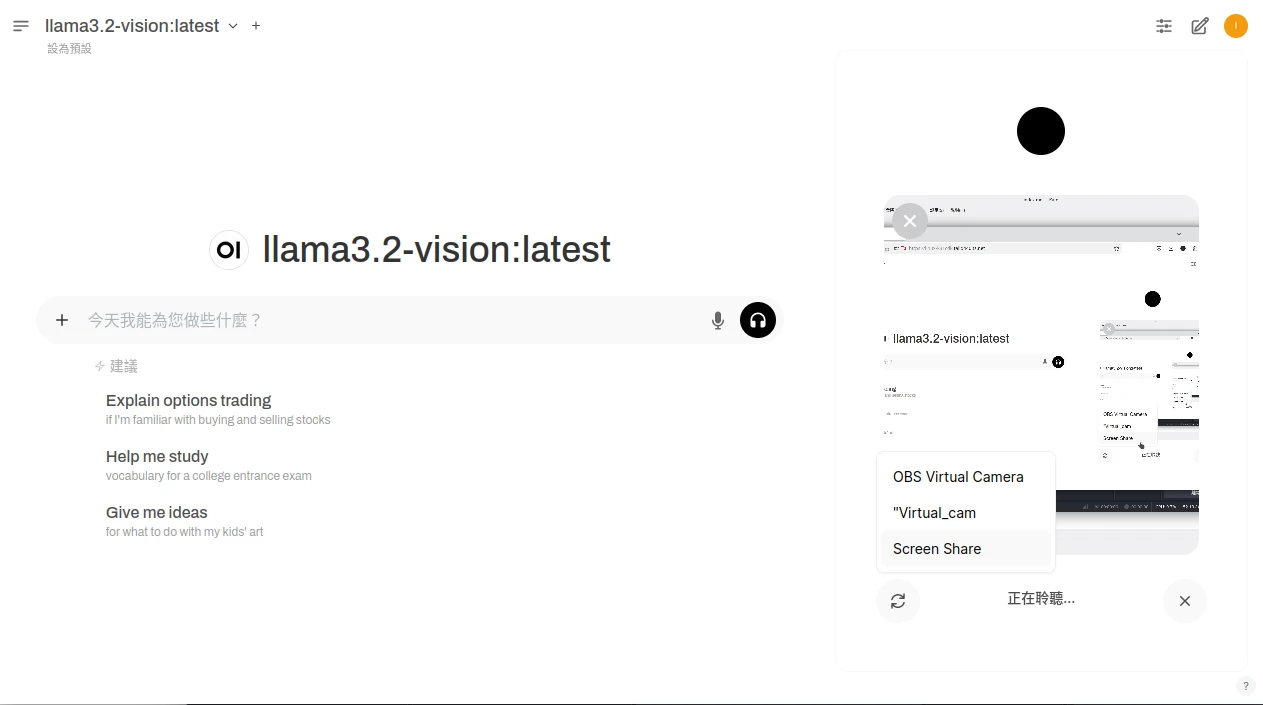
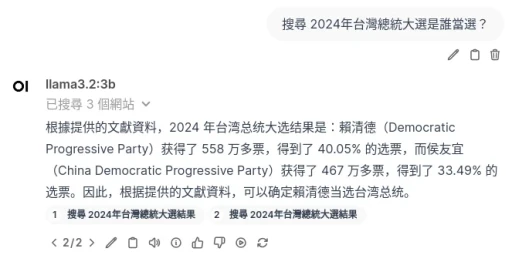
Video chatting with LLM in Open WebUI.
Open WebUI支援與本機語言模型進行視訊聊天,達成類似ChatGPT-4o的使用體驗。
具體原理是,利用Whisper模型將講的話變成語音指令,再搭配開源的多模態語言模型,實現視訊對話,讓AI分析攝像頭的畫面並給出回覆。
這有什麼用途呢?圖像辨識能夠讓語言模型參酌你的圖片內容進行對話,比如嘗試辨認圖片的建築物風格,以此寫故事。或是從圖片中辨識出文字。還可以嘗試讓語言模型依照圖片裡面的UI去生成程式碼。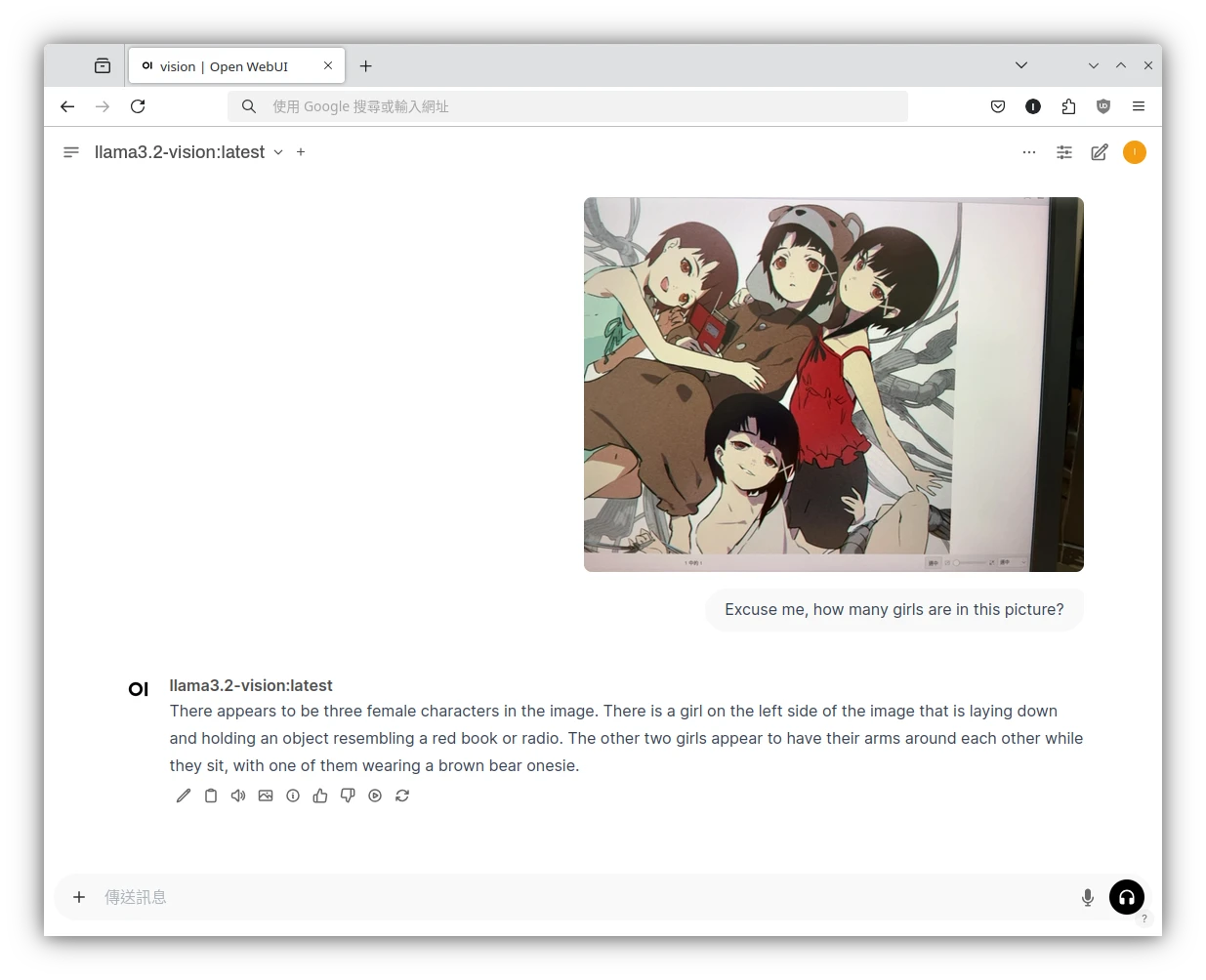
1. 需要的模型#
語音辨識不是由語言模型處理,所以跟任一個語言模型對話都可以。
圖像辨識,並不是所有語言模型都支援,如果要使用圖像辨識和視訊聊天,需要用多模態(multimodal)模型。Ollama Library有許多模型可用,例如LLaMA 3.2 Vision、LLaVA 7B、Phi 3.5 Vision這類的。
請在Open WebUI的管理員界面下載模型。
語言模型的圖像辨識回應速度視硬體性能而定,純CPU跑會非常慢。
2. 圖片辨識使用方法#
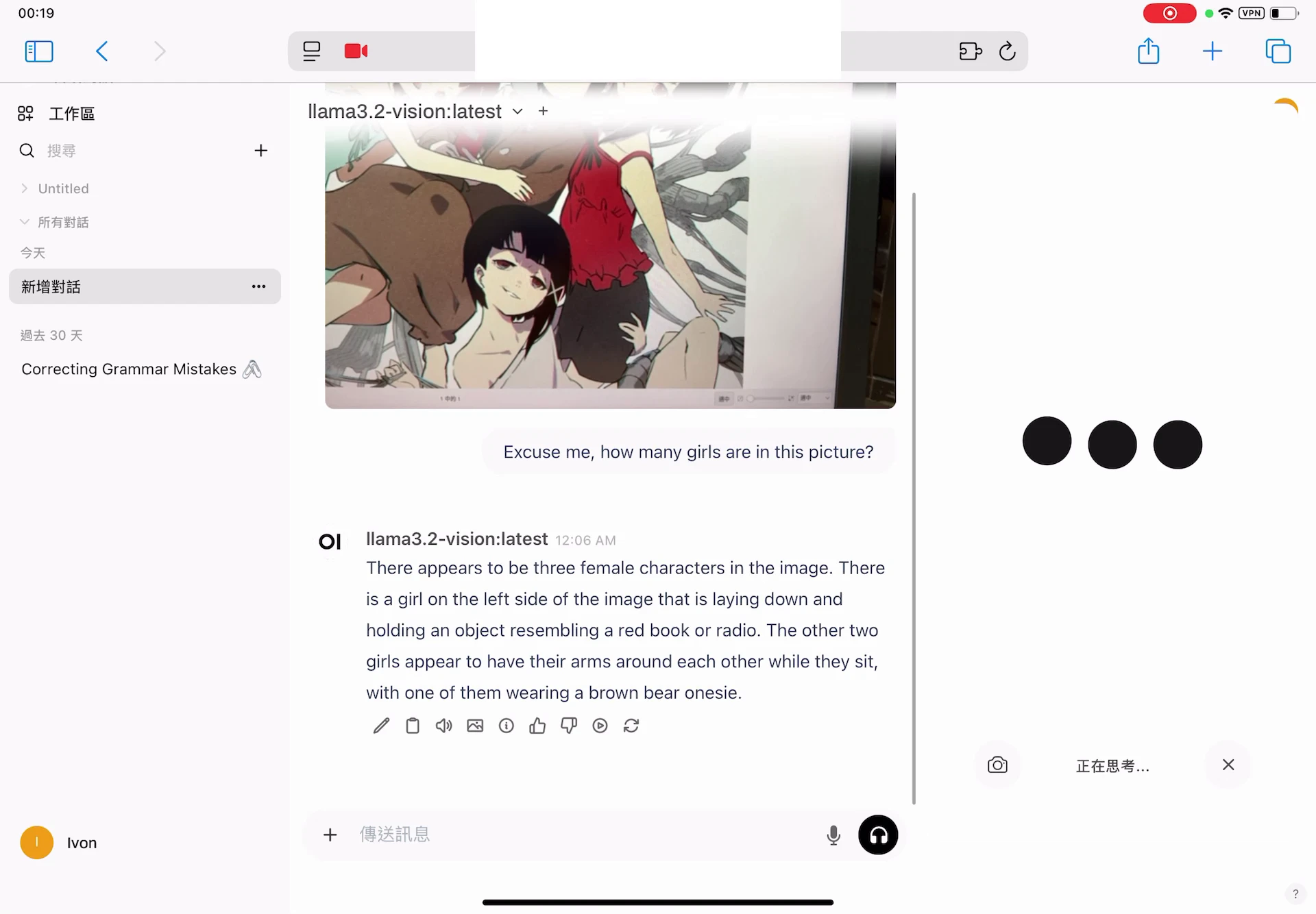
就…很簡單,在Open WebUI文字框點選上傳檔案,上傳照片,提示詞輸入「解釋圖片內容為何」。
這裡我的例子是,要語言模型根據我上傳的樹狀圖,生成繪製圖片的Python程式。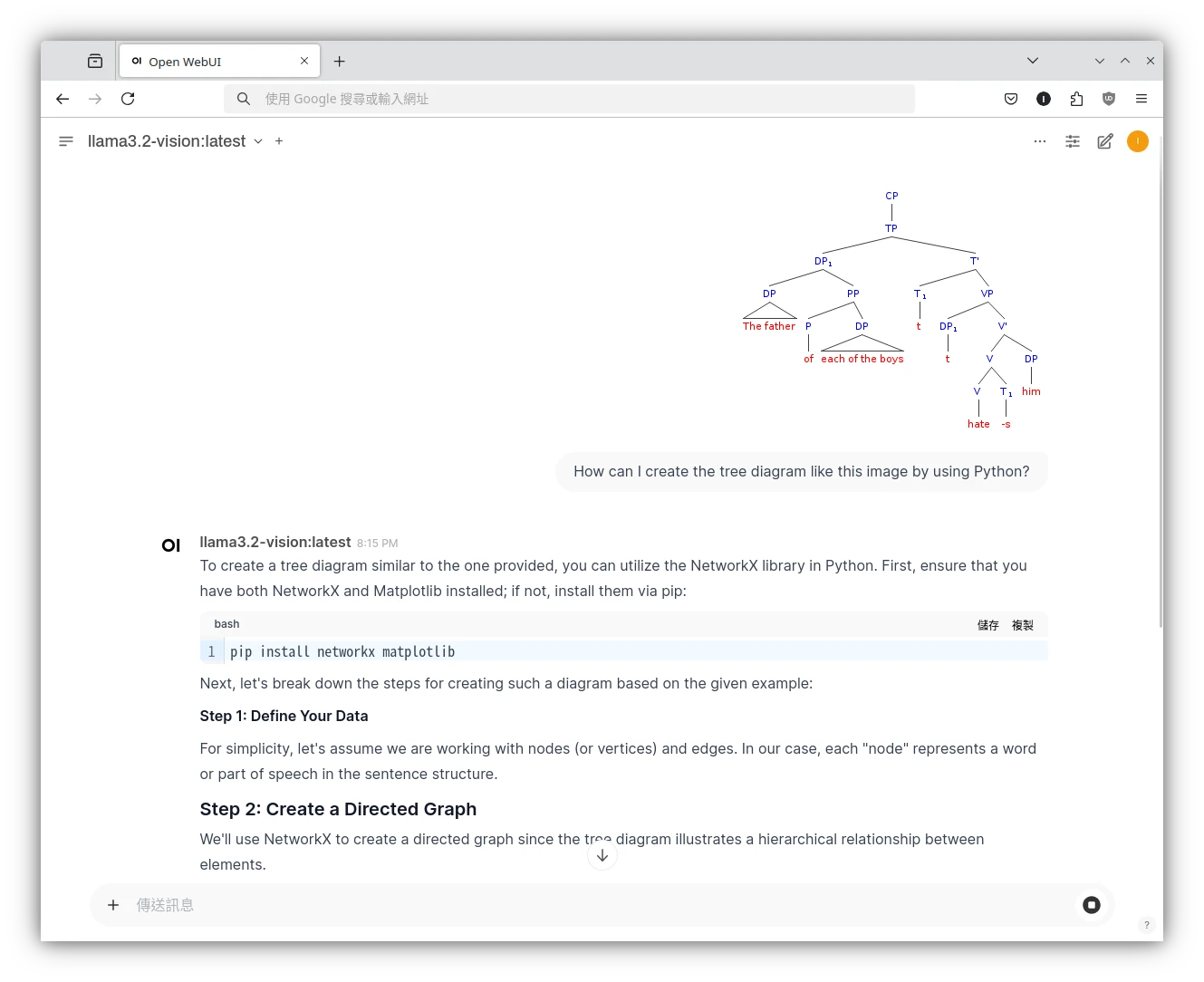
3. 語音視訊與圖片辨識#
由於這個功能會用到裝置的攝像頭和麥克風,因此需要給Open WebUI啟用HTTPS連線。如果沒有自己的域名,可以用Nginx Proxy Manager自簽SSL憑證解決。我個人是透過Tailscale Funnel或者Cloudflare Tunnel取得SSL憑證。
開啟Open WebUI管理員設定 → 音訊,啟用語音轉文字(STT)服務,下載Fast Whisper模型
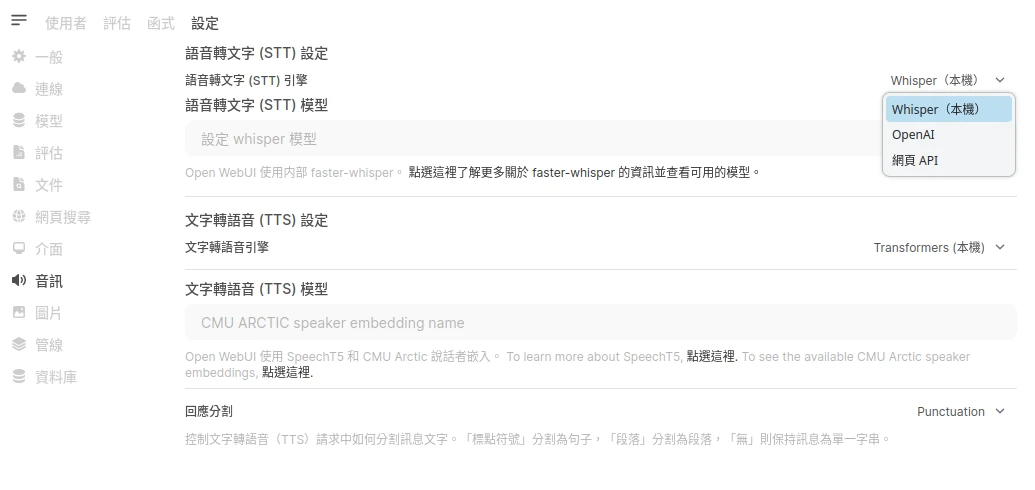
再來是選擇性設定,讓語言模型把圖片內容唸出來,看這裡了解如何設定文字轉語音服務。
在聊天介面選多模態模型,點選文字框旁邊的耳機圖示開始聊天,右邊會跳出語音界面。
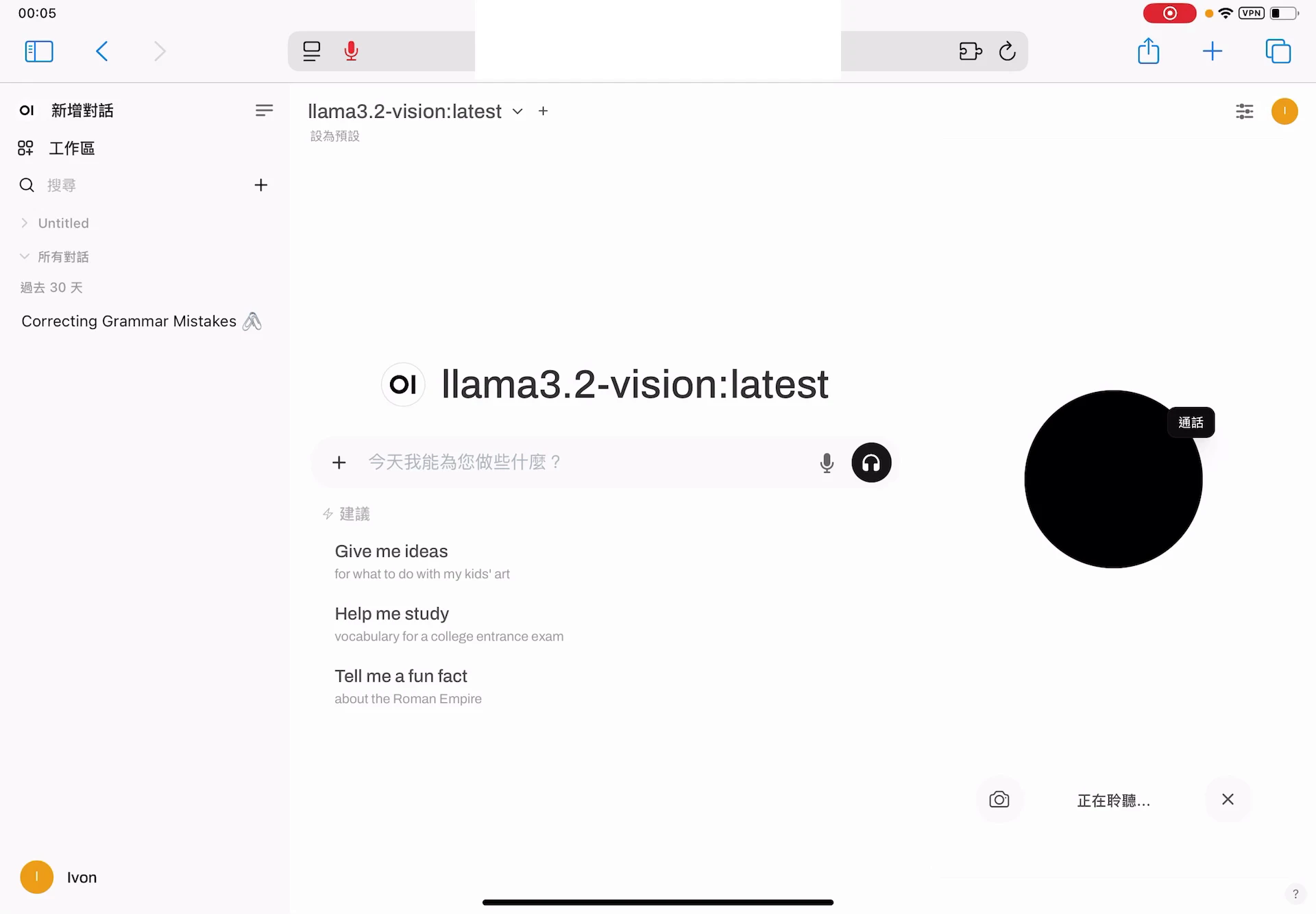
可以純語音聊天,你講的一段話會使用Whisper模型轉成提示詞,自動送出。
點選攝像頭按鈕開啟相機。目前Open WebUI的設計是講完一段話之後,才會截圖並傳送圖片給語言模型分析。
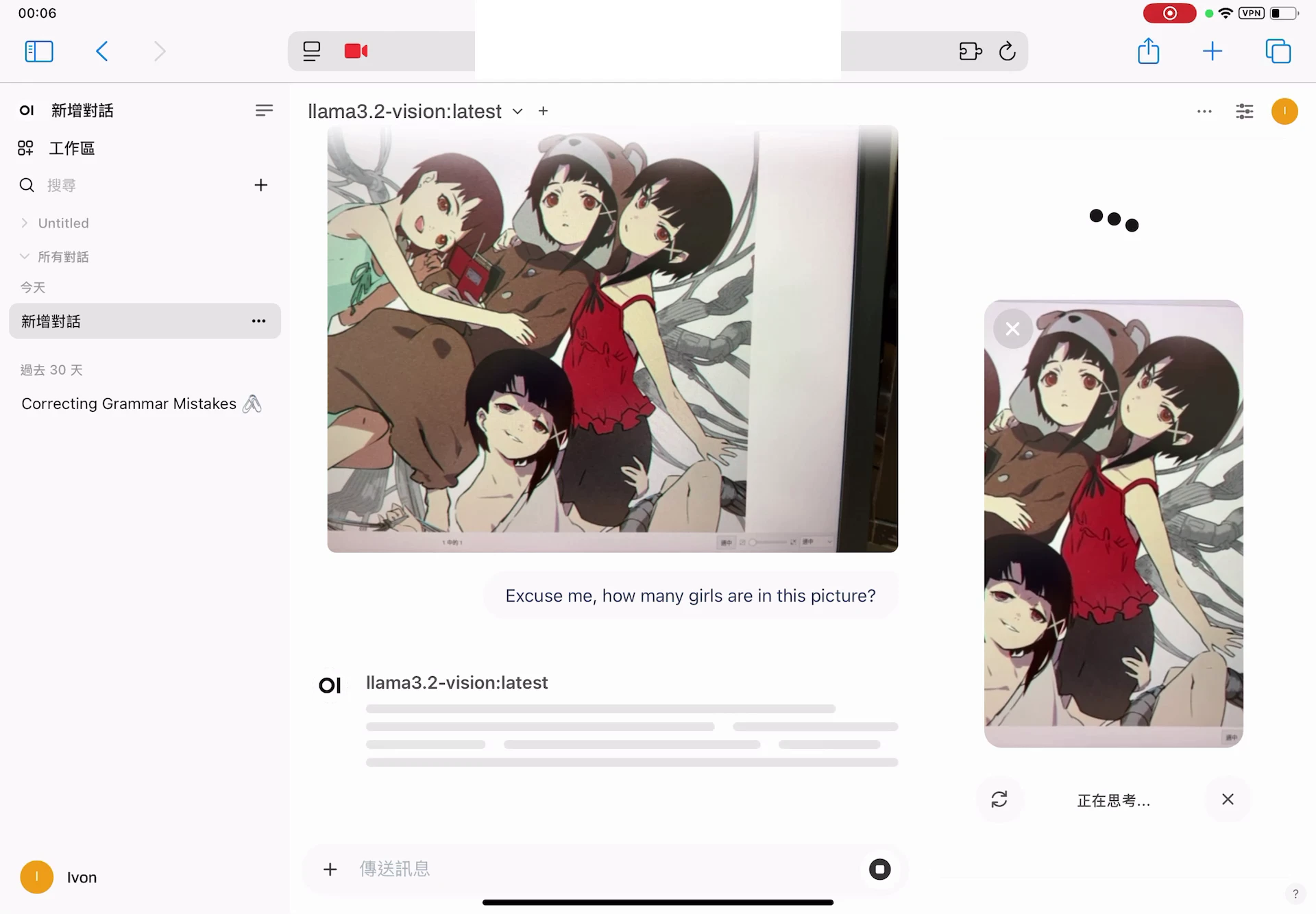
你得手動按回覆文字框下方的喇叭按鈕,才會生成語音。
4. 如何將螢幕分享給Open WebUI#
能不能讓語言模型直接辨認電腦螢幕上的內容,而不用手動截圖?可以,Open WebUI支援分享瀏覽器螢幕,電腦版的Chrome和Firefox應該都有這個功能。
不過電腦必須至少有一個攝像頭,Open WebUI才會讓你開啟相機。若你的電腦完全沒有攝像頭,這裡有一個取巧的方式能達成目的,那就是OBS Studio的虛擬攝像頭功能,將OBS Studio擷取到的畫面,傳到虛擬攝像頭。例如Linux系統的OBS Studio能夠透過V4L2製造虛擬攝像頭。
接著,只要在視訊的時候點選鏡頭圖示,切換為「螢幕分享」就行。