RVC WebUI (Retrieval-based Voice Conversion,檢索式語音轉換) 為一款開源的AI翻唱軟體,可以依照你的意思,讓AI為你唱首歌。
譬如,我讓川普翻唱Radiohead的High And Dry:
這款軟體最大的特色是複製人聲和訓練模型的成本很低,不用太高階的顯示卡就能跑!
1. RVC WebUI不是什麼#
RVC WebUI為Gradio寫成的網頁前端介面,背後使用VITS技術合成語音。
單就RVC WebUI的功能來說,它並非從無到有全自動生成歌曲的AI,它不是Suno AI,也不是文字轉語音服務,而是協助你製作AI翻唱的工具。RVC WebUI的功能是學習某人的聲音,並讓它模仿原本的聲調生成新的人聲音訊,就好像歌手翻唱別人歌曲的概念。
腦筋動的比較快的用戶應該能發現,其實「模仿他人聲音」不一定要用在歌曲上面。RVC WebUI產出的檔案是純人聲,因此用來當「變聲器」也是可行的。
像是你自行錄製一段說話的聲音,訓練為模型,再讓RVC WebUI轉換,變成另外一個人說話的聲音。RVC WebUI的作者確實有做了一個變聲器的小軟體go-realtime-gui.bat,能夠搭配OBS Studio直播使用,實現即時變聲,但只適用Windows。若要在Linux與macOS使用RVC做即時變聲器,那麼這個專案Realtime Voice Changer Client比較合適。
另外,RVC WebUI沒有文字轉語音的功能,你得準備一段錄音讓他複製。若要複製聲音唸出指定文字的,建議使用RVC-Boss/GPT-SoVITS-WebUI。
2. RVC WebUI的處理步驟#
使用之前,你需要準備預先訓練好的人聲模型,或者是一段人聲錄音,讓RVC WebUI學習。
RVC WebUI沒有生成音樂的功能,曲子要另外準備。
然後,你要準備另一段要模仿的對象的人聲音訊,RVC WebUI將將提供的人聲複製過去,生成新的人聲音檔。
如果你覺得純音訊的素材很難找,RVC WebUI作者已經幫你考慮過這個問題了。RVC WebUI內建UVR (Ultimate Vocal Remover)模型,能夠快速將人聲和伴奏音樂分離出來。這樣的話你只要準備一首歌曲的音檔,便能取得該曲子的純人聲與純音樂了。
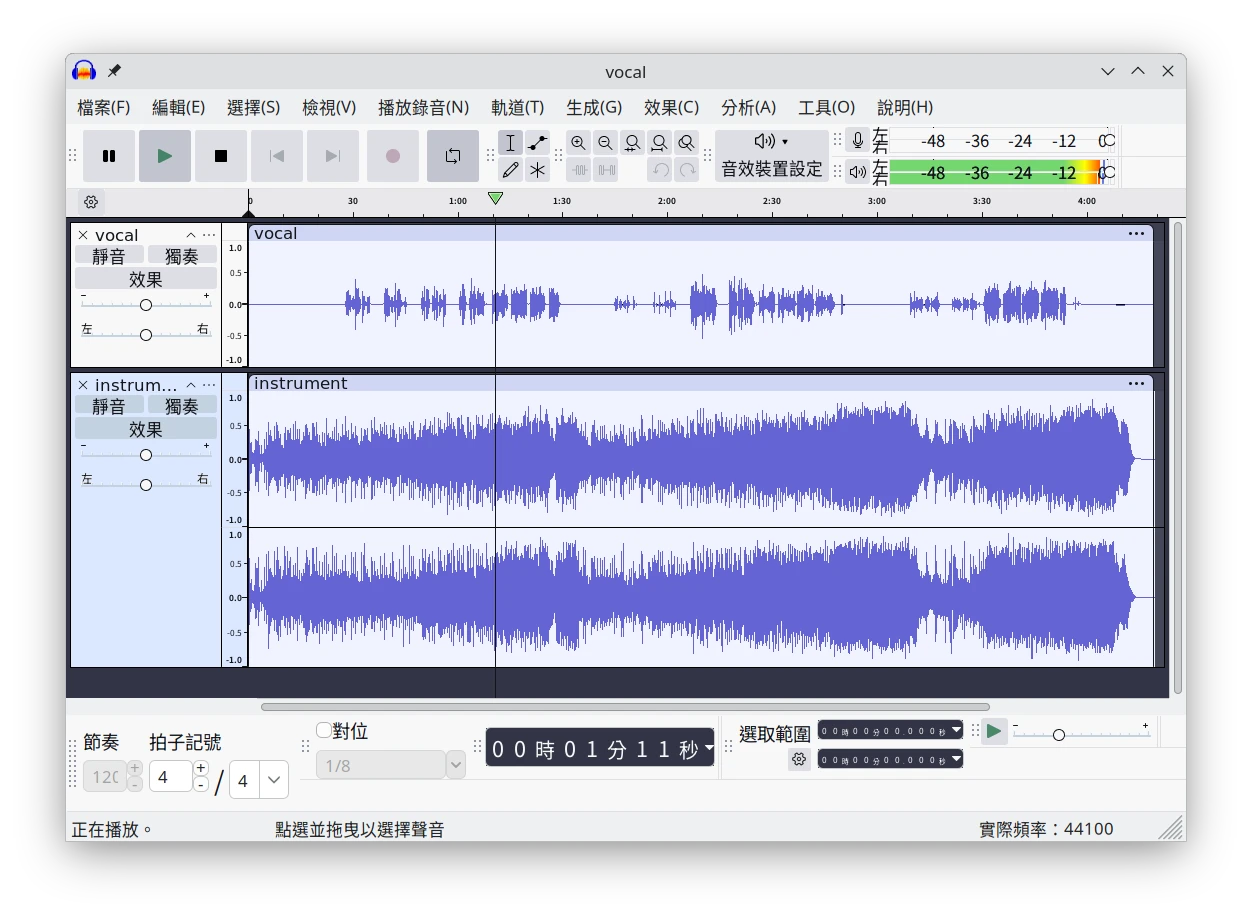
一切處理完成後,你要手動用Audacity將RVC WebUI產生的檔案合併。
3. RVC WebUI硬體需求#
RVC WebUI支援Linux、Windows、macOS系統。
本軟體可以透過Nvidia或AMD或Intel的GPU加速運算。
推理,也就是複製人聲,需要VRAM >=4GB
訓練自訂人聲的模型,需要VRAM >=6GB
4. 安裝RVC WebUI#
參照Github安裝指示。Linux需要自行建立Python環境,至於Docker版要自己包。
- 以Ubuntu為例,安裝ffmpeg和aria2,等會會用到
sudo apt install ffmpeg aria2conda create -n rvc-webui python=3.8
conda activate rvc-webui- 複製RVC WebU儲存庫
git clone https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI.git
cd Retrieval-based-Voice-Conversion-WebUI- 安裝Nvidia GPU所需的依賴套件
pip install torch torchvision torchaudio
# 防止fairseq conflict,需要降級pip版本 https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/issues/2452
pip install "pip<24"
pip install -r requirements.txt
# 解決Gradio版本太舊的問題 https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/issues/2355
pip install gradio==3.48.0- 執行指令稿,下載需要的模型
./tools/dlmodels.sh- 手動下載rmvpe模型,放到RVC專案的目錄
wget https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/rmvpe.pt- 啟動RVC WebUI,瀏覽器應該會自動開啟
http://localhost:7865
python infer-web.py5. 用UVR分離人聲與音樂#
這裡準備的是「被模仿的人聲」。
從歌曲抽取出人聲,或者準備一段清晰的錄音。譬如,我利用yt-dlp下載YouTube的歌曲,轉檔為mp3。
將該檔案放到RVC WebUI程式所在目錄的
/dataset
Retrieval-based-Voice-Conversion-WebUI
├── dataset
│ └── high-and-dry.mp3開啟RVC WebUI,進入伴奏人聲分離頁面。左邊輸入歌曲檔案路徑,模型使用
HP5_only_main_vocal,用於分離人聲與音樂。 點選轉換,處理後的檔案即會輸出到RVC WebUI程式所在目錄的
/opt之下。裡面vocal-開頭的檔案即分離出來的純人聲,instrumental-為純音樂。
Retrieval-based-Voice-Conversion-WebUI
├── opt
│ ├── instrumental-high-and-dry.mp3
│ └── vocal-high-and-dry.mp36. 下載RVC人聲模型#
訓練人聲模型需要準備許多音檔,並且要調參數,很耗費時間。
我這裡使用預先訓練好的模型檔,網路上有很多站點提供下載。
譬如,下載Tump RVC模型,得到model.pth和mode.index檔案。
將這兩個檔案放到RVC WebUI目錄下的assets/weights。檔案可以任意重新命名。
Retrieval-based-Voice-Conversion-WebUI
├── assets
│ └── weights
│ ├── trump_model.index
│ └── trump_model.pth7. 複製歌曲人聲#
進入RVC WebUI的模型推理頁面
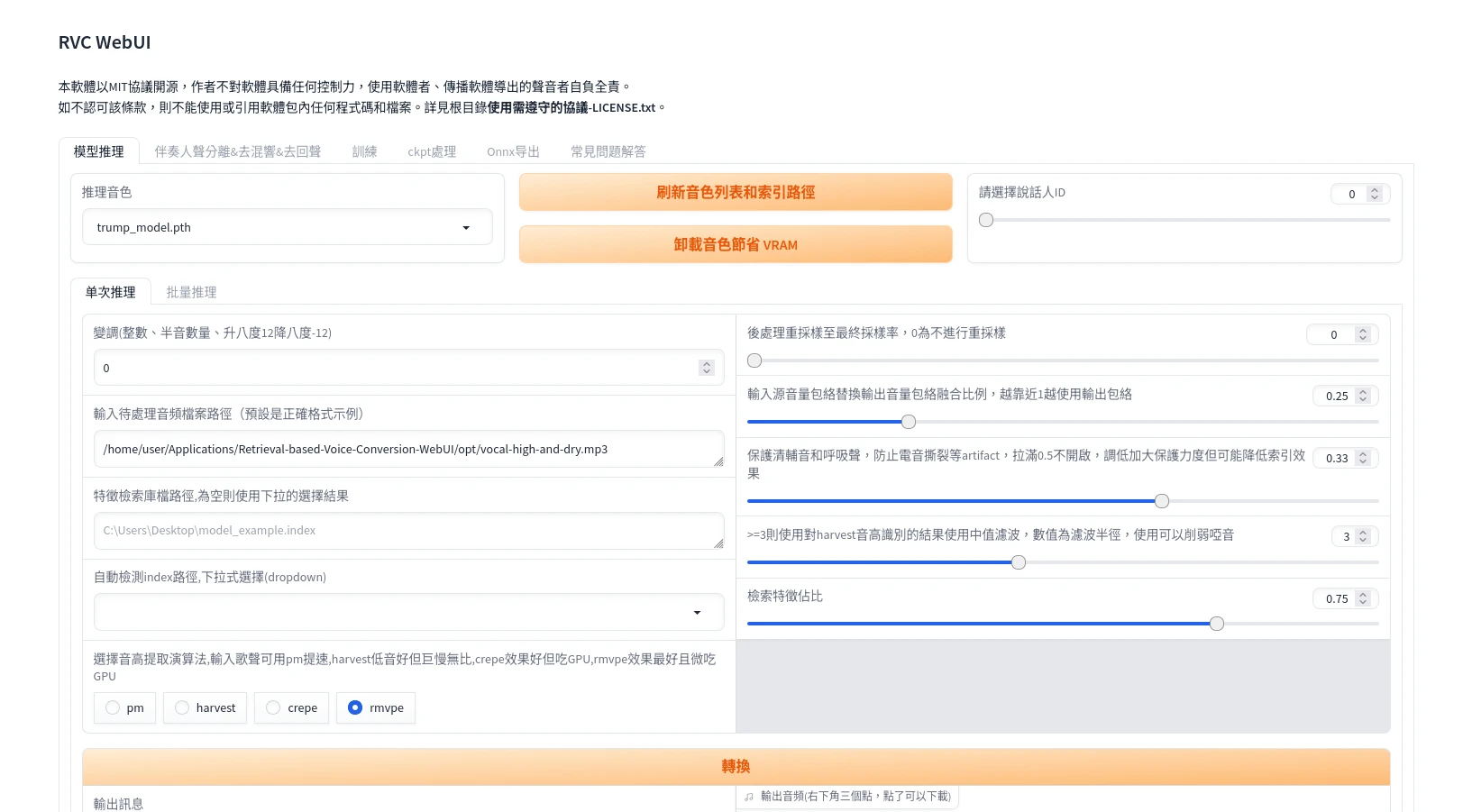
推理音色,選取剛剛下載的川普人聲模型(
model.pth)變調,如果原本兩個人的聲音差距不是很大,維持預設。
待處理音頻檔案路徑,輸入要模仿的人聲路徑。
最後輸入川普人聲模型index檔案路徑(
model.index)點選轉換,等待處理完成。
完成後,點畫面右下角播放器,下載處理好的檔案。
8. 將新人聲與音樂合起來#
這個可以用Audacity處理。
把人聲以及純音樂兩個檔案拖進去,成為二個音軌,試聽效果。再點選檔案 → 匯出聲音,完成合併。