Nathan Sarrazin開發的「Serge」是一款支援多個大型語言模型的開源網頁程式。

「Serge」名字源自網路meme,:義大利有一隻叫Serge Lama的羊駝,牠的名字是以法國歌手Serge le lam命名的。
Serge可讓使用者與LLaMA系列的AI聊天互動,就像在自己的電腦離線跑ChatGPT一樣,支援中文對話。
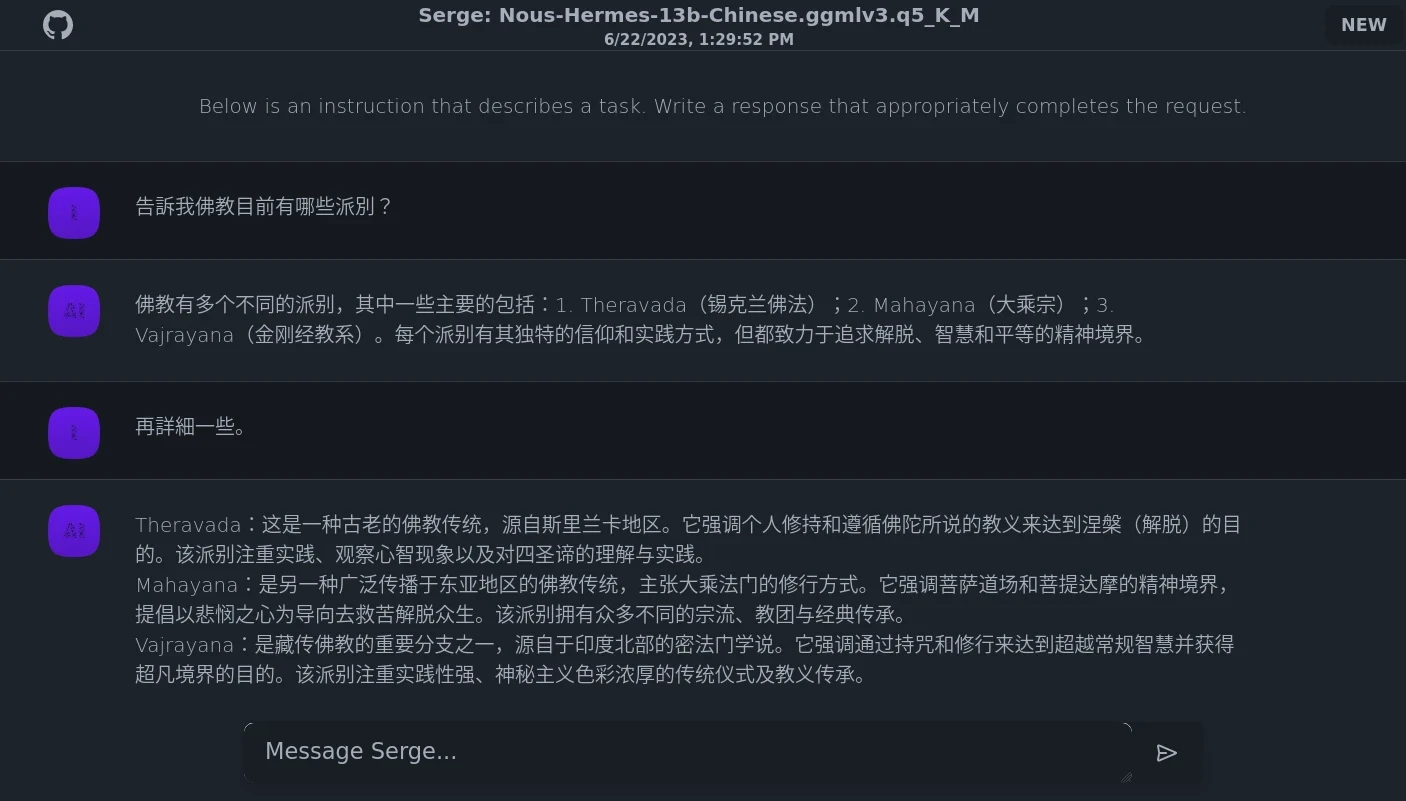
不知道什麼是LLaMA系列模型?請看LLaMA開源大型語言模型與相關軟體介紹
Serge的特色是架設很簡單,用Docker就能輕鬆跑起來,這樣您就有自己的離線AI啦,網頁版不論電腦還是手機都可以用。
且Serge硬體需求不高,背後是以CPU實作的llama.cpp下去設計的,您不需要強力GPU也可以體驗大型語言模型的威力。
1. 系統需求 #
- 支援Docker的作業系統,Linux/Windows/macOS
- 4核心以上的CPU
- 最少16GB以上RAM,這只是最低需求,越大的模型需要的RAM越多
- 最少20GB硬碟空間
Serge背後用的是llama.cpp技術,因此它只用CPU和RAM運算,預設不會用到GPU。
Nathan Sarrazin的Github儲存庫原始碼:serge-chat/serge - A web interface for chatting with Alpaca through llama.cpp. Fully dockerized, with an easy to use API.
2. 安裝Serge #
-
在電腦上安裝Docker
-
建立Docker-compose。
cd ~
mkdir serge-ai
cd serge-ai
vim docker-compose.yml- 填入以下內容:
services:
serge:
image: ghcr.io/serge-chat/serge:latest
container_name: serge
restart: unless-stopped
ports:
- 8008:8008
volumes:
- weights:/usr/src/app/weights # 將模型下載到Docker volume,您可以將路徑改指向目前目錄,例如 ./weights:/usr/src/app/weights。
- datadb:/data/db/
volumes:
weights:
datadb:- 啟動服務
docker compose up -d- 瀏覽器開啟
https://127.0.0.1:8008就可以看到Serge主畫面。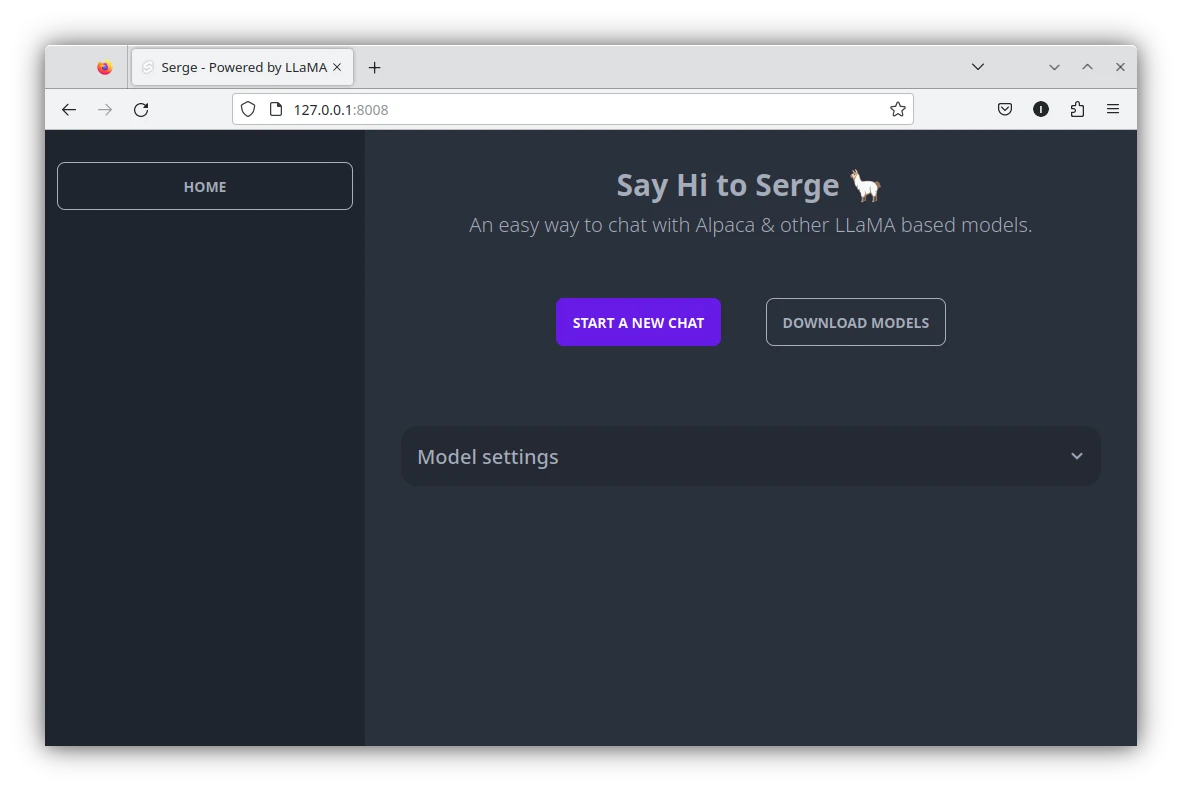
3. 下載大型語言模型 #
使用內建模型 #
點選Download model進入模型下載頁。對要下載的模型按Download。下載的語言模型檔案位於/var/lib/docker/volumes/weights/_data/。
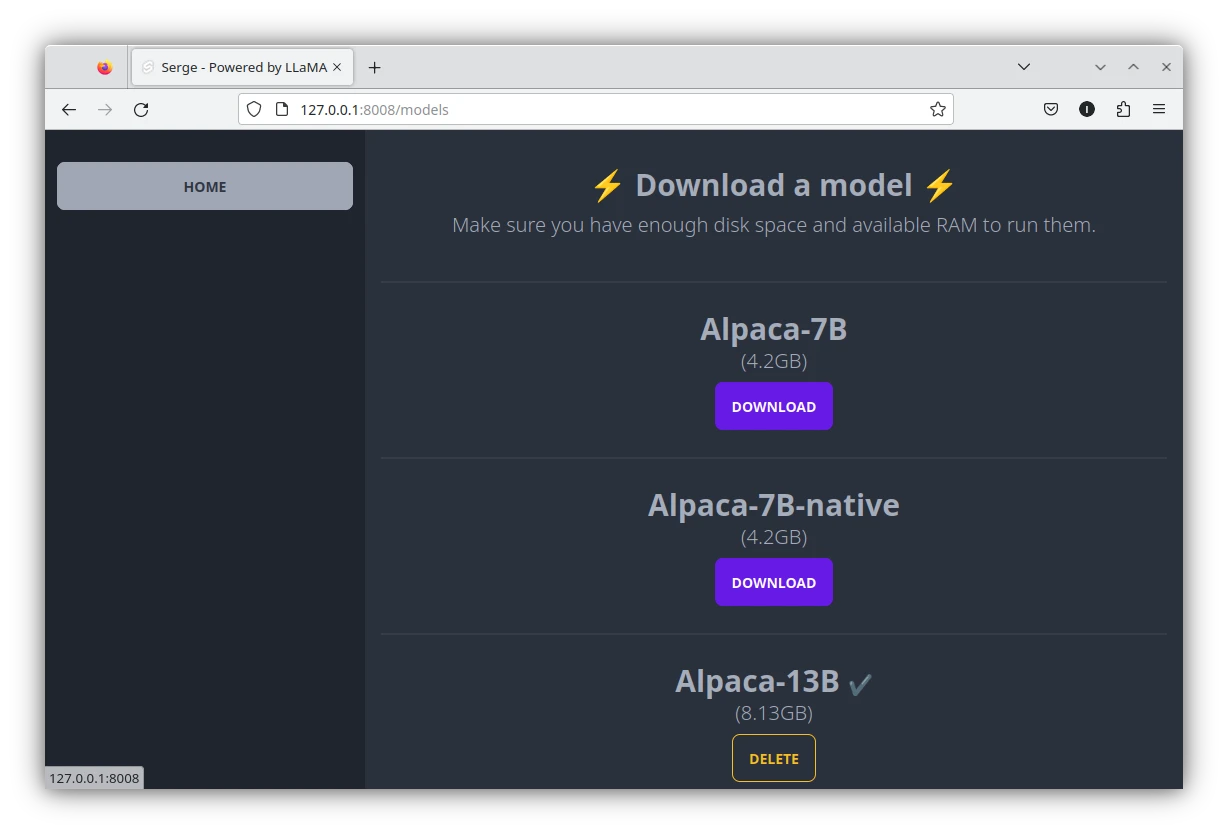
Serge目前提供的模型有LLaMA、Alpaca、Vicuna、OAsst、GPT4All、Airoboros、Chronos、Guanaco、Koala、Lazarus、Hermes、Samantha、Tulu、WizardLM、LLaMA 2等等…只要到Github提feature request作者就會加進去。
模型後面都有數字(7B/13B/30B),代表訓練資料集數量,數字越大的電腦需要越多RAM。例如跑最小的7B需要4GB RAM,13B約需要16GB RAM,30B需要32GB RAM,70B需要48GB RAM。
如果電腦RAM不足,可以用SWAP或分頁檔來提升RAM。
如果要我推薦哪個模型比較好的話,建議是從WizardLM-Uncensored-13B開始玩起,它回答品質與速度適中。
使用自訂模型 #
將想使用的模型(ggml格式)複製到Docker容器內部,例如支援中文對話的Chinese-LLaMA-Alpaca13B
docker ps
docker cp "~/模型檔.bin" 容器ID:/usr/src/app/weights4. 開始聊天 #
-
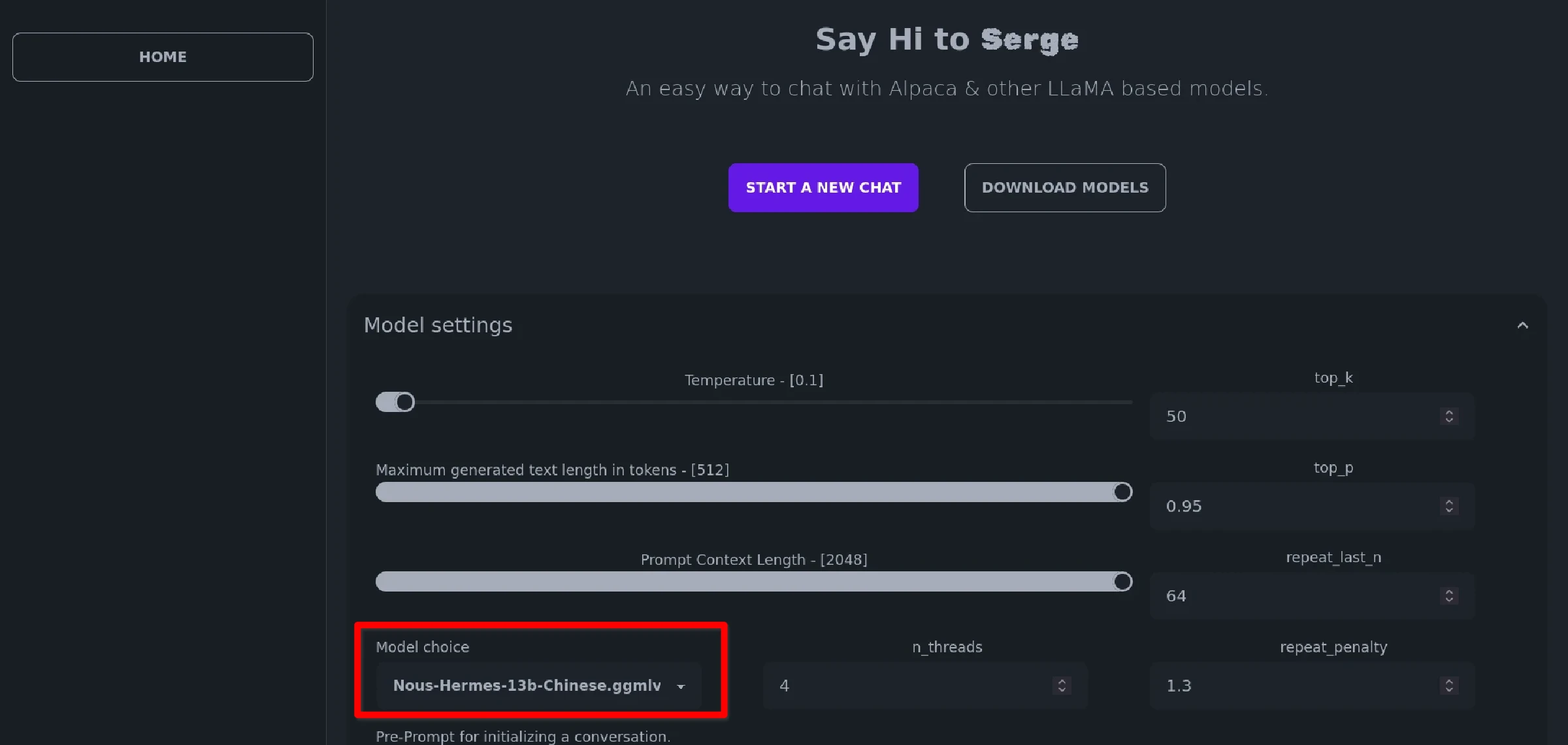
點開Model Settings,在Model choice處選取要使用的模型,這邊我選自己下載的Chinese-LLaMA-Alpaca13B。
-
Max size預設是512等於AI的記憶長度。如果你希望跟AI聊久一點的話,那就把這個值設定為2048,否則馬上就會到達context上限。Pre-prompt處的提示詞是要AI扮演的角色。GPU Layer是分擔給GPU運算的多寡,可提昇回應速度。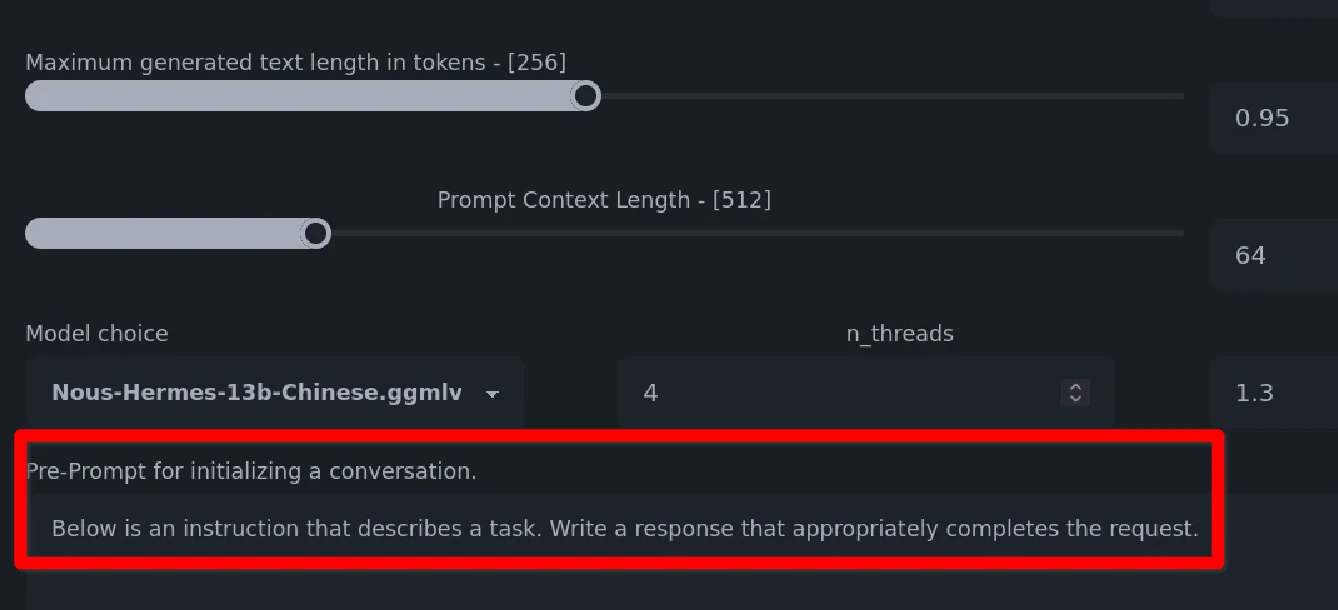
-
點選Start a new chat開始對話。AI的回應時間依電腦性能而定,Intel i5 7400所有線程全跑滿,大概需要算30秒才會開始生成回應。
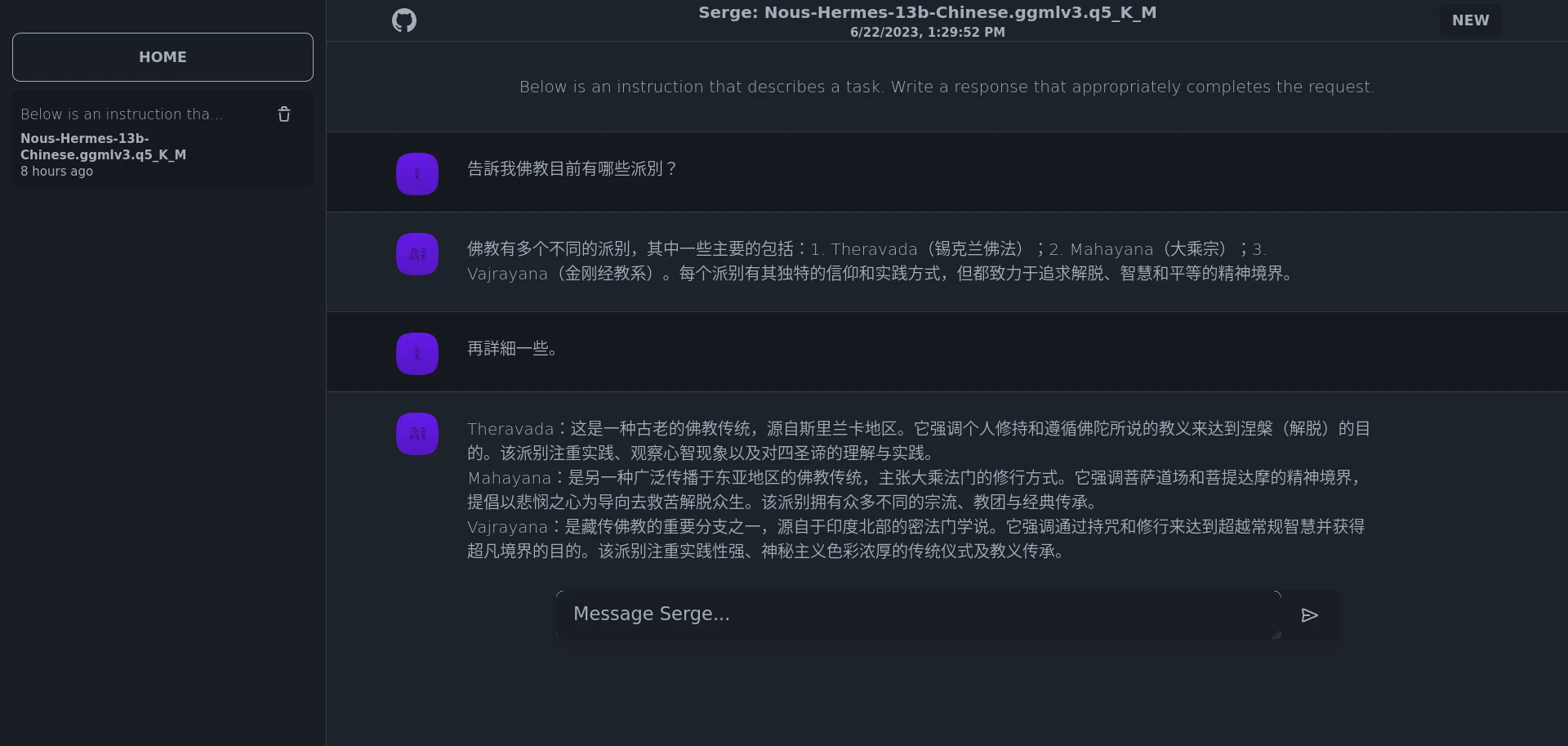
另外作者還準備一套API能夠與AI互動,文件網址請看http://localhost:8008/api/docs。
如果您想從外部網路存取Serge的界面,請使用內網穿透軟體。


