為什麼要AI繪圖呢?想像一下,在對話的時候讓AI把故事裡的場景畫出來~讓畫面更有沈浸感,好比在森林中走路,繪製前方看到的景色,或是遭遇到的敵人等等。
或者讓AI在教你一些知識的時候,隨時生成圖片作輔助教學。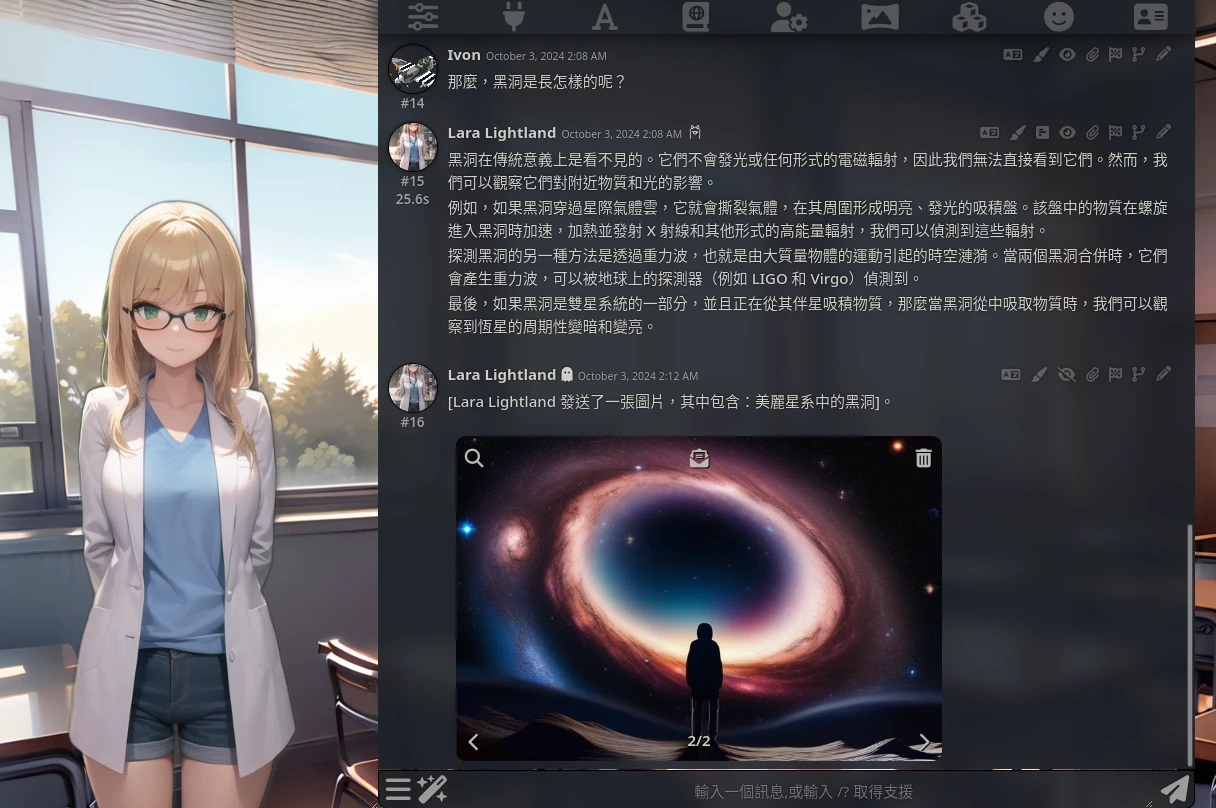
搭配多模態語言模型的話,還能跟AI討論圖片內容呢!
SillyTavern支援多款AI生圖服務:
- 線上:AI Horde、ChatGPT、NovelAI、HuggingFace
- 本機:ComfyUI、Stable Diffusion WebUI、Draw Things
SillyTavern可以將對話內容作為提示詞,傳給AI服務生圖。AI繪圖每家的品質都不一樣,具體會出現什麼,完全沒有人知道。就以Stable Diffusion為例,生成一般的風景倒還湊合,但如果要生成跟你對話的人物十分相關的圖片,你可能得準備LoRA加入生圖流程了!
1. 將SillyTavern連接到AI生圖服務#
以ComfyUI為例,你需要架起服務並啟動API伺服器:ComfyUI安裝教學。不用準備工作流,SillyTavern會使用ComfyUI內建的生圖。
點選SillyTavern的擴充套件面板,在圖片生成填入ComfyUI伺服器的網址。如果是架在同一台電腦,那麼就填寫
http://127.0.0.1:8188,再點選「連線」測試。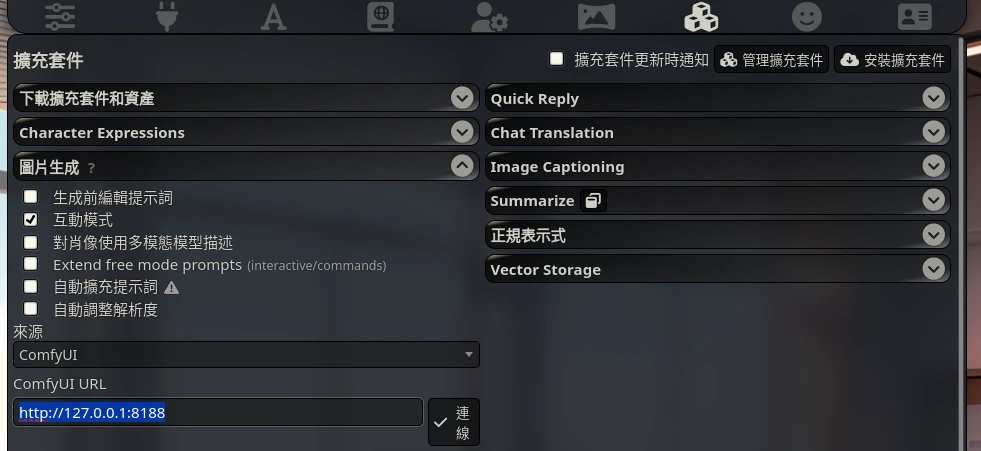
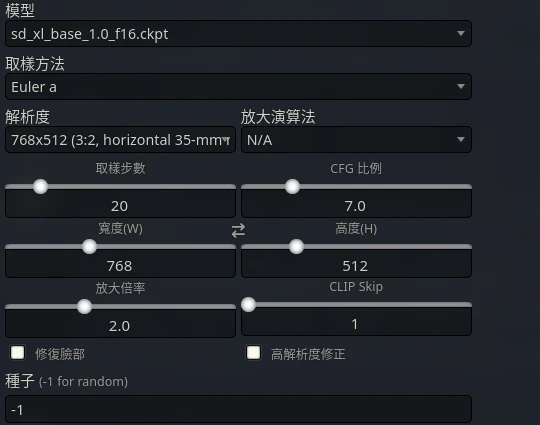
再於下面設定要使用的模型、解析度
2. SillyTavern請求AI生圖#
這可以在聊天欄使用/sd 提示詞指令達成
例如要求回傳一張你的圖片(指AI)
/sd you要求回傳一張你的圖片(指跟AI對話的使用者)
/sd me按照你的提示詞任意生圖,填入負向提示詞與正向提示詞:
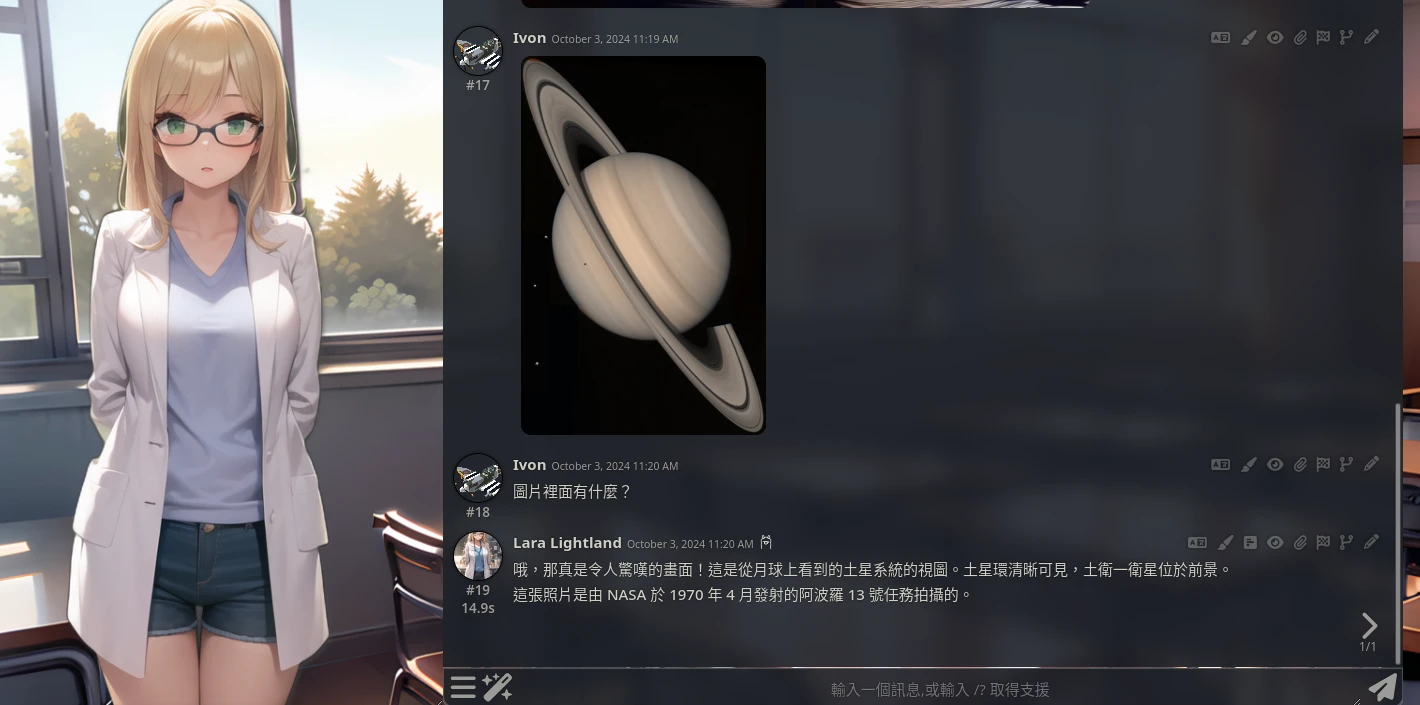
/sd negative="ugly, fat" young gilrl或者,在對話的時候使用Can you generate something...的提示詞,通常就會觸發AI生圖。
也可以點選聊天欄的訊息,將該段訊息作為提示詞生圖。
生圖之後點選聊天欄的箭頭可要求重新生圖。
3. SillyTavern讓AI分析圖片內容#
按聊天欄的按鈕呼叫語言模型出來給圖片下註解(caption)。我是不知道這功能有什麼用,因為AI也看不到這條訊息就是了。

要讓AI查看圖片內容的話,一般的語言模型是「看」不到圖片的,需要切換到多模態模型,例如Ollama支援LLaVA,就在選單切換目前的模型
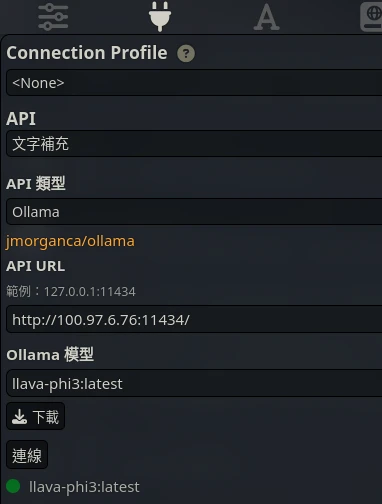
在聊天欄點選Generate Caption上傳圖片

於聊天欄詢問AI對圖片的看法?通常就會給出答案。