Linux目前沒有語音轉文字的輸入法(系統層級的文字轉語音則只有Speech Dispatcher),所以得從應用程式方面著手。於是我在Github找到了一款簡單易用的軟體:Speech Note
Speech Note (dsnote) 是mkiol開發的自由軟體,特色功能如下:
- 整合VOSK、DeepSpeech、Whisper、Coqui、Piper等模型,支援中文、英文、日文等多國語言輸入
- 使用語音輸入轉文字(Speech to text, STT),語音辨識,錄下逐字稿,匯出為txt或srt字幕檔
- 使用文字轉語音(Text to speech, TTS),AI複製人聲,合成語音並唸出文本,匯出為音訊檔
- 支援翻譯文本
- 所有運算都是在本機進行的,不會回傳給第三方
我覺得跟TTS Generation Web UI這類軟體比起來,Speech Note使用上算是比較簡單了。
下文討論Speech Note的用法。
1. 安裝Speech Note主程式#
參考Github說明
推薦使用Flatpak安裝,適用Arch Linux、Ubuntu、Fedora、openSUSE
flatpak install flathub net.mkiol.SpeechNote接著看你的需求是否啟用GPU加速。沒有的話就是用CPU算,耗時較長。
2. 啟用GPU加速#
Speech Note預設是用CPU處理的,GPU非必須,但是可以加速語音模型的運算速度達二倍以上。
建議GPU的VRAM至少要有4GB。
請先在Linux安裝CUDA(Nvidia)或ROCm(AMD)。Ubuntu參考這篇。
然後安裝對應的Flatpak Add-On:
# Nvidia
flatpak install net.mkiol.SpeechNote.Addon.nvidia
# AMD
flatpak install net.mkiol.SpeechNote.Addon.amd- 開啟Speech Note程式,點選Settings → Speech to Text,勾選Enable GPU Acceleration
3. 使用語音轉文字功能#
點選Languages,到zh(中文)的頁面下載模型。建議使用較新的Whisper模型。VOSK和DeepSpeech效果很不好。我自認講話不會含滷蛋,中文語音辨識得使用Speech to Text 的「Whisper Large」或更大的模型才有好的辨識效果。
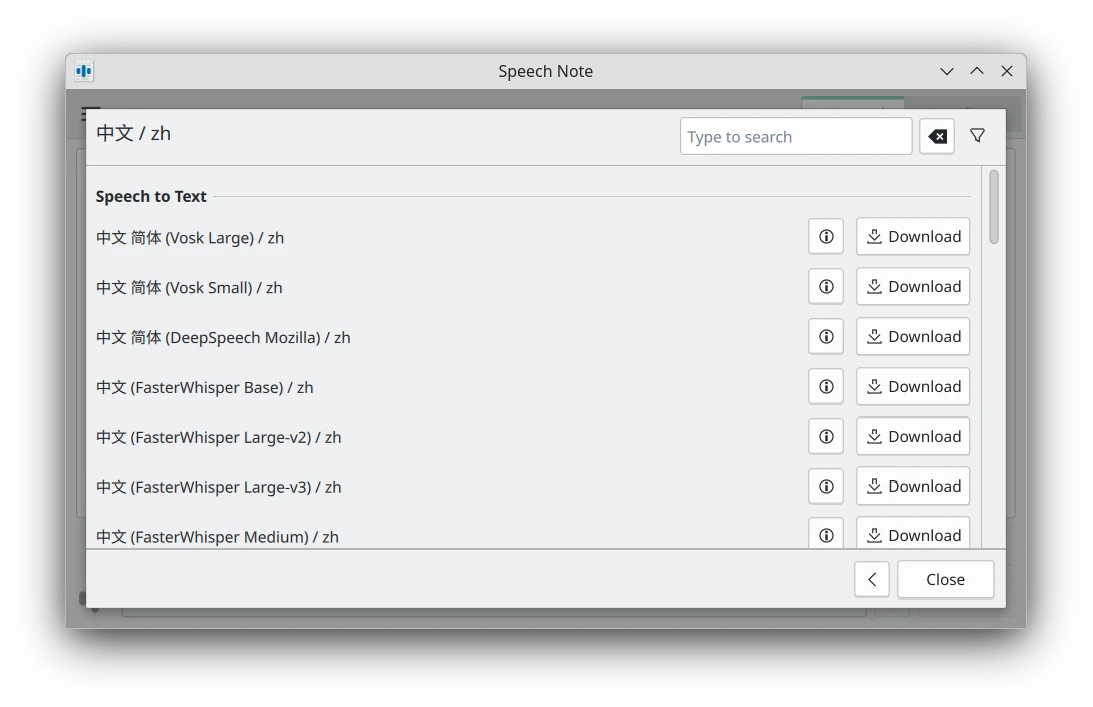
然後回到主頁面,選取要使用模型,點選Listen圖示開始講話。順帶一提,Speech Note也可以錄電腦其他程式發出的聲音,從而生成逐字稿。
等待處理完成,文字就會印出來。預設模式是Plain Text,所有講的話都會連在一起。
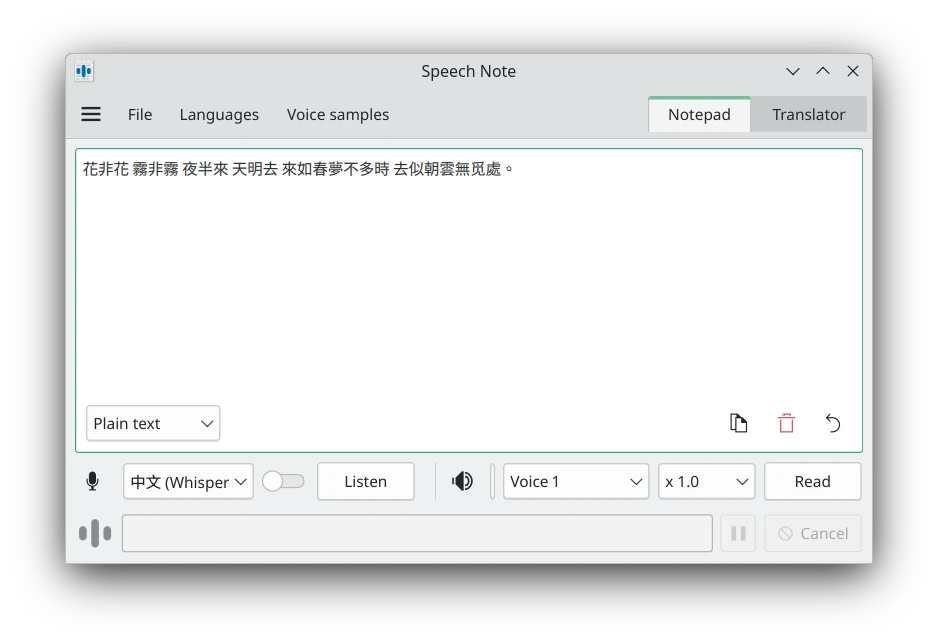
如果勾選Subtitle,則每句話會加上時間戳。
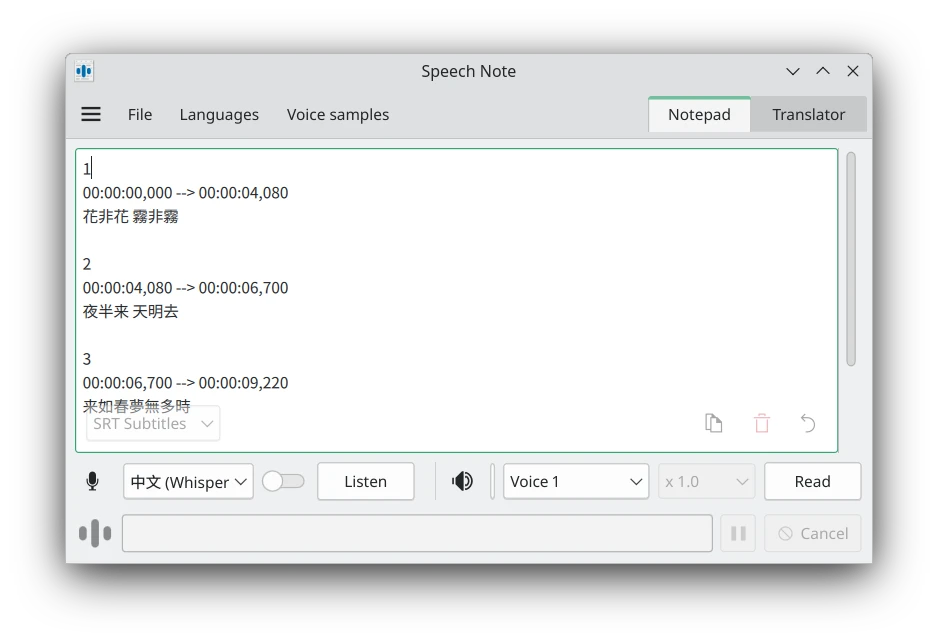
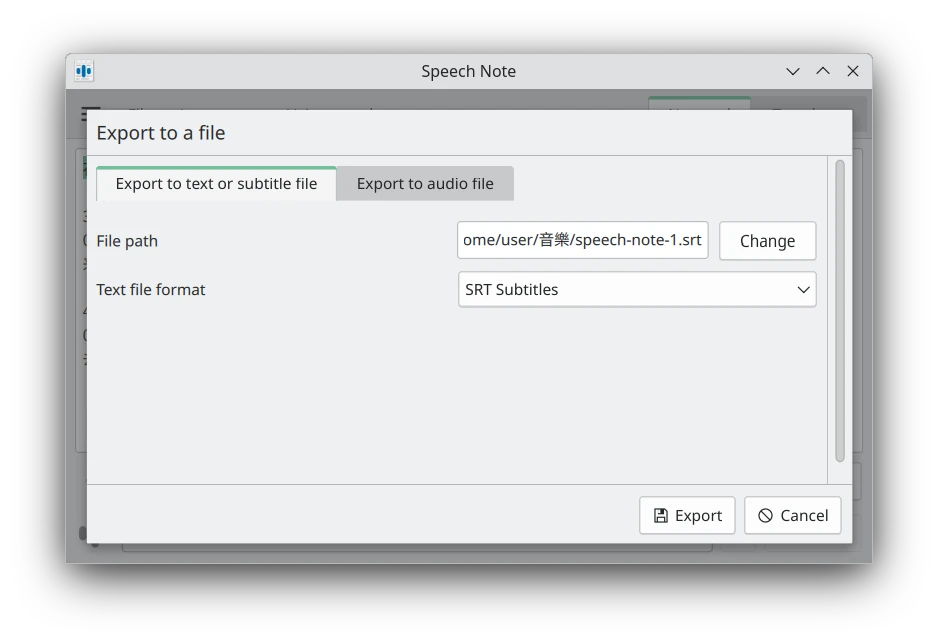
點選File → Export to text file,將辨識到的文本另存新檔
4. 使用文字轉語音功能#
點選Languages,到zh的頁面下載模型,如果你要快速生成就選Piper Huayan
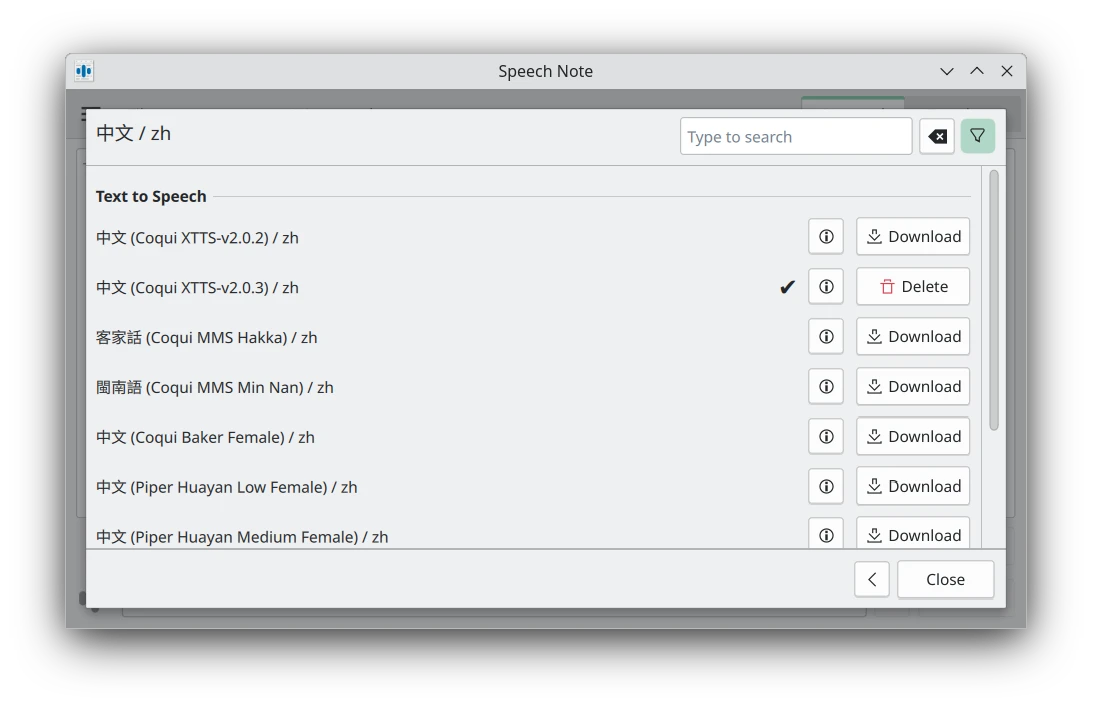
若你想要複製他人聲音來生成音訊,請選Coqui XTTS的中文模型,然後點選Voice Samples新增語音樣本,只需要10秒就夠了。
請錄製一段自己的聲音,或者從網路上找人聲樣本的音訊檔。順帶一提,需要從音樂抽取人聲的可以用UVR。
有了樣本後,就可以在主界面選取聲音,並讓AI嘗試唸出文本框的字串了。整段文字可按File → Export,匯出成mp3音訊檔。