ComfyUI是一款開源的AI繪圖軟體,用於精準控制AI繪圖的生圖流程。
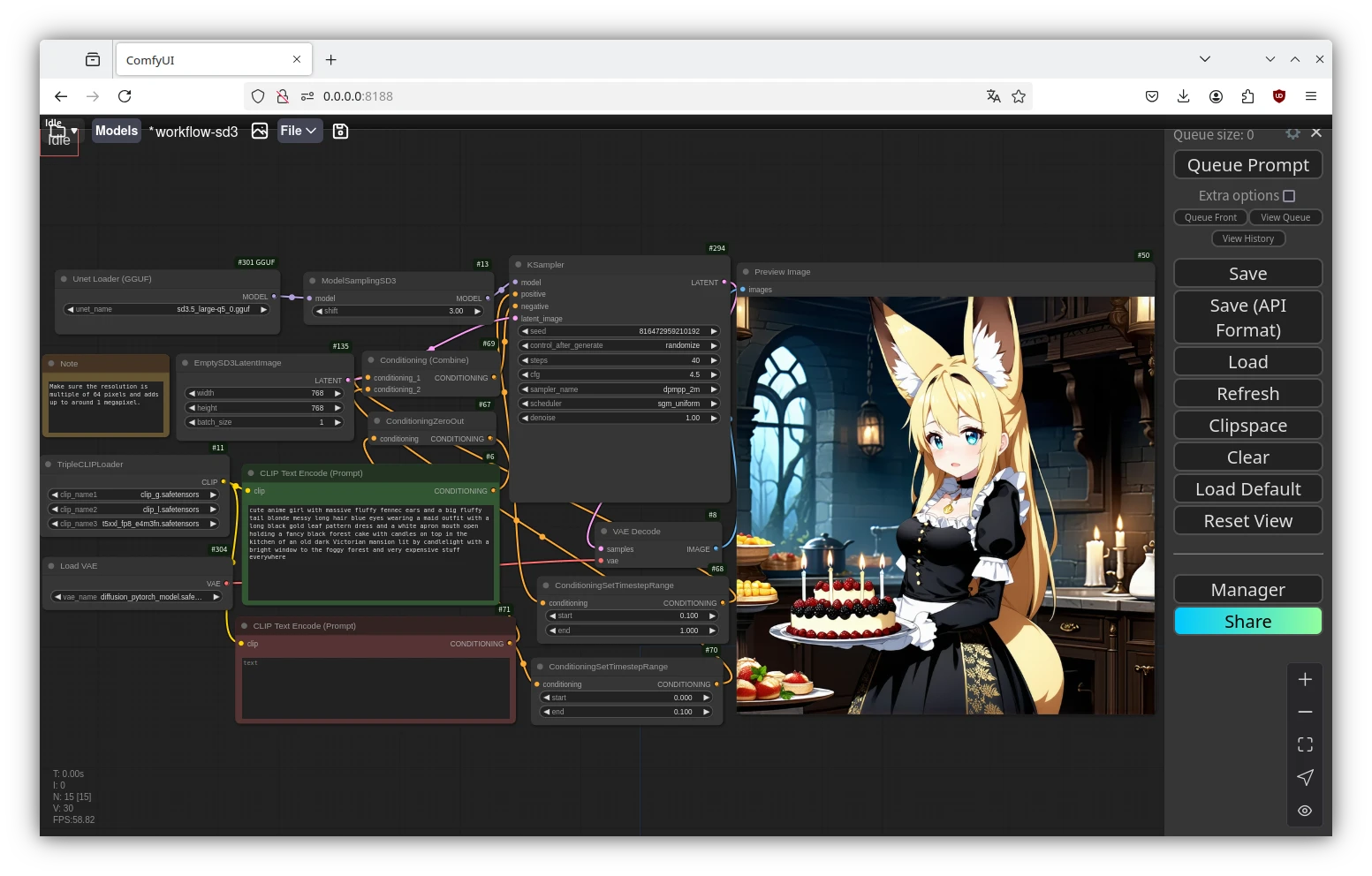
ComfyUI背後使用Stable Diffusion與FLUX系列模型來生成圖片,支援文生圖、圖生圖、局部重繪、放大圖片、訓練模型、生成影片,以及使用LoRA和ControlNet。
本系列文章,Ivon首先會介紹ComfyUI的優點,接著講安裝方法,再示範網頁界面的基礎操作方式。
1. ComfyUI讓你更了解生圖的原理 #
ComfyUI有何優點?第一個我想就是讓你更清楚AI生圖的原理了吧。
ComfyUI的功能類似Automatic1111的Stable Diffusion WebUI,使用同樣的Stable Diffusion模型來生圖。然而,ComfyUI相對SD WebUI來說沒那麼好上手,儘管二者背後使用的是相同的Stable Diffusion模型,但是需要對背後生圖原理有更深入的理解才能用好ComfyUI。
ComfyUI開發者說他是為了解Stable Diffusion的運作原理才開發這個軟體的,主打一個「邏輯」。
如下圖,這是Stable Diffusion技術背後的生圖過程…好吧沒有影片解釋,非本科生應該很難看懂。
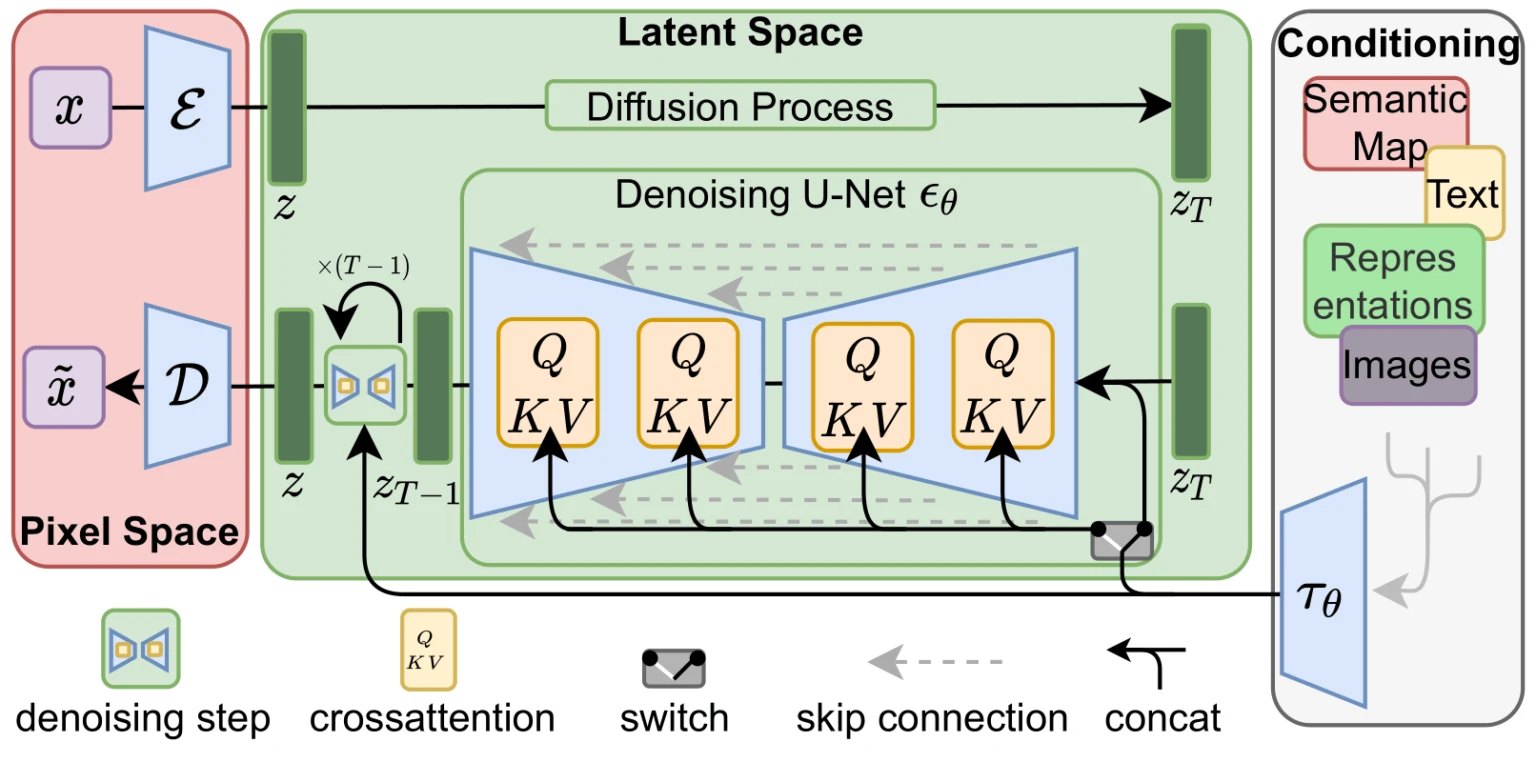
ComfyUI概念很像上圖,讓你能更清楚掌握AI生圖的過程。當然ComfyUI沒有複雜到需要寫程式,大部分功能都圖形化了。
生圖中間會經過哪些步驟,ComfyUI都會以圖形化的動態方式呈現,讓你一目了然。
2. 靈活又多變的ComfyUI工作流 #
ComfyUI的第二個優點:將工作流程(workflow)標準化。ComfyUI以node-based為設計理念,每個生圖步驟都是一個節點(node),使用者能夠觀察和精確控制AI生圖的過程。
如果你想將Stable Diffusion的AI生圖程序標準化,那就可以採用ComfyUI。
我認為ComfyUI是訓練邏輯的好東西。用過Blender的話應該會對「節點」(node)的操作有點概念,只要你清楚知道自己在做什麼,你就可以輕鬆的用拉線的方式,規劃AI生圖流程。
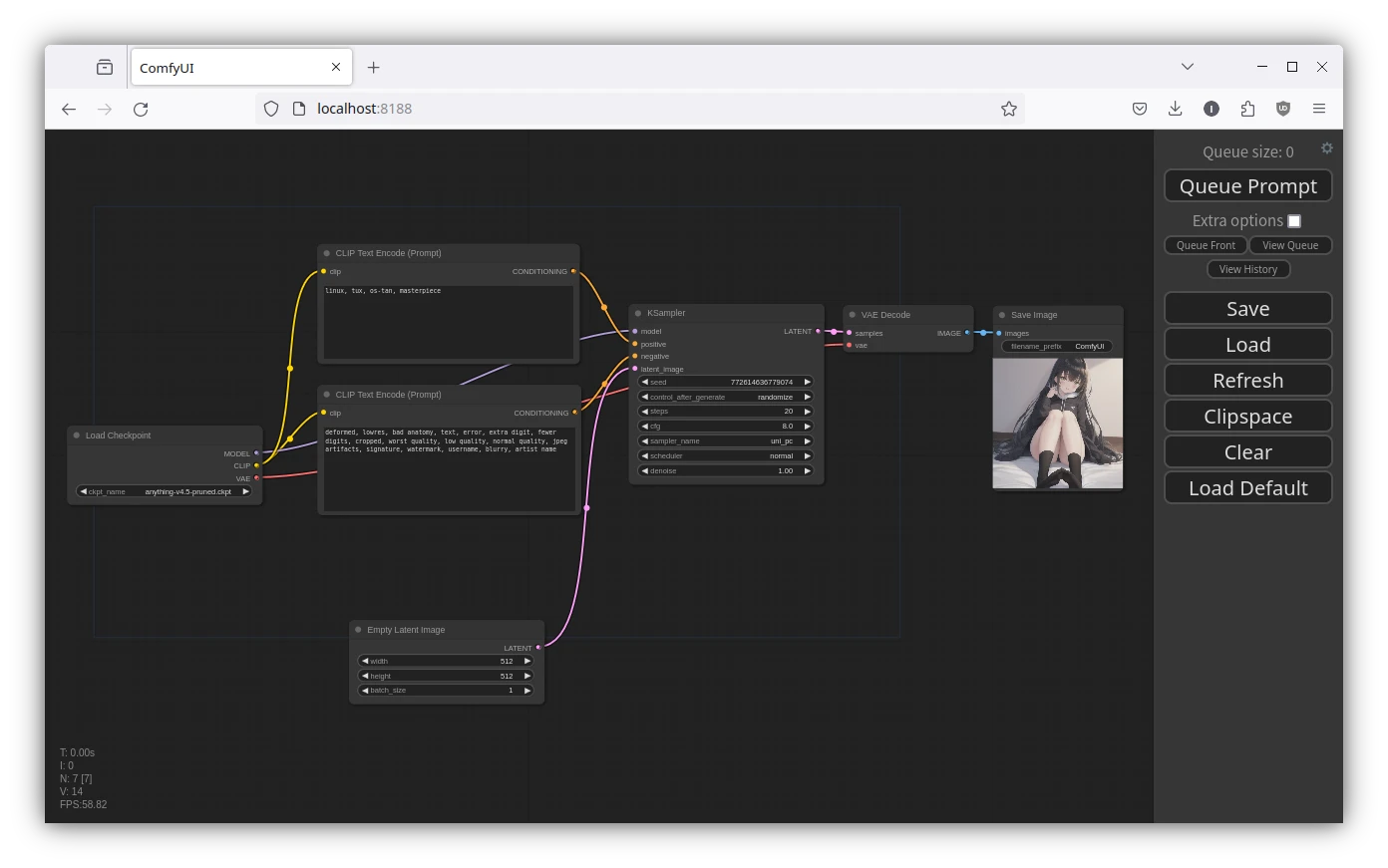
比方說你想要:文生圖,再進行局部重繪,再用Real-ESRGAN放大。在SD WebUI你得手動點二次切換界面,而ComfyUI只要線一拉好,整個流程在按開始後就會一次自動完成。
你甚至可以把ComfyUI的工作流程儲存起來,供他人使用。這樣別人只要開啟你的流程圖,就可以順利跑完同樣的生圖流程。
此外,ComfyUI工作流的設計,讓第三方開發者能夠撰寫擴充套件(自訂節點),不用等ComfyUI原作者更新,也能即時支援最新的AI生成技術。
參考資料 #
本系列教學文章參考以下兩個網站的資料撰寫。

