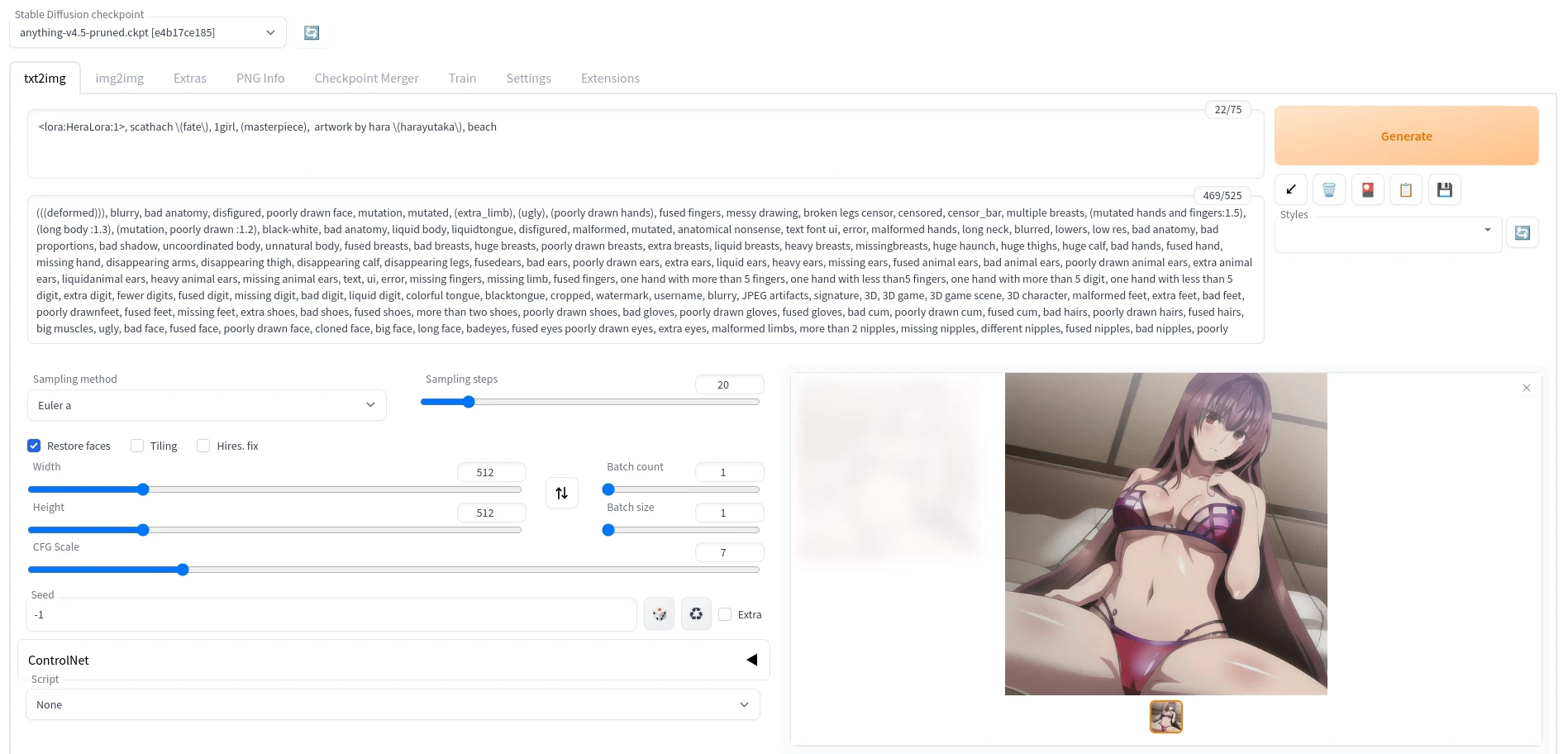
LoRA (Low-rank adaptation)是用来微调大型模型的技术,其生成的模型训练时间短,文件更小。
DreamBooth内含LoRA,可作为 SD WebUI的扩充功能安装。
本机训练还可以用 LoRA_Easy_Training_Scripts,支持Linux和Windows系统。
有用Google Colab的采用 Linaqruf/kohya-trainer会比较好上手。 Reddit有一图流教学。
1. 安装环境 #
“LoRA Easy Training Scripts"这个Python程序Linux和Windows都可以用,下面以Ubuntu为例。
- 安装 Anaconda,创建虚拟环境
conda create --name loratraining python=3.10.6
conda activate loratraining
- 拷贝保存库
git clone https://github.com/derrian-distro/LoRA_Easy_Training_Scripts.git
cd LoRA_Easy_Training_Scripts
git submodule init
git submodule update
cd sd_scripts
pip install torch torchvision --extra-index-url https://download.pytorch.org/whl/cu116
pip install --upgrade -r requirements.txt
pip install -U xformers
- 设置加速选项
accelerate config
#依序回答:
#- This machine
#- No distributed training
#- NO
#- NO
#- NO
#- all
#- fp16
- LoRA的训练数据目录结构不太一样,需创建目录结构如下。已经上好提示词的训练数据要放在
img_dir下面,将目录名称取名为数字_概念,目录名称前面加上数字代表要重复的步数。
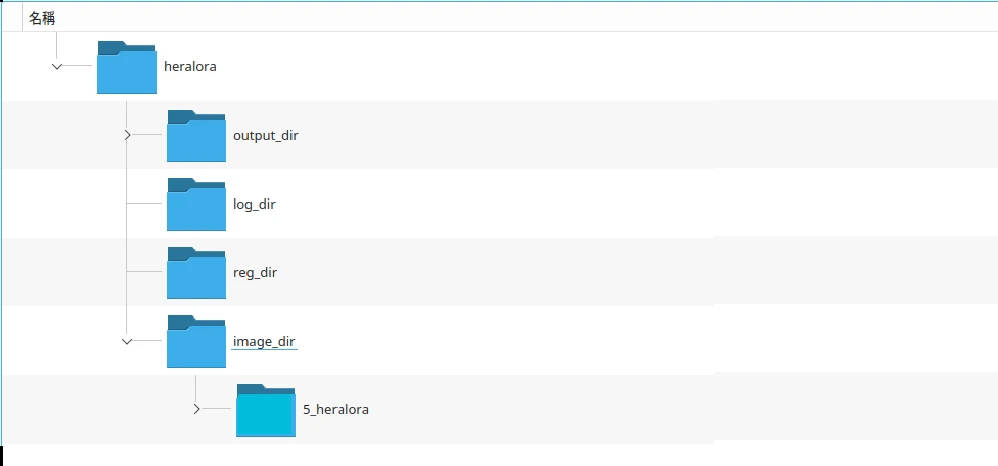
- 添加训练设置档
trainingconfig.json
vim trainingconfig.json
- 填入以下内容(双斜线的注解记得删除) LoRA的总训练步数计算公式为: 训练图片数量 × 重复次数 ÷ train_batch_size × epoch
{
//基于何种模型训练
"pretrained_model_name_or_path": "/home/user/桌面/heralora/anything-v4.5-pruned.ckpt",
"v2": false,
"v_parameterization": false,
//纪录档输出目录
"logging_dir": "/home/user/桌面/heralora/log_dir/",
//训练数据目录
"train_data_dir": "/home/user/桌面/heralora/image_dir/",
//注册目录
"reg_data_dir": "/home/user/桌面/heralora/reg_dir/",
//输出目录
"output_dir": "/home/user/桌面/heralora/output_dir",
//训练的图片最大长宽
"max_resolution": "512,512",
//学习率
"learning_rate": "1e-5",
"lr_scheduler": "constant_with_warmup",
"lr_warmup": "5",
"train_batch_size": 3,
//训练时期
"epoch": "4",
"save_every_n_epochs": "",
"mixed_precision": "fp16",
"save_precision": "fp16",
"seed": "",
"num_cpu_threads_per_process": 32,
"cache_latents": true,
"caption_extension": ".txt",
"enable_bucket": true,
"gradient_checkpointing": false,
"full_fp16": false,
"no_token_padding": false,
"stop_text_encoder_training": 0,
"use_8bit_adam": true,
"xformers": true,
"save_model_as": "safetensors",
"shuffle_caption": true,
"save_state": false,
"resume": "",
"prior_loss_weight": 1.0,
"text_encoder_lr": "1.5e-5",
"unet_lr": "1.5e-4",
"network_dim": 128,
"lora_network_weights": "",
"color_aug": false,
"flip_aug": false,
"clip_skip": 2,
"mem_eff_attn": false,
"output_name": "",
"model_list": "",
"max_token_length": "150",
"max_train_epochs": "",
"max_data_loader_n_workers": "",
"network_alpha": 128,
"training_comment": "",
"keep_tokens": 2,
"lr_scheduler_num_cycles": "",
"lr_scheduler_power": "",
"persistent_data_loader_workers": true,
"bucket_no_upscale": true,
"random_crop": false,
"caption_dropout_every_n_epochs": 0.0,
"caption_dropout_rate": 0
}
2. 开始训练 #
- 有些系统需要指定CUDA安装路径
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
- 输入以下指令,加载json设置档。
libnvinfer.so.7: cannot open shared object file的警告可以暂时忽略。
accelerate launch main.py --load_json_path "/home/user/trainingconfig.json"
- 之后会自动开始训练。训练好的模型位于训练设置档所写的
output_dir目录。将.safetensors档移动至SD WebUI根目录下的/models/Lora。
3. LoRA模型使用方式 #
- 点击SD WebUI右上角,Show extra networks
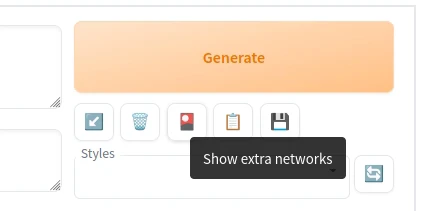
- 点击要使用的LoRA,将其加入至提示词字段
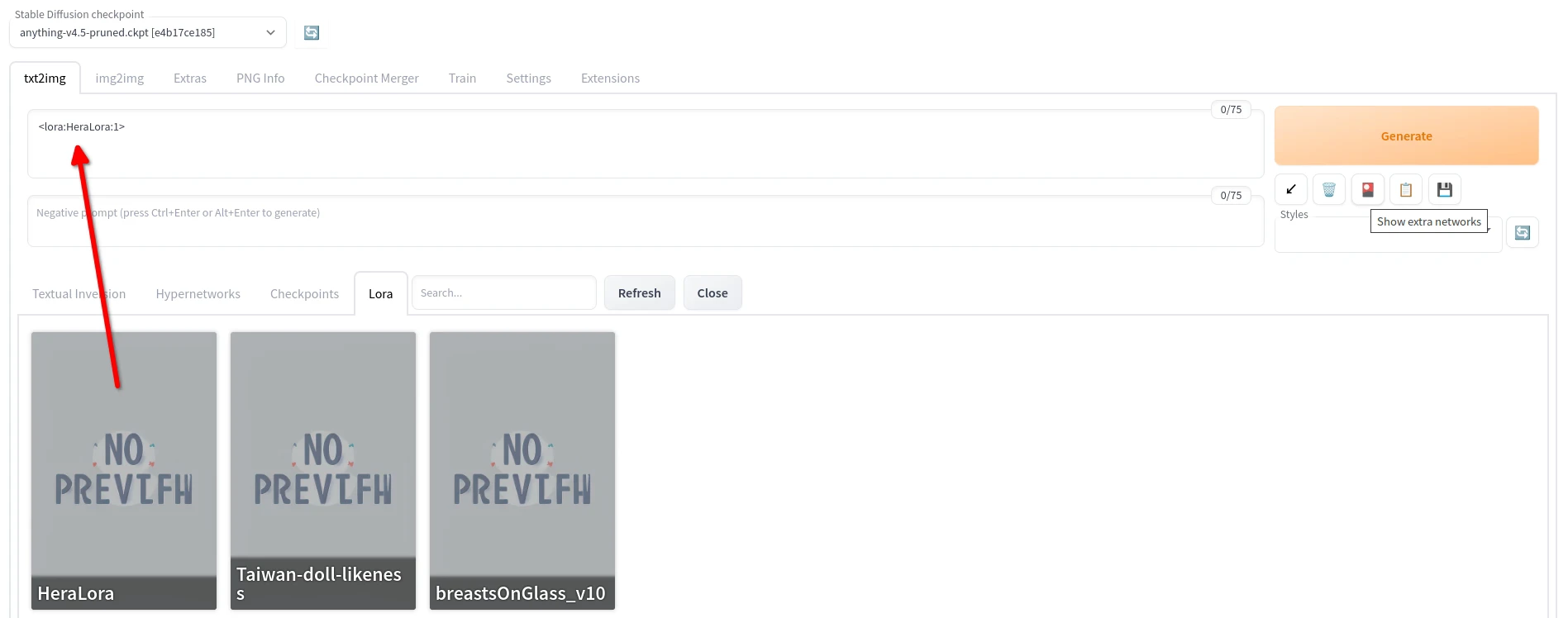
- 再加上训练时使用的提示词,即可生成使用LoRA风格的人物。