本章所讨论的训练模型仅为自用用途,若要分享训练的模型也应遵照开源的原则分享。
为什么要训练自己的模型?训练自己的模型可以在现有模型的基础上,让AI懂得如何更精确生成/生成特定的风格、概念、角色、姿势、对象。
举例来说,如果喂给AI十几张我精挑细选的「Hara老师绘制的、不同角度、FGO的斯卡萨哈」做训练,那么就能让AI更懂得如何生成斯卡萨哈的脸部,风格也会比较固定。
以下是一个具体例子,通过使用自行训练的HyperNetwork,便改善单靠Anything模型无法生成出Hara老师画风的缺点。在不使用HyperNetwork的情况下,风格永远是左边那样;一使用HyperNetwork,右边的风格就能轻松生成出来了。

训练模型是复杂的议题,基于哪个现有模型,以及喂给AI学习的图片品质,还有训练时的参数,都会影响模型训练结果。
本文提及的Embedding、HyperNetwork、LoRA都是「小模型」,这是相对于网络动辄好几GB的checkpoint「大模型」而言。这些小模型训练时间短,文件约几MB而已,训练成本不高。主要是用于生成特定人物/对象/画风,并且训练的模型可以多个混用。
如果硬件条件许可的话,搜集大量图片训练特定领域的checkpoint大模型,再上传到HuggingFace造福他人也是不错的选项,只不过此任务过于庞大。要知道Stable Diffusion 1.5版的模型可是输入了23亿张图片训练出来的!网络上其他人训练的模型至少也准备了几万张图片。因此要生成特定的人物/对象/画风,训练小模型对一般人来说比较划算。
各个模型的原理差异请参考下图。技术原理以及训练参数设置请参阅「参考数据」一章,碍于篇幅无法一一细讲,本章以操作过程为主。
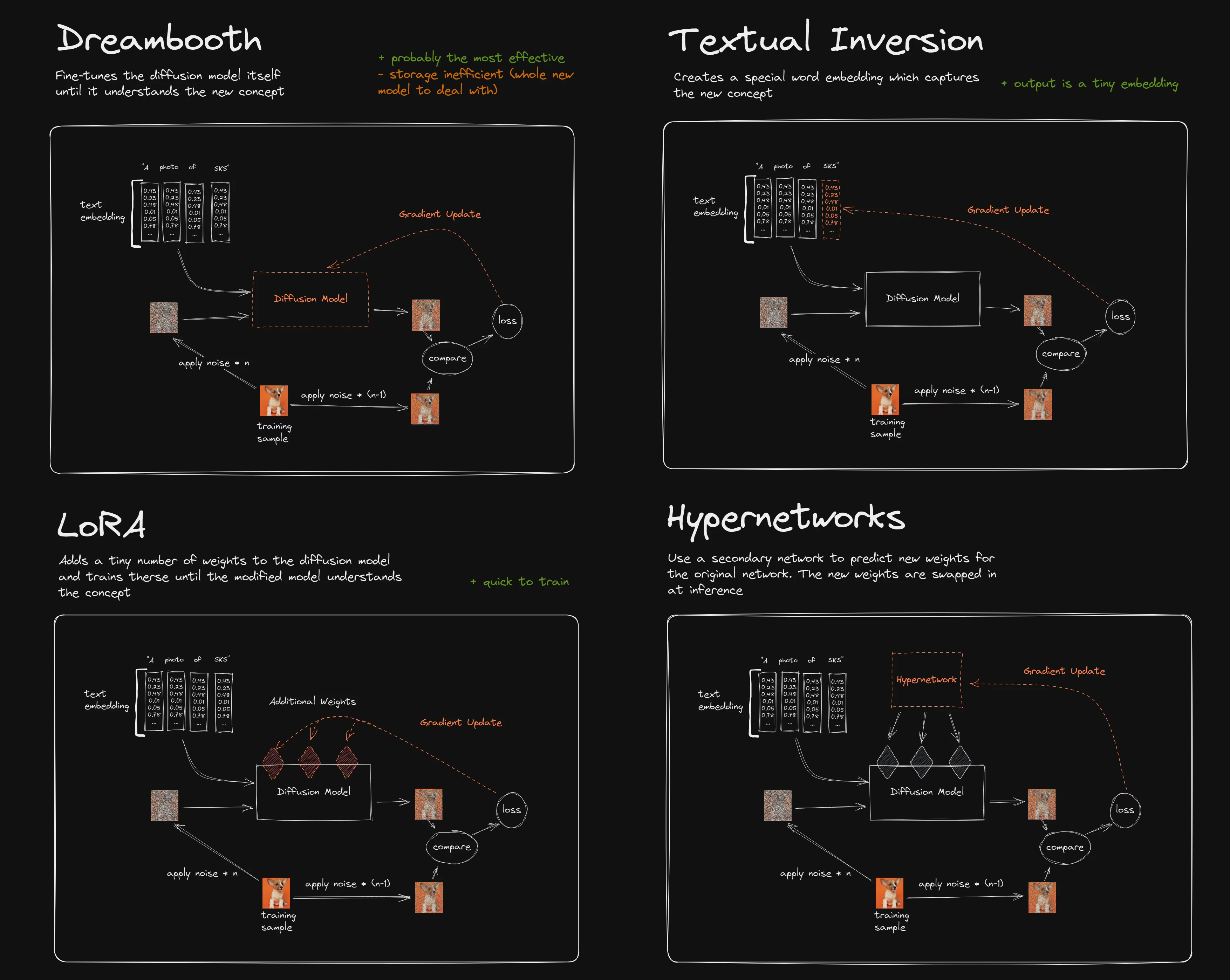
就训练时间与实用度而言,目前应是 LoRA > HyperNetwork > Embedding
本章节以AUTOMATIC1111开发的Stable Diffusion WebUI为中心撰写,因其图形化且好操作。后面简称SD WebUI。
接着选择部署在本机或是云端?
训练模型至少需要10GB的VRAM,也就是RTX3060等级以上的GPU。
如果你有Nvidia RTX3060以上等级的GPU,那就参考 安装教学部署在本机,想训练多久就训练多久。训练数据不到50张图片的小模型训练时间约只要1~3个小时。
如果没有强力的GPU,那就用云端训练,例如 Google Colab。