1. 取得高品質圖片 #
訓練用的圖片最少最少要準備10張。重質不重量。因為我要訓練的是單一人物且風格固定,圖片不宜有複雜背景以及其他無關人物。
網路圖片一張一張右鍵下載當然可以,不過要大量下載圖片的話我會使用Imgrd Grabber或Hydrus Network。
這裡我準備了33張Hara繪製的斯卡薩哈
2. 裁切圖片 #
下載圖片後,要將訓練圖片裁切成512x512像素。你可以選擇用SD WebUI自動裁切,或是手動裁切。
2.1. 自動裁切 #
裁切圖片不會用到顯示卡計算。
-
將要裁切的圖片放到同一個目錄下,例如
/home/user/桌面/input。 -
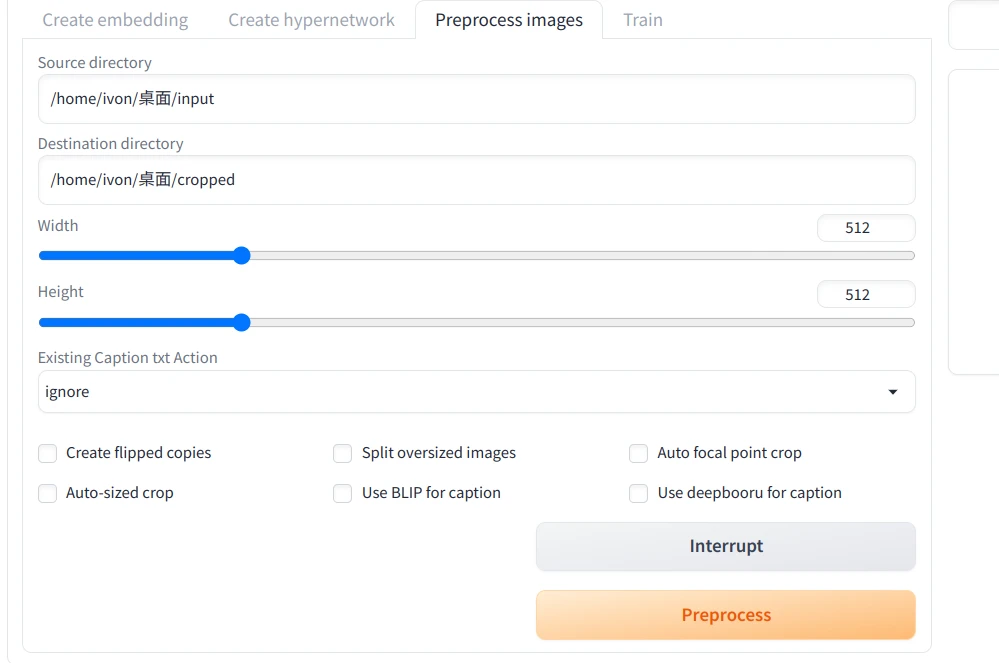
開啟SD WebUI,進到Train → Preprocess images頁面
-
第一個欄位
Source directory填寫原始圖片的路徑 -
第二個欄位
Destination directory填寫輸出路徑,例如/home/user/桌面/cropped -
Width和Height設定為512x512
-
點選Preprocess ,圖片即會自動裁切。在那之後原始圖片就可以刪除,只留下裁切後的圖片。
2.2. 手動裁切 #
手動把圖片轉成512x512理由是避免重要的部分被裁掉。
-
安裝修圖軟體GIMP,點選檔案→新增512x512像素的專案
-
點油漆桶將其漆成白色
-
將圖片拖曳進畫面,成為新的圖層
-
點選工具→變形工具→縮放,縮放圖片使其符合目前畫布大小,再按Enter。
-
點選檔案→Export,匯出成png。
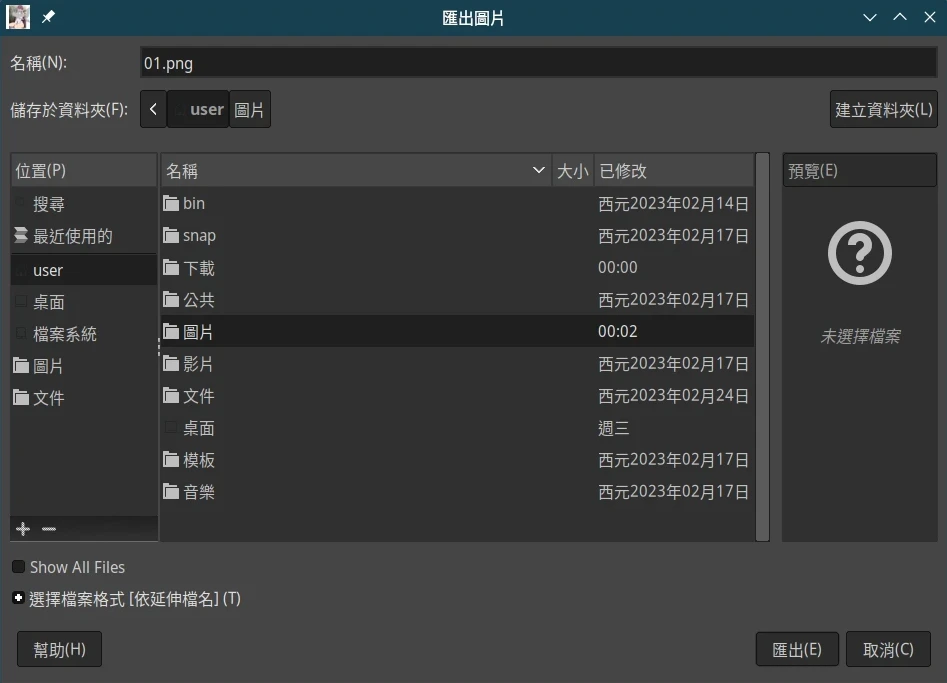
-
為加快後面圖片的處理速度,按右下角刪除目前圖層,再拖新的圖片進來,重複操作。
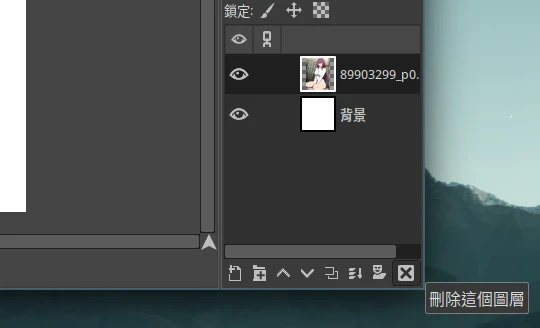
-
將33張Hara繪製的斯卡薩哈裁切後,統一放到名為
raw的目錄。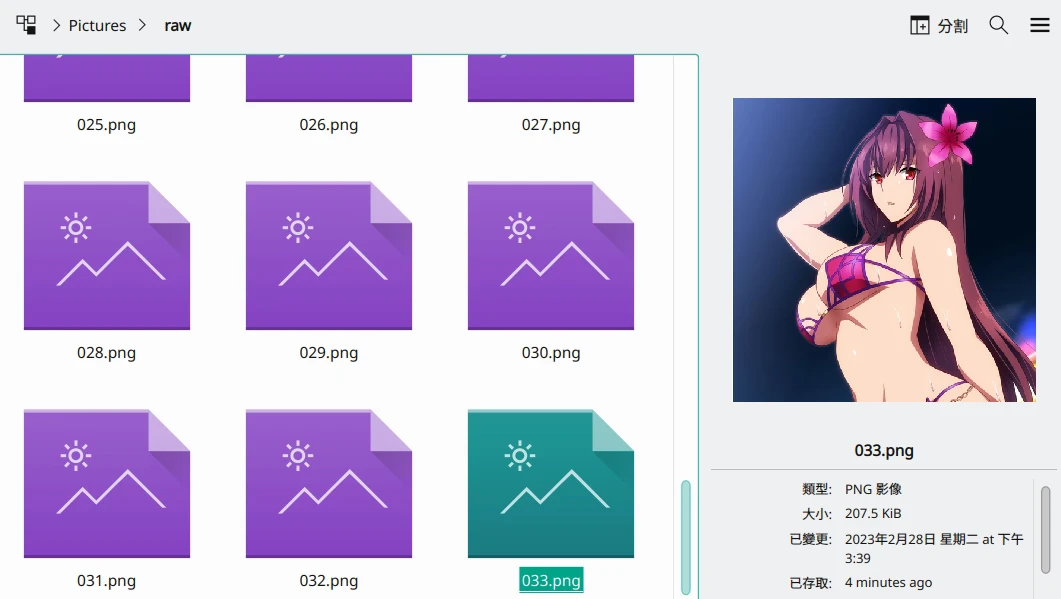
3. 預先給圖片上提示詞 #
接著要給圖片預先上提示詞,這樣AI才知道要學習哪些提示詞。
-
啟動SD WebUI,進入Train頁面。
-
進入Preprocess頁面,
Source輸入裁切圖片的路徑,Destination填處理後圖片輸出的路徑。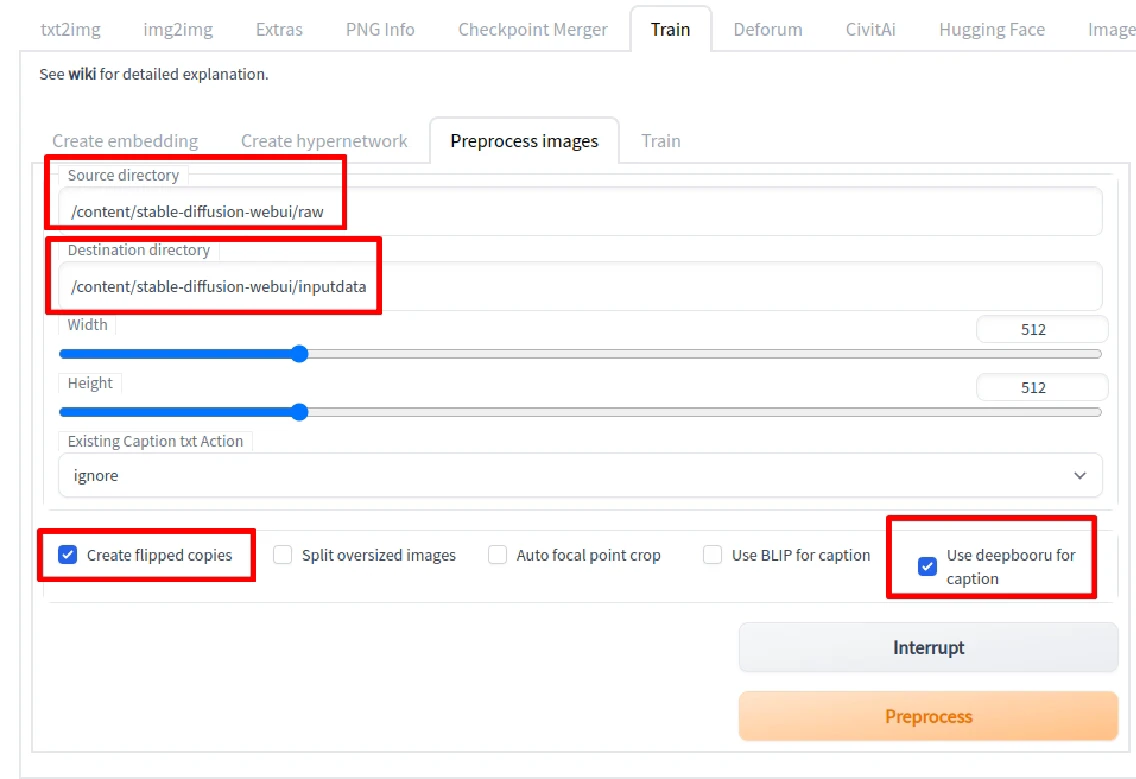
-
接著勾選
Create Flipped Copies,建立翻轉圖片提升訓練數量。
然後用Stable Diffusion訓練真實圖片的勾選Use BLIP for caption;訓練動漫人物改勾選Use DeepBooru for caption。
-
點選Preprocess,約幾分鐘後便會處理完成。輸出的目錄裡面會含有每張圖片對應的提示詞txt檔。
-
點選開啟txt檔,將你覺得無關的特徵都刪除,例如
2girls這類太籠統的提示詞。 -
至此訓練資料準備完成。