本章所討論的訓練模型僅為自用用途,若要分享訓練的模型也應遵照開源的原則分享。
為什麼要訓練自己的模型?訓練自己的模型可以在現有模型的基礎上,讓AI懂得如何更精確生成/生成特定的風格、概念、角色、姿勢、物件。
舉例來說,如果餵給AI十幾張我精挑細選的「Hara老師繪製的、不同角度、FGO的斯卡薩哈」做訓練,那麼就能讓AI更懂得如何生成斯卡薩哈的臉部,風格也會比較固定。
以下是一個具體例子,透過使用自行訓練的HyperNetwork,便改善單靠Anything模型無法生成出Hara老師畫風的缺點。在不使用HyperNetwork的情況下,風格永遠是左邊那樣;一使用HyperNetwork,右邊的風格就能輕鬆生成出來了。

訓練模型是複雜的議題,基於哪個現有模型,以及餵給AI學習的圖片品質,還有訓練時的參數,都會影響模型訓練結果。
本文提及的Embedding、HyperNetwork、LoRA都是「小模型」,這是相對於網路動輒好幾GB的checkpoint「大模型」而言。這些小模型訓練時間短,檔案約幾MB而已,訓練成本不高。主要是用於生成特定人物/物件/畫風,並且訓練的模型可以多個混用。
如果硬體條件許可的話,蒐集大量圖片訓練特定領域的checkpoint大模型,再上傳到HuggingFace造福他人也是不錯的選項,只不過此任務過於龐大。要知道Stable Diffusion 1.5版的模型可是輸入了23億張圖片訓練出來的!網路上其他人訓練的模型至少也準備了幾萬張圖片。因此要生成特定的人物/物件/畫風,訓練小模型對一般人來說比較划算。
各個模型的原理差異請參考下圖。技術原理以及訓練參數設定請參閱「參考資料」一章,礙於篇幅無法一一細講,本章以操作過程為主。
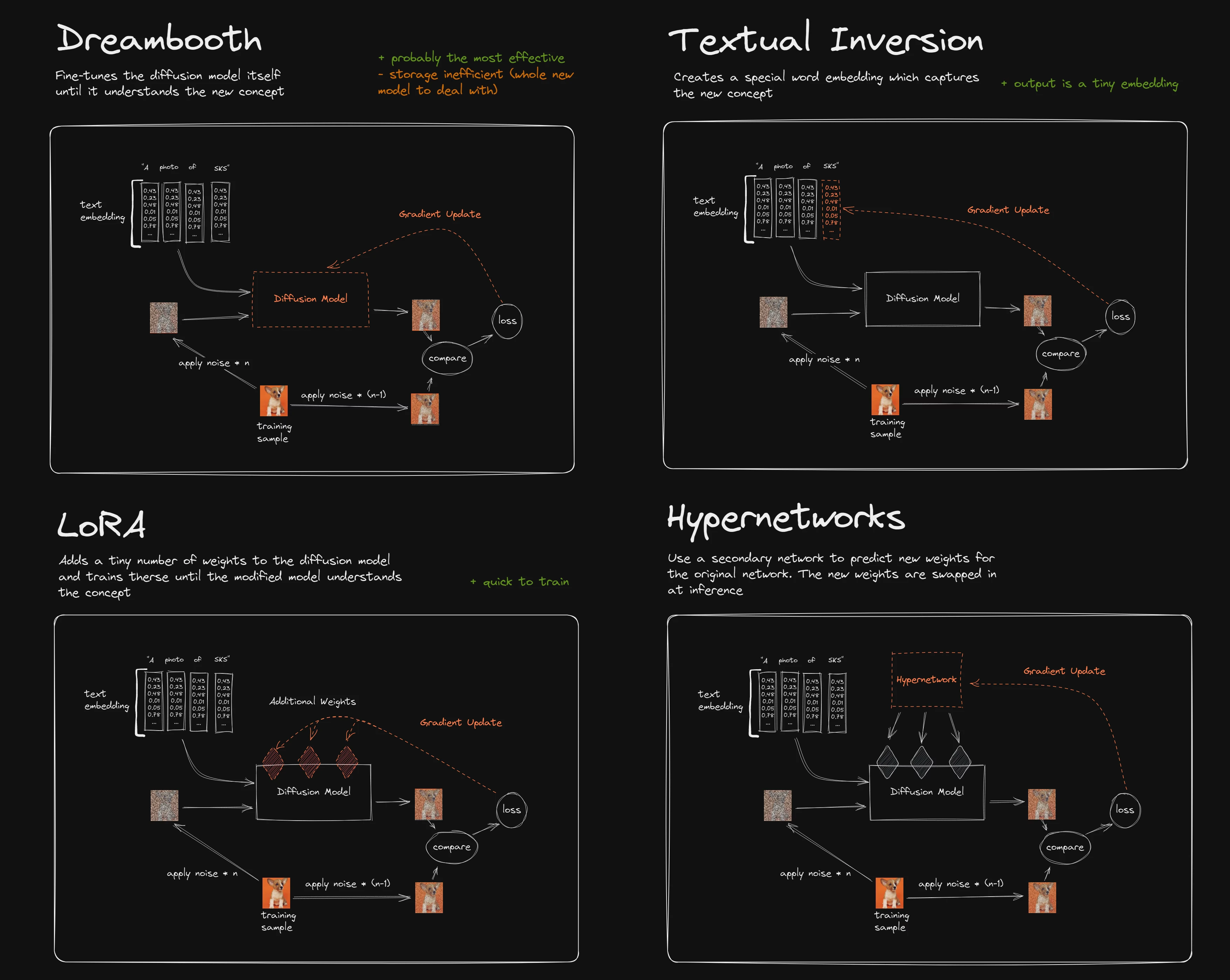
就訓練時間與實用度而言,目前應是 LoRA > HyperNetwork > Embedding
本章節以AUTOMATIC1111開發的Stable Diffusion WebUI為中心撰寫,因其圖形化且好操作。後面簡稱SD WebUI。
接著選擇部署在本機或是雲端?
訓練模型至少需要10GB的VRAM,也就是RTX3060等級以上的GPU。
如果你有Nvidia RTX3060以上等級的GPU,那就參考本系列安裝教學將Stable Diffusion WebUI部署在本機,想訓練多久就訓練多久。訓練資料不到50張圖片的小模型訓練時間約只要1~3個小時。
如果沒有強力的GPU,那就用雲端訓練,例如Google Colab。