網路上有一堆線上PDF轉檔工具,只要上傳檔案就會吐出處理好的檔案讓你下載,可是有隱私資安的疑慮。那麼你有沒有想過自己架設一個PDF處理服務呢?
以Ivon的使用例來說,有時臨時想在iPad轉檔PDF文件,雖然市面上有很多APP能辦到,但是我想要使用自由開源的方案,那麼就只剩網頁處理的路子了。為追求開源軟體,以及確保隱私不讓PDF文件被其他網站濫用,我就找到了「Stirling PDF」,這款簡單易用的PDF轉檔工具。

這款軟體支援Linux、Windows、macOS系統,提供桌面版,開箱即用。
你也可以利用Docker部署網頁版,把Stirling PDF架在NAS,就能夠透過瀏覽器遠端處理PDF文件了。
根據Stirling PDF的開發者在Product Hunt的頁面,他們說想解決依賴線上PDF處理服務的問題,不想使用可疑網站提供的轉檔服務,所以開發了這個大補帖軟體,一次滿足所有需求。

Striling PDF功能為何?除了基本的PDF閱讀器之外,合併PDF、分割PDF、調整PDF對比度、PDF新增浮水印、批次PDF重新命名、OCR抽取PDF文字、PDF轉圖片、PDF轉Word、圖片轉PDF的功能樣樣有。還可以自訂pipeline,使用固定程序處理大量的PDF。
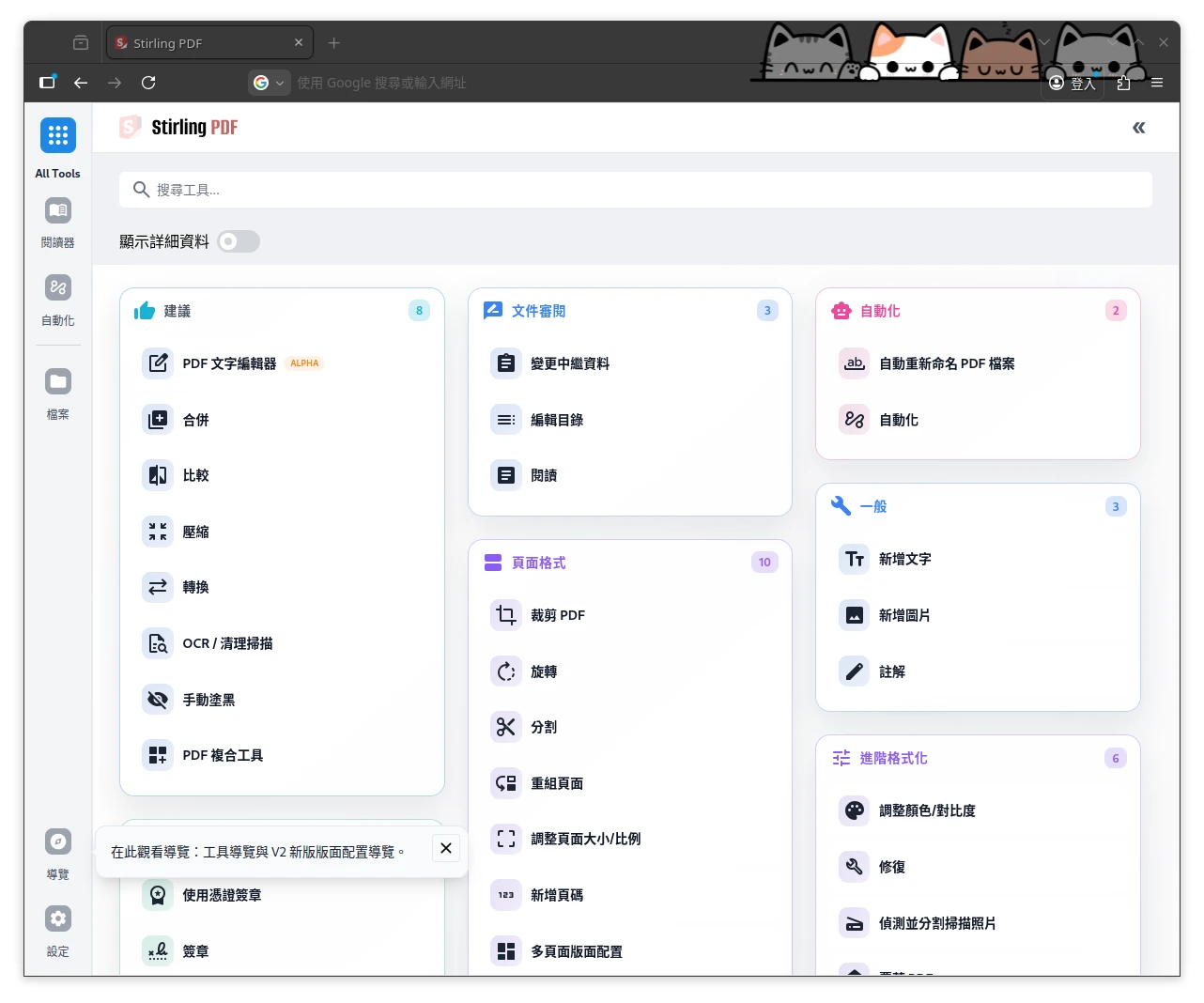
這是1.0的界面,Stirling PDF所有功能都顯示在首頁。Stirling PDF原本是大補帖式的編輯處理軟體,目的在於開發出一款完全開放原始碼的PDF處理軟體,替代網路上許多可疑的PDF轉檔網站,所以一開始的界面長的很土。

2.0之後,原本大補帖的操作界面現代化,Stirling PDF的界面變得更像一款專業的PDF編輯工具了。使用者能夠更加直覺的編輯多份PDF文件,並提供雲端儲存PDF的功能。這使得它成為LibreOffice Draw與Adobe Acrobat以外的替代品選擇。
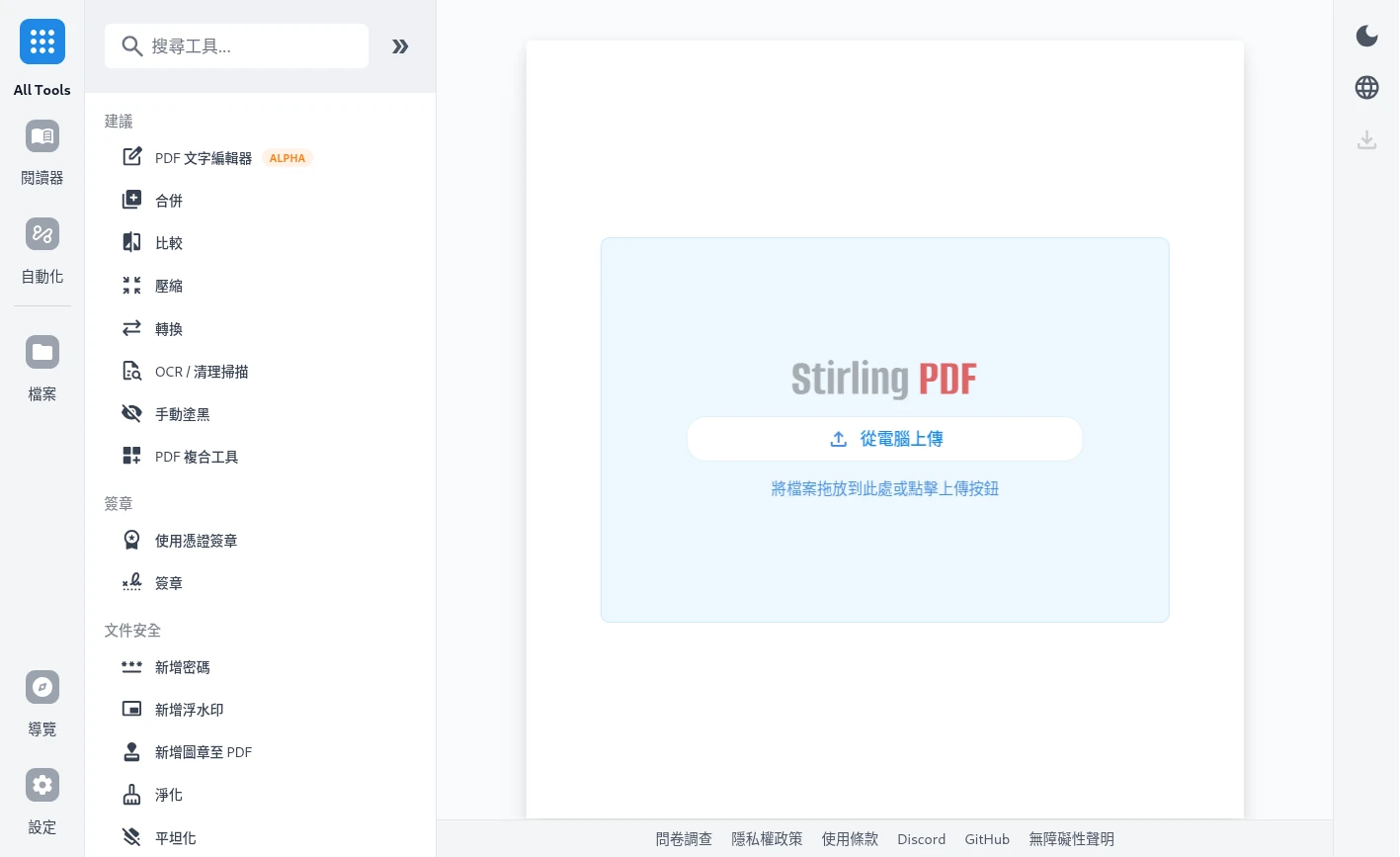
就像你在網路上看到的那些線上PDF轉檔工具一樣,Stirling PDF的設計宗旨就是簡單易用,一個頁面一個功能。基本上只要上傳檔案,勾你要處理的選項,它就會自動完成作業,然後吐出檔案讓你下載。
Ivon認為Stirling PDF適合搭配同為自架服務的Nextcloud和Paperless使用,一同為無紙化的辦公室工作流努力~
1. Striling PDF的安裝方式 #
詳細使用說明請參閱開發者的Github。
桌面版 #
Stirling PDF是用Java寫的,集合了許多開源專案的PDF處理工具。
開發者提供封裝好的桌面版,請到Github Releases下載打包好的客戶端。
Linux下載.deb檔安裝,Windows下載.msi,macOS下載.dmg檔,點二下開啟即會自動開啟界面。
這個版本需要登入帳號才可以使用,離線使用全部免費,要使用雲端儲存功能的要付費。
Docker版 #
如果你想要隨時隨地存取這個服務,推薦用Docker部署網頁版,比較好管理,也方便遠端存取。
這個版本不需要註冊帳號就能用,上傳的檔案就只會保管在你的伺服器。
- 新增docker-compose.yml
mkdir ~/stirlingpdf
cd ~/stirlingpdf
vim docker-compose.yml- 參考官方文件,填入以下內容:
services:
stirling-pdf:
image: stirlingtools/stirling-pdf:latest
ports:
- '8080:8080' # 冒號左邊是對外暴露的通訊埠
volumes:
- ./trainingData:/usr/share/tessdata # OCR套件位置
- ./extraConfigs:/configs # 設定檔
environment:
- DOCKER_ENABLE_SECURITY=false
- INSTALL_BOOK_AND_ADVANCED_HTML_OPS=true # 安裝全部功能
- LANGS=zh_TW # 界面語言
restart: unless-stopped- 啟動容器服務。在瀏覽器開啟
http://127.0.0.1:8080進入網頁界面。
docker compose up -d- 若要讓網頁界面從外部網路存取,請使用內網穿透方案。
2. Striling PDF使用教學 #
這…功能太多了,講不完啊XD
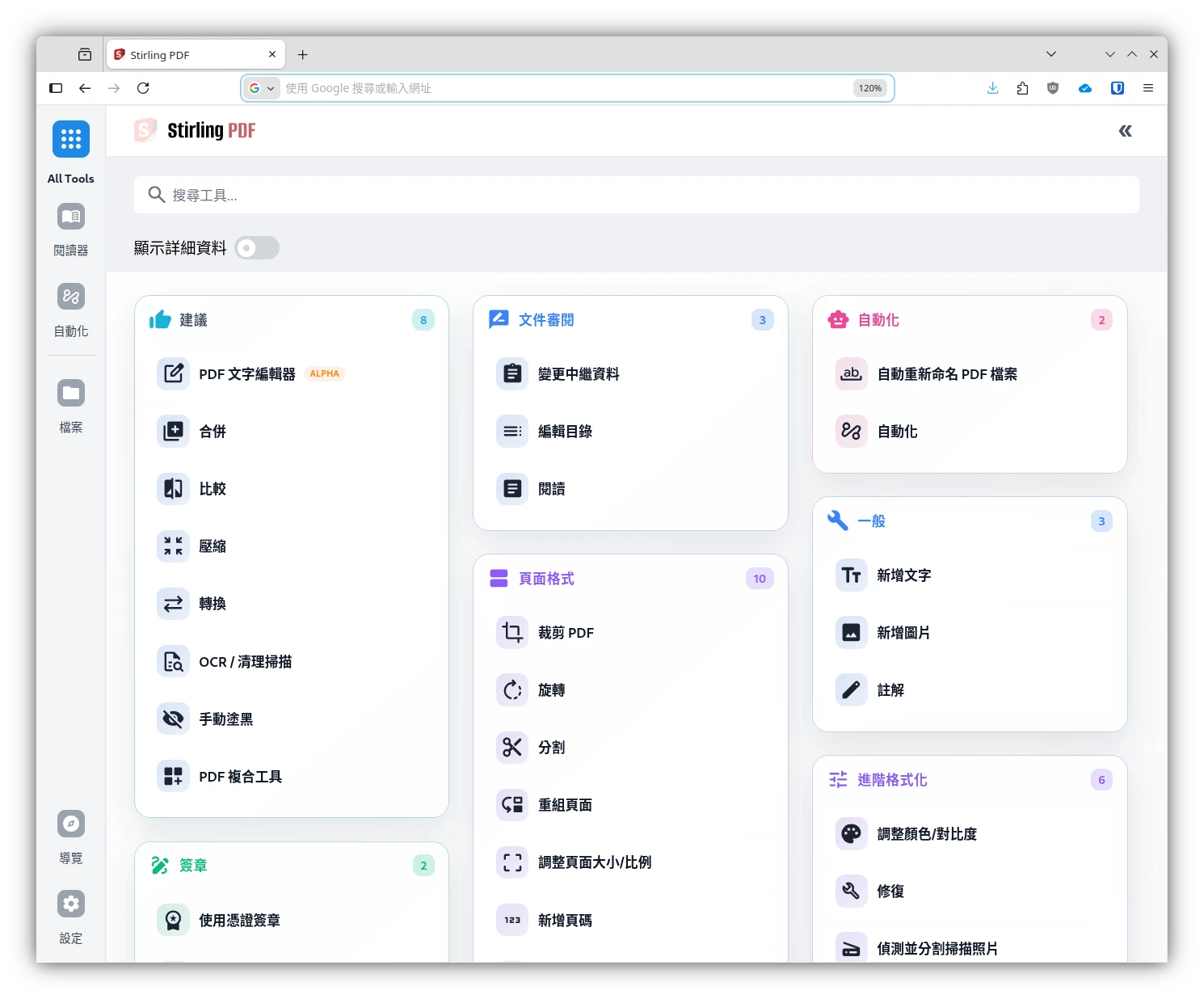
基本上首頁的選單就說明了每個頁面的功能。
如果你想要打開網頁就能找到所有功能,點一下左上角All Tools,展開選單。
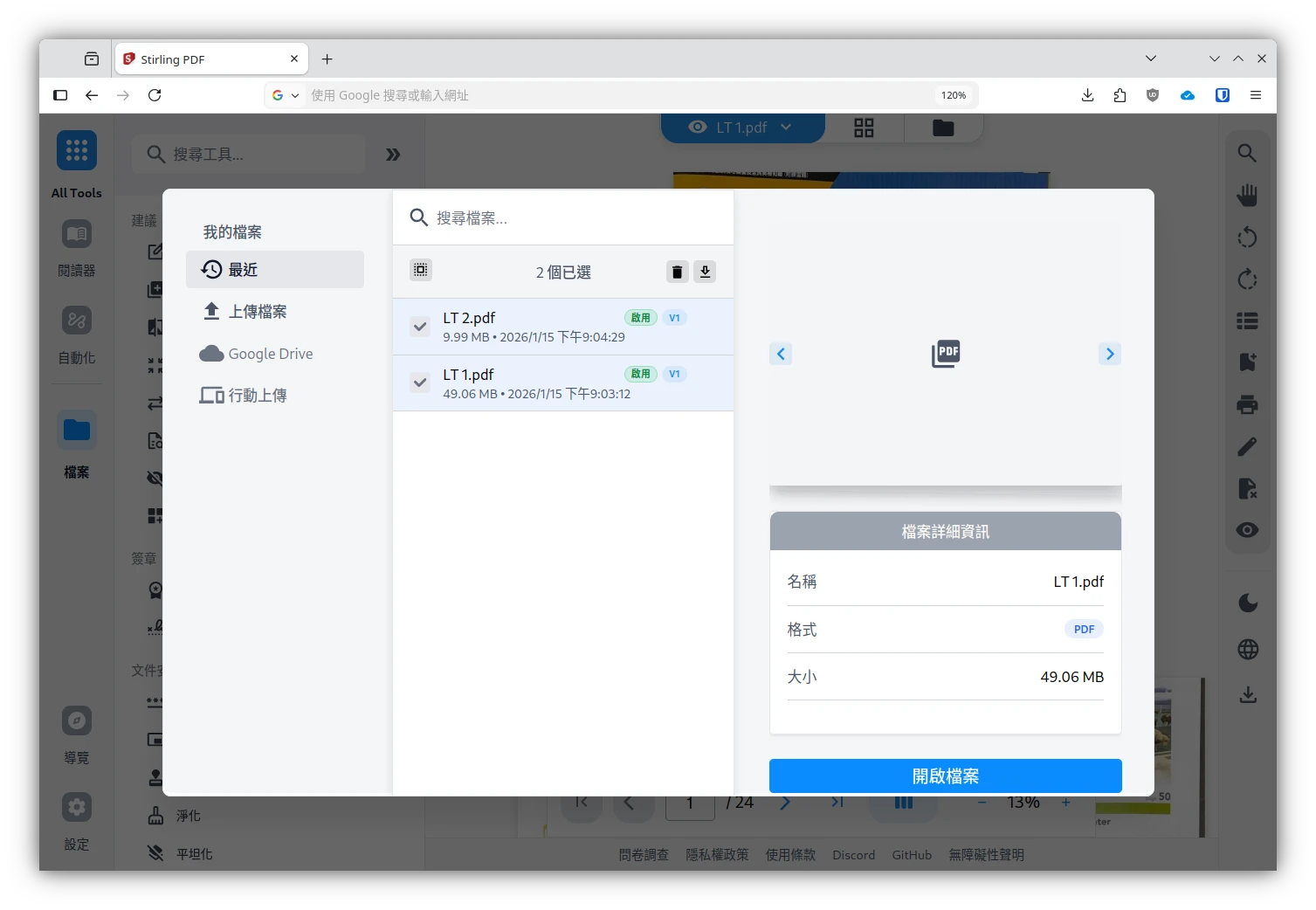
點左邊的「檔案」,上傳或打開PDF文件。再點進去依照畫面指示操作就好。
值得一提的是「PDF複合工具」,它能夠上傳多份PDF文件,並在網頁界面重排頁面順序(點一下上方的PDF檔案列表),再合併輸出為新PDF文件。註:如果你在檔案選取框無法上傳.pdf以外格式的檔案,就統一先上傳到文件介面上傳所有檔案再進行合併操作。
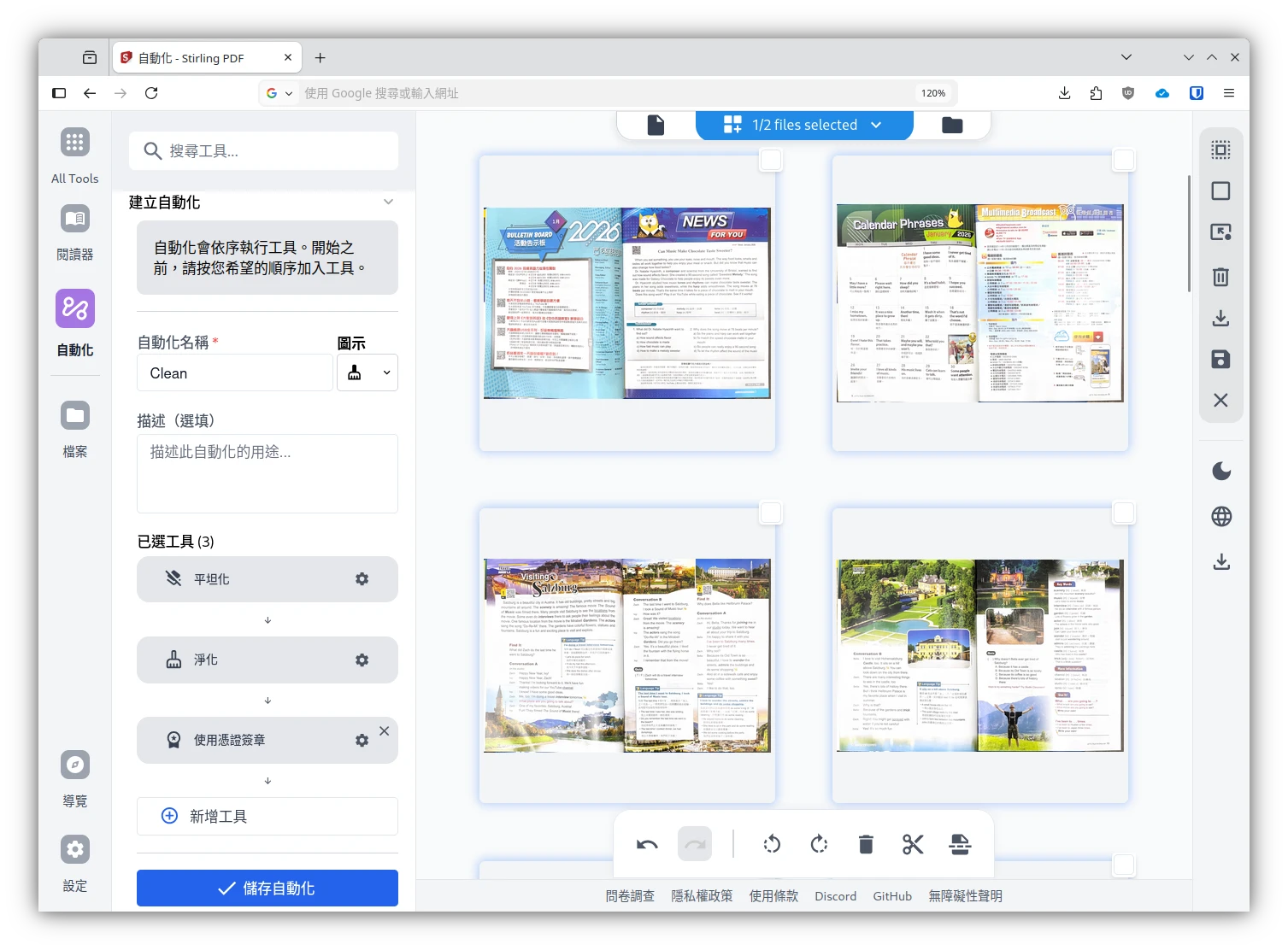
還有這個「自動化」功能,它能夠依照你定義的一系列操作,批次處理每個上傳的PDF文件。例如設定先平坦化PDF,裁剪PDF,再加上簽名,最後輸出。
關於PDF to Word的轉檔功能:如果輸入輸出為docx與pptx格式,Stirling PDF背後轉檔是使用LibreOffice headless轉換的,對Microsoft Office格式的相容性可能沒辦法盡善盡美,建議輸出格式選取ODF。
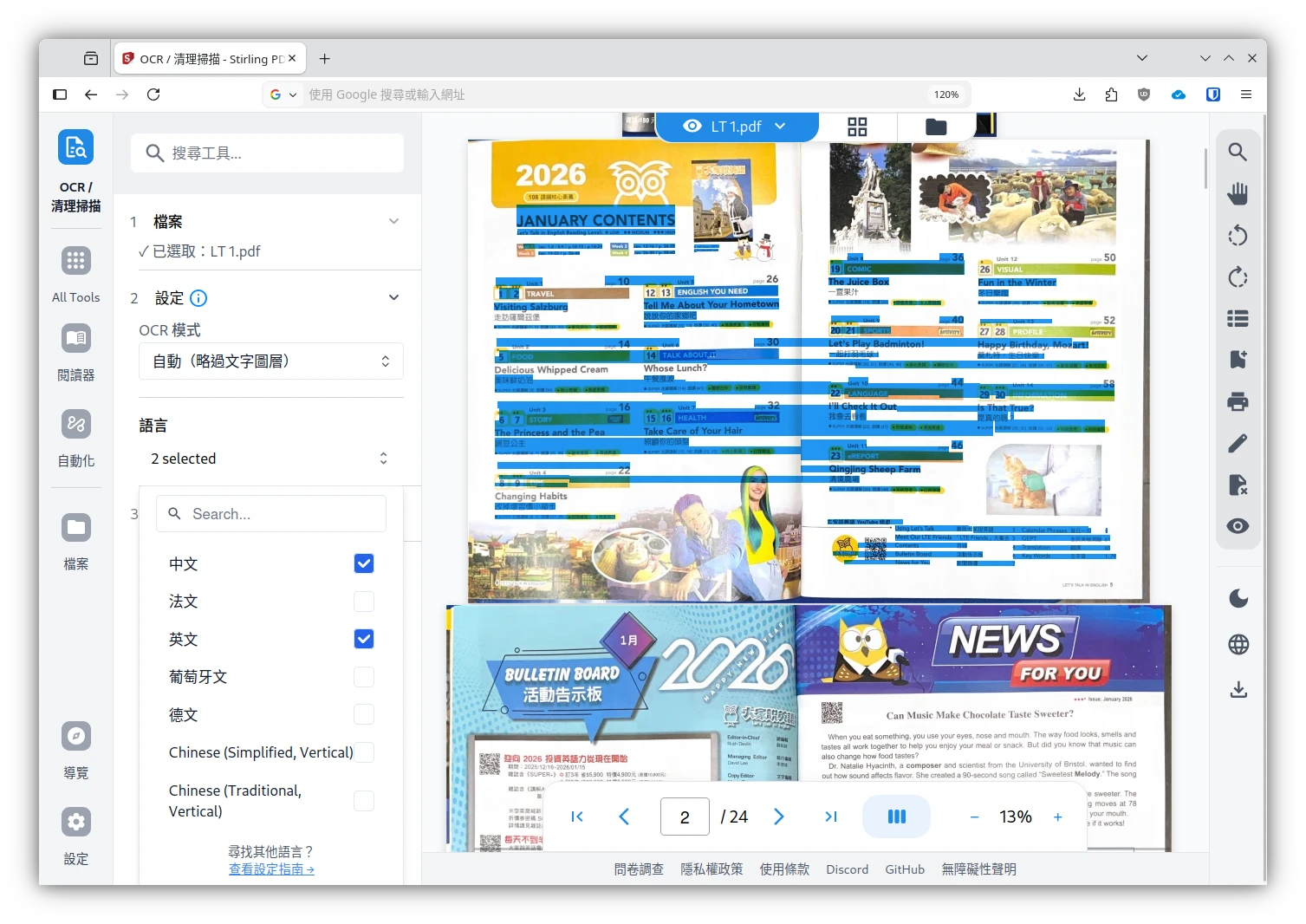
3. Striling PDF啟用中文OCR #
Striling PDF的OCR功能可以讓PDF文件內的手寫文字變成能夠選取的框框。
Striling PDF依賴Tesseract進行OCR。如果使用Docker部署,請到tessdata的Github下載.traindata檔案,放到docker-compose.yml所在目錄的trainingData裡面。
例如我要辨識正體中文和英文,那麼trainingData目錄下應該會有這些檔案:
.
└── trainingData
├── chi_tra.traineddata
├── chi_tra_vert.traineddata
├── eng.traineddata然後在工具 → OCR,勾選要辨識別的語言,上傳檔案,稍待一會,吐出處理過的PDF文件。