Text Generation WebUI擴充功能(extension)可從Session頁面啟用,點選後按Apply and restart Interface。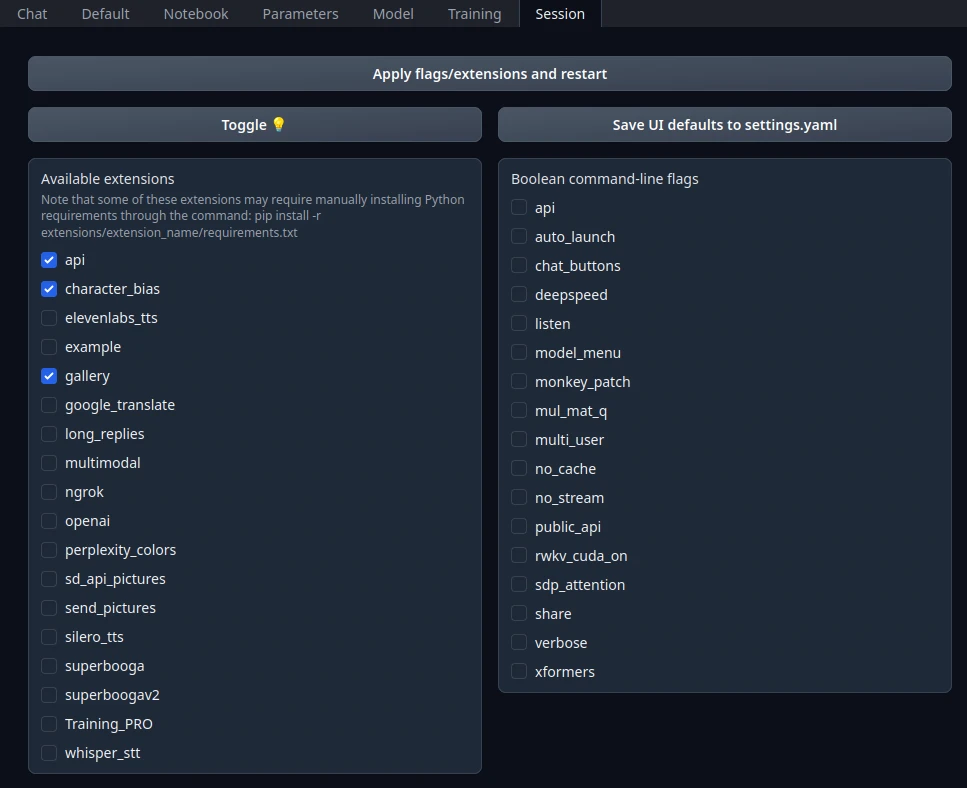
裡面有的功能是需要第三方線上服務token的,請詳細閱讀開發者的說明。
角色扮演#
Text Generation WebUI支援AI角色扮演。
在
characters目錄放入角色名稱.yaml檔案,自訂AI的身份。或者可用網頁界面的"Chat Settings"頁面編輯。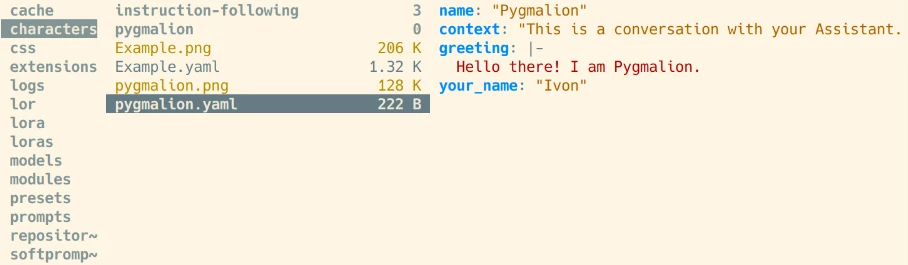
在WebUI的底部點選Character gallery切換角色。
這樣就可以玩角色扮演對話,並且對話紀錄會保留下來。
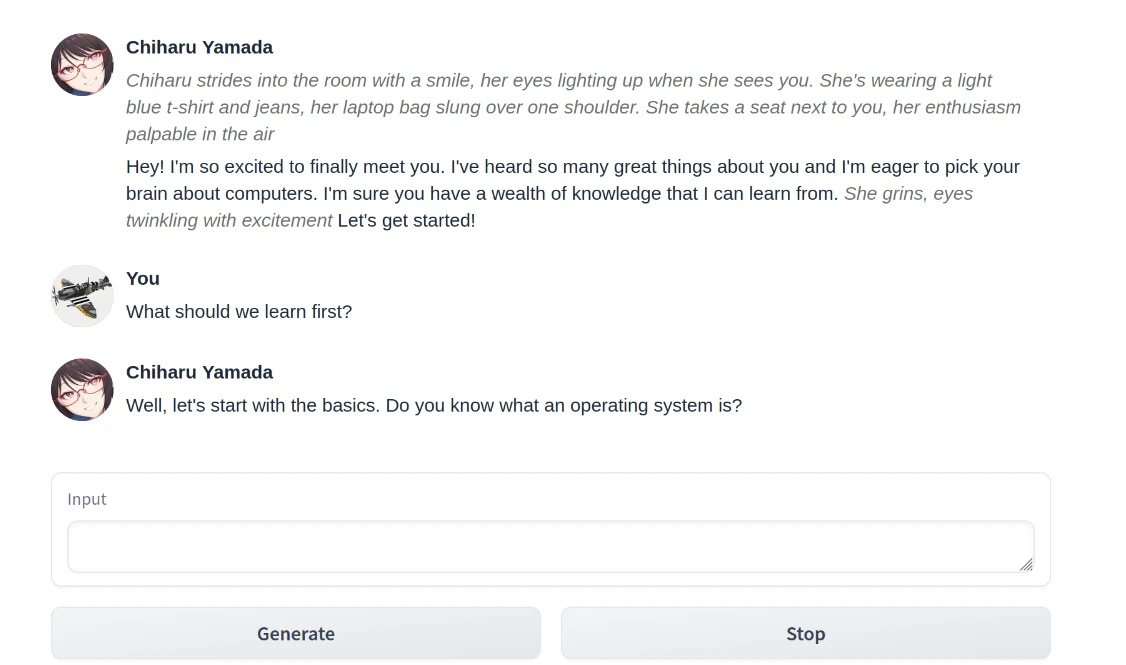
Google翻譯#
啟用擴充功能google_translate_plus,用Google翻譯雙方的對話內容。
眾所周知Google翻譯不是普通的差。反正都要依賴不自由的網路服務,串ChatGPT API幫你翻譯還比較快。
彙整Google搜尋結果#
啟用擴充功能Web_Search,下指令後AI就會搜尋Google並唸出結果。
文字轉語音#
silero_tts:配合Silero這個模型,將對話內容文字轉語音並念出。
長期記憶#
long_term_memory保留AI的對話紀錄。這樣AI擁有記憶,能記得之前談過的內容。
圖片辨識#
send_pictures這個擴充功能讓你上傳圖片給AI,再由AI依據CLIP模型的結果回傳圖片內容的描述文字。
還有LLaVA pipeline,可利用openai/clip-vit-large-patch14辨識圖片,再讓AI描述圖片內容。
用Stable Diffusion繪圖#
類似Microsoft New Bing,叫AI幫你畫一張圖。因為要在一台電腦跑二個需要大量顯卡算力的模型,請確認硬體是否負荷得了。
啟用擴充功能sd_api_pictures,即可在對話的時候,讓AI生成文字配合Stable Diffusion WebUI繪圖。
注意:Text Generation WebUI預設是跟Stable Diffusion WebUI使用相同的7860通訊埠,需要用--listen-port引數將前者變更為其他通訊埠。
在SD WebUI的啟動引數加入
--api,啟動SD WebUI。啟動Text Generation WebUI時加上
--listen-port 7861引數,將通訊埠變更為7861/TCP。在Text Generation WebUI的界面最下方,展開sd_api_pictures的界面,填入SD WebUI的IP和通訊埠,按下Enter檢查連線。
勾選
Immersive Mode,再填入繪圖的提示詞。提示詞欄位只要填基本的品質提示詞即可,剩下的提示詞AI會自動從你的對話代入。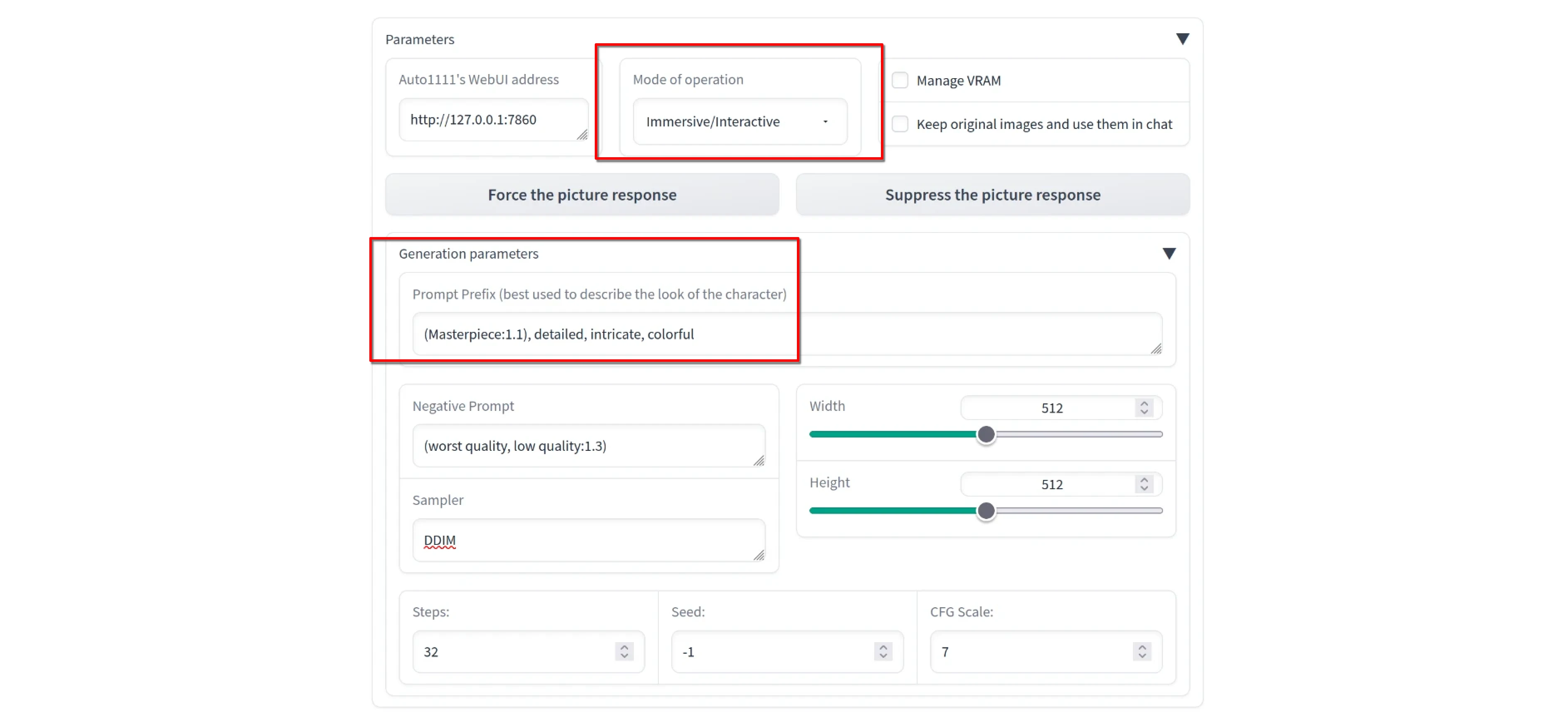
在與AI對話時,填入含有
send|main|message|me加上image|pic|picture|photo|snap|snapshot|selfie|meme的提示詞,即會觸發Stable Diffusion繪圖功能,並回傳圖片。