想要去掉歌聲,製作純音樂的卡啦OK伴唱帶?
想要分離音樂的人聲音軌,方便後續混音?
那就用開源AI軟體UVR吧!![]()
UVR(Ultimate Vocal Remover GUI)為一款跨平台的AI音訊處理軟體,能夠精準地去除音樂的人聲。或者是去除背景噪音,保留人聲。
既然本軟體可以分離出音樂的人聲,反過來,當然也可以單獨分離出背景音樂囉,靠UVR製作伴奏是很好的選擇,甚至能夠把和聲保留下來。
UVR成品範例1:黑豹樂隊 - 靠近我
原始檔
人聲,竇唯的聲音完整分離了出來
伴奏
UVR成品範例2:佐倉綾音 - 華の二水戦
原始檔
人聲,比較高音的部份被錯認為人聲
伴奏
1. 安裝UVR#
UVR是基於Takahashi等人的論文《Multi-scale Multi-band DenseNets for Audio Source Separation》所實作的專案。
處理過程需要用到GPU加速,因此UVR的GPU硬體需求為NVIDIA GTX1060以上顯示卡,VRAM至少6GB。當然你要用CPU算也可以,只不過處理時間就會變成GPU的兩倍以上囉。
UVR目前版本V5.6,提供Windows和macOS執行檔,請至Github下載。
Linux系統得從Python原始碼跑。
以Ubuntu 22.04為例,Nvidia顯示卡用戶請記得安裝CUDA
從套件管理員安裝ffmpeg和Python3 tkinter
sudo apt install ffmpeg python3-tk- 用Anaconda建立Python 3.10.12環境
conda create -n ultimatevocalremovergui python=3.10.12
conda activate ultimatevocalremovergui- 再安裝依賴套件
git clone https://github.com/Anjok07/ultimatevocalremovergui.git
cd ultimatevocalremovergui
# 防止The 'sklearn' PyPI package is deprecated錯誤
export SKLEARN_ALLOW_DEPRECATED_SKLEARN_PACKAGE_INSTALL=true
pip3 install -r requirements.txt
# 防止Could not create GL context錯誤
conda install -c conda-forge libstdcxx-ng- 啟動UVR
python3 UVR.py2. 關於模型的選擇#
點選主畫面的扳手圖示,到Downloads頁面下載模型。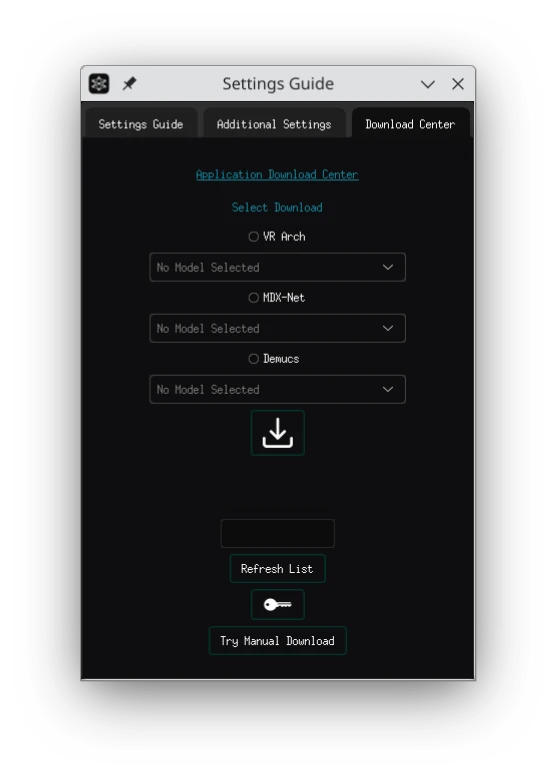
建議先試試「VR Architecture」系列的模型
HP-Vocal-UVR,這個模型可以有效把人聲和音樂分離,強調人聲的使用此模型。
強調音樂品質的請使用HP-UVR
Karaoke模型分離的沒那麼乾淨,音樂會殘留一點人聲的"echo"
Denoise是去除背景噪音的模型。
MDX-Net是更為複雜的模型
Meta發表的Demuc系列模型更是可以按照樂器種類分割出鼓、貝斯的音軌。
UVR尚提供「Ensemble Mode」,合併多種AI模型結果。
3. UVR的操作方式#
先來簡單的去人聲。
如果你要處理的是影片,請先用Handbrake把它轉成純音訊
Select Input選取音訊檔案,Select Output選取輸出目錄(如果要批次處理,你可以選取目錄,這樣它就會處理多個檔案)

CHOOSE PROCESS MODE選取
VR Architecture,下面Model選取要使用的模型,再勾選GPU Processing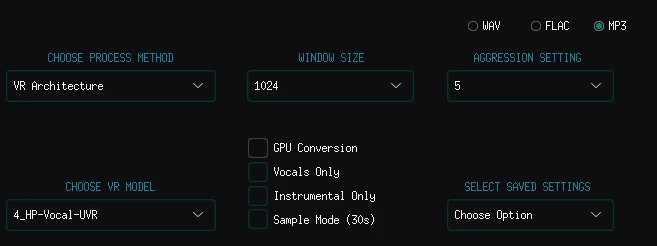
Window Size為轉換品質,維持預設就好。AGREESTION SETING為消除人聲的強度,如果聲音消除不徹底再調高此數值。
接著點選Start Processing
輸出檔案會分成Vocal與Instrumental二個檔案。
根據知乎網友的分享,將多重AI的處理過程合在一起可以得到更好結果。
開啟Emsemble Mode,再勾選Vocals/Instrumental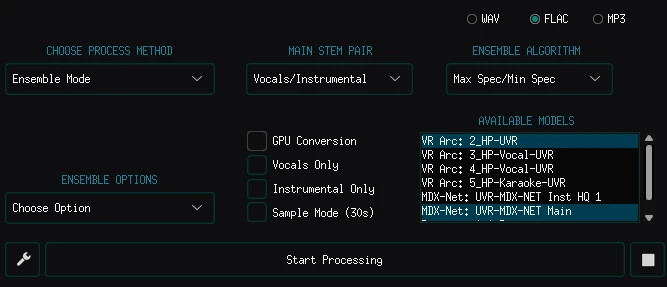
欲抽取最高品質的音樂伴奏:使用「VR 2_HP-UVR + UVR-MDX-Net Main + demucs」四種模型的組合。請在下載對應模型後,點選右邊的模型列表,複選要用的模型,再開始處理檔案。


